第22章:アラート入門:通知は“少なく強く” 🚨📣
この章は「鳴らす」より先に、**鳴らし方で事故る(=アラート疲れ😵💫)**のを避けるのが主役です✨ そして最後に、わざと壊して本当に鳴らすところまでやります💥
① 今日のゴール 🎯

- アラート疲れが起きる理由を説明できる😵💫
- **閾値 + 持続時間(for)**で「ノイズを減らす」感覚を掴む⏳
- Prometheus のルール → Alertmanager の通知まで通す🚨
- そして…わざと壊してアラートを鳴らす😈💥
② 図(1枚)🖼️
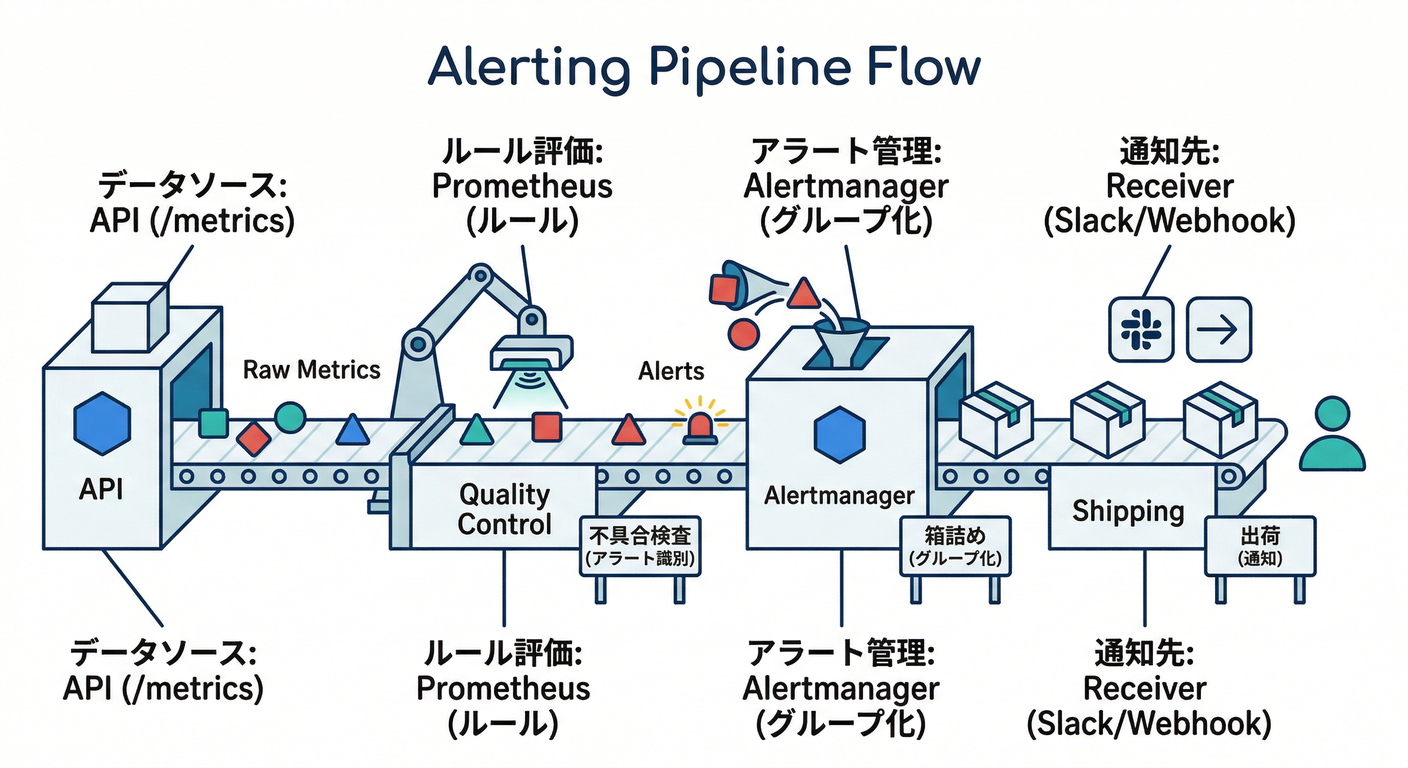
(超ざっくりでOKです😊)
- API が
/metricsを出す 📏 - Prometheus が定期的に取りに行く 🕸️
- ルールに引っかかったら「ALERTS」という時系列が立つ🚩
- Alertmanager が「まとめて・間引いて・通知」する📣
③ まず大事:アラートは“少なく強く”が正義 🥋✨
✅ アラート疲れ(Alert Fatigue)って何?😵💫
-
「鳴りすぎ」→ 人が見なくなる → 本当にヤバい通知も埋もれる 😇
-
原因はだいたいこの3つ👇
- 瞬間スパイクで鳴る⚡
- 同じ原因で大量に鳴る(雪崩)🌨️
- 復旧してるのに何度も来る🔁
④ “ノイズを減らす3点セット” 🧰✨
(A) Prometheus側:for で「続いたら鳴らす」⏳
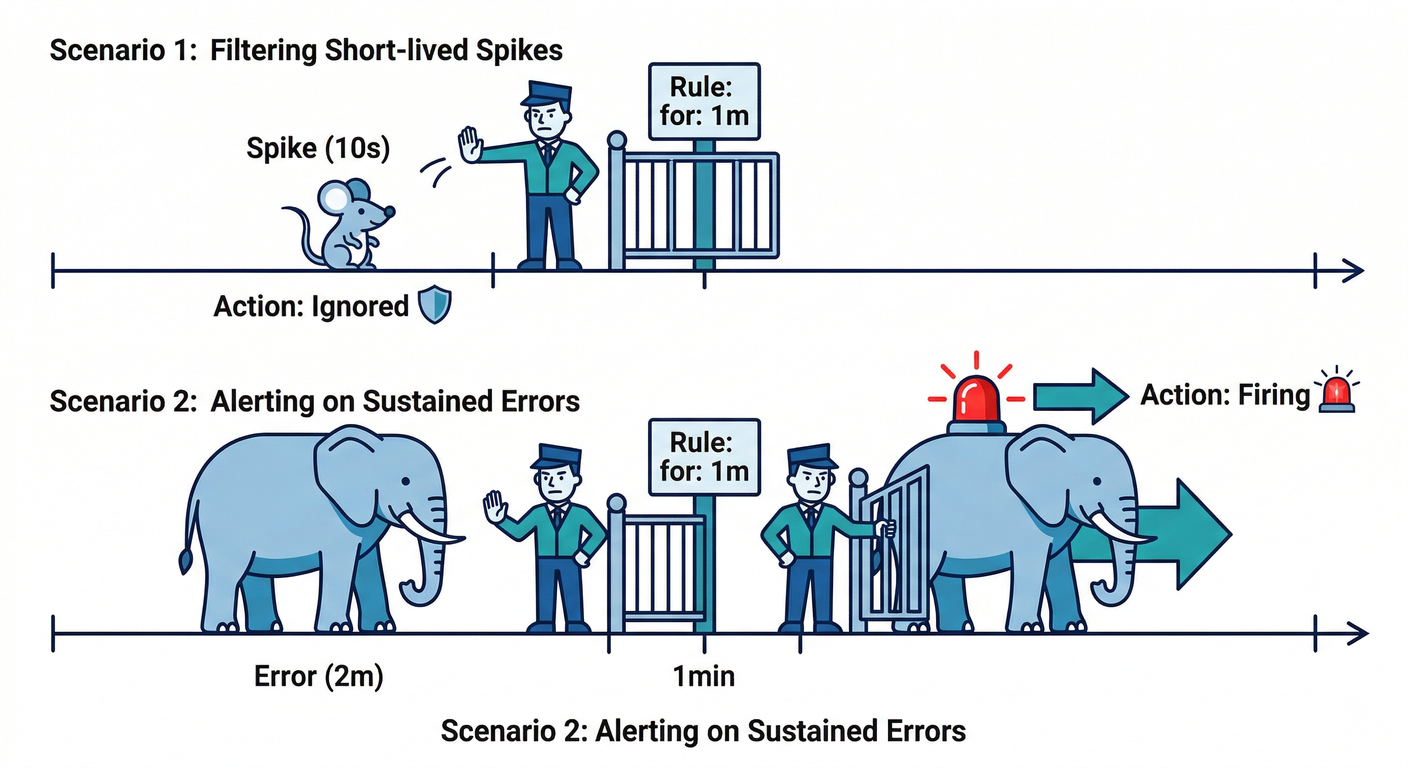
Prometheus のアラートルールは、条件が成立しても 即通知じゃなく
「何分続いたら確定にする?」を for で指定できます。(prometheus.io)
さらに最近の設定では keep_firing_for という「条件が解けても少し鳴らし続ける」オプションもあります(フラップ対策🌀)。(prometheus.io)
(B) Alertmanager側:まとめる&間引く(group_wait / group_interval / repeat_interval)🧺
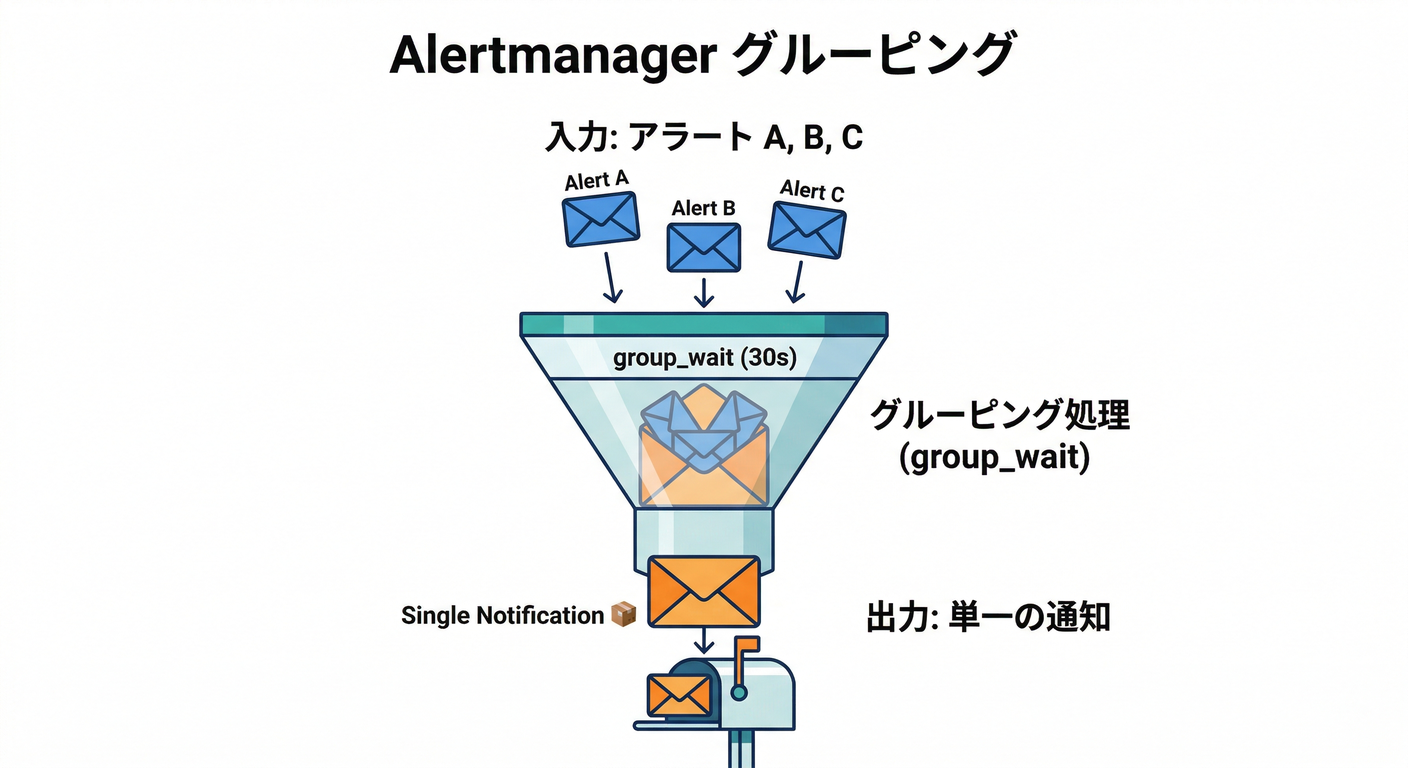
Alertmanager は「通知の出し方」を制御します👇
group_wait:最初の通知を少し待って、同系統をまとめる⏳group_interval:同じグループで追加発生した時の通知間隔🧾repeat_interval:まだ直ってない時に、再通知する間隔🔁
このあたりが “アラート疲れ防止の本体” です🚨🧠 (prometheus.io)
(C) 重要:latest タグ依存は危ない⚠️
特に Prometheus は、Docker の latest タグが「最新メジャー」を指さないケースが話題になっています(3.x を期待してたら 2.x だった、みたいな事故💥)。(Docker Hub)
なので教材では、バージョン固定で進めます🔒
⑤ ハンズオン:アラートを作って、実際に鳴らす 🛠️🚨
🧩 本日時点の固定バージョン(2026-02-13 기준)📌
- Prometheus:v3.9.1(2026-01-07 の最新リリース)(prometheus.io)
- Alertmanager:v0.31.1(直近リリース系列)(GitHub)
- Grafana:Dockerなら 12.3.3 系が提供されています(Docker Hub)
1) ファイル構成 📁
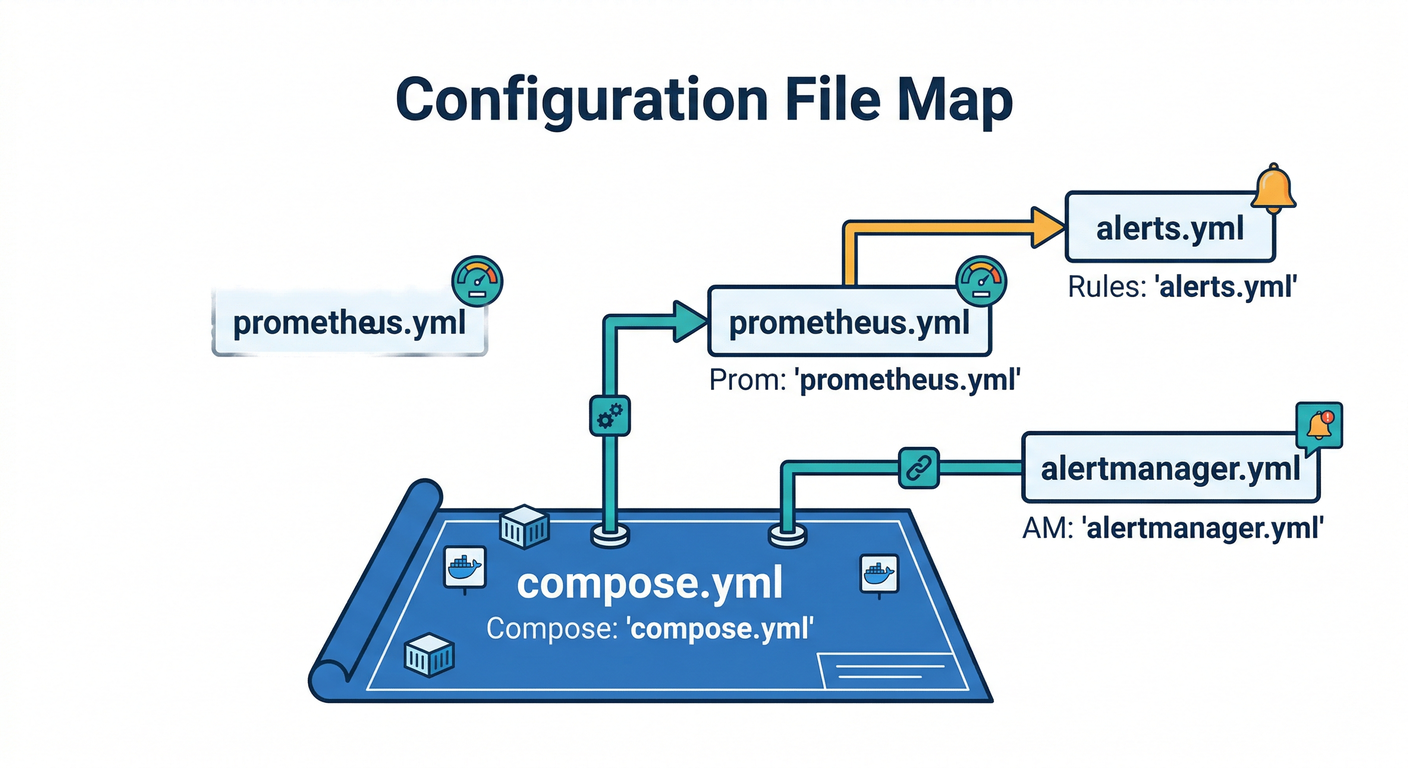
こんな感じに置きます(最小セット)👇
compose.ymlprometheus/prometheus.ymlprometheus/alerts.ymlalertmanager/alertmanager.ymlalert-receiver/server.mjs(通知を受けてログに出すだけのダミー📣)
2) compose.yml(Alertmanager + ダミー通知受け口を追加)🐳
services:
api:
# 既に作ってある想定(第4章〜のミニAPI)
# ports: ["3000:3000"]
# 例: /metrics が生えてる
build: ./api
ports:
- "3000:3000"
prometheus:
image: prom/prometheus:v3.9.1
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml:ro
- ./prometheus/alerts.yml:/etc/prometheus/alerts.yml:ro
command:
- "--config.file=/etc/prometheus/prometheus.yml"
alertmanager:
image: prom/alertmanager:v0.31.1
ports:
- "9093:9093"
volumes:
- ./alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml:ro
command:
- "--config.file=/etc/alertmanager/alertmanager.yml"
grafana:
image: grafana/grafana-enterprise:12.3.3-ubuntu
ports:
- "3001:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
alert-receiver:
image: node:24-alpine
working_dir: /app
volumes:
- ./alert-receiver:/app:ro
command: ["node", "server.mjs"]
ports:
- "18080:18080"
Node 24 は Active LTS 扱いになっています(2026年2月時点)(Node.js)
3) prometheus/prometheus.yml(Alertmanager とルール読み込みを追加)🕸️
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "api"
static_configs:
- targets: ["api:3000"]
rule_files:
- /etc/prometheus/alerts.yml
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:9093"]
4) prometheus/alerts.yml(今回の3本柱アラート)🚨
ポイントはこれ👇
- 落ちてる(up==0):最優先💀
- 5xx率:ユーザー被害に直結🔥
- p95遅延:体感劣化🐢
groups:
- name: api-alerts
interval: 15s
rules:
- alert: ApiInstanceDown
expr: up{job="api"} == 0
for: 30s
labels:
severity: page
annotations:
summary: "APIが落ちてるかも💀"
description: "Prometheusが target を取得できません。instance={{ $labels.instance }}"
- alert: ApiHigh5xxRate
expr: |
(
sum(rate(http_requests_total{job="api", status=~"5.."}[2m]))
/
sum(rate(http_requests_total{job="api"}[2m]))
) > 0.05
for: 2m
labels:
severity: page
annotations:
summary: "5xx率が高い💥"
description: "直近2分の 5xx率 が 5% を超えています。value={{ $value }}"
- alert: ApiHighP95Latency
expr: |
histogram_quantile(
0.95,
sum by (le) (rate(http_request_duration_seconds_bucket{job="api"}[2m]))
) > 0.5
for: 2m
labels:
severity: warn
annotations:
summary: "p95が遅い🐢"
description: "p95 が 0.5s 超。value={{ $value }}"
for を付けるのが超重要です(瞬間スパイクで鳴るのを防ぐ🧯)。(prometheus.io)
⚠️
http_requests_totalやhttp_request_duration_seconds_bucketは、前章までの prom-client で作った名前に合わせてください(名前が違うと鳴りません😇)
5) alertmanager/alertmanager.yml(まとめて、WebHookへ通知)📣
ここが“通知の疲れ止め”本丸です🧠✨
group_by / group_wait / group_interval / repeat_interval で整えると、いきなり快適になります。(prometheus.io)
global:
resolve_timeout: 5m
route:
receiver: "debug-webhook"
group_by: ["alertname", "job"]
group_wait: 30s
group_interval: 2m
repeat_interval: 1h
receivers:
- name: "debug-webhook"
webhook_configs:
- url: "http://alert-receiver:18080/"
send_resolved: true
inhibit_rules:
- source_matchers:
- 'alertname="ApiInstanceDown"'
target_matchers:
- 'job="api"'
equal: ["instance", "job"]
-
inhibit_rulesは「落ちてるなら、遅延や5xxの通知は黙らせる」みたいな 雪崩防止です🌨️🧯 (prometheus.io)
-
古い記事にある
match/match_reより、今はmatchers(または *_matchers)が推奨です📌 (prometheus.io)
6) alert-receiver/server.mjs(通知が来たらログ出すだけ)🧾
import http from "node:http";
const server = http.createServer(async (req, res) => {
if (req.method !== "POST") {
res.writeHead(200);
res.end("ok\n");
return;
}
let body = "";
for await (const chunk of req) body += chunk;
try {
const json = JSON.parse(body || "{}");
console.log("=== ALERT RECEIVED 🚨 ===");
console.log(JSON.stringify(json, null, 2));
} catch (e) {
console.log("=== ALERT RECEIVED (non-json) ===");
console.log(body);
}
res.writeHead(200, { "content-type": "text/plain" });
res.end("received\n");
});
server.listen(18080, () => {
console.log("alert-receiver listening on :18080 📣");
});
⑥ 起動して、画面を開く 👀✨
起動コマンド(PowerShell想定)💻
docker compose up -d
docker compose ps
開くURL(ブラウザ)👇
- Prometheus:
http://localhost:9090 - Alertmanager:
http://localhost:9093 - Grafana:
http://localhost:3001(admin / admin)
Prometheus の「Status → Rules」「Alerts」あたりで、ルールと発火状態が見られます👀 Alertmanager の画面では、発火・解決・サイレンスが見られます🧯
⑦ わざと壊して、鳴らす 😈💥
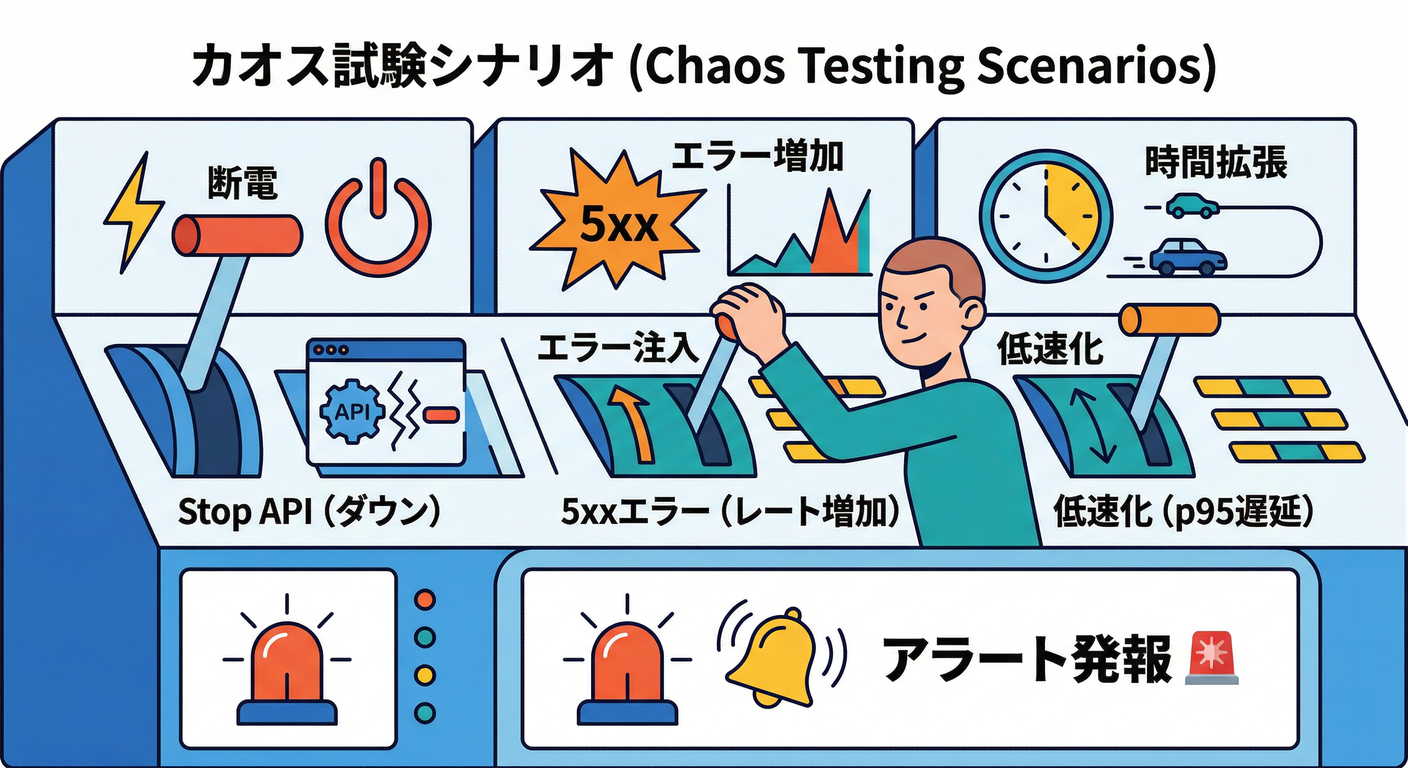
ケース1:APIを止める(InstanceDown)💀
docker compose stop api
30秒くらいで ApiInstanceDown が FIRING になるはずです(for: 30s)⏳
通知ログを見る👇
docker compose logs -f alert-receiver
ケース2:5xx を増やす(ApiHigh5xxRate)💥
APIを起動し直してから👇
docker compose start api
/boom を連打(PowerShellなら curl.exe が安全)👇
1..100 | ForEach-Object { curl.exe -s http://localhost:3000/boom > $null }
ケース3:遅延を増やす(ApiHighP95Latency)🐢
1..80 | ForEach-Object { curl.exe -s http://localhost:3000/slow > $null }
ヒストグラムの p95 は “少し時間をかけて” 反映されるので、2〜3分待つと発火しやすいです⏳🐢
⑧ つまづきポイント(3つ)🪤
-
メトリクス名が違う
http_requests_total/http_request_duration_seconds_bucketの名前・ラベルが一致してるか確認👀
-
トラフィックが少なすぎて比率が不安定
- まずは /ping 連打で母数を作る📈
-
latestで引っ張って事故る- Prometheus は特に注意(さっきの
latest問題)⚠️ (Docker Hub)
- Prometheus は特に注意(さっきの
⑨ ミニ課題(15分)⏳📝
次のどれか1つやってみてください😊
-
“警告(warn)” と “危険(page)” を分ける
- p95 は warn、InstanceDown/5xx は page みたいにする🎚️
-
夜間は通知しない時間帯を作る(time_intervals)🌙
-
「落ちてる時は他を黙らせる」 inhibit をもう1本増やす(例:DB Down が来たらAPI系を黙らせる)🧯
⑩ AIに投げるプロンプト例(コピペOK)🤖📋
- 「このメトリクス一覧から、最小のアラート3つを提案して。条件は
閾値 + forでノイズ最小に。severity も付けて」 - 「この PromQL を、低トラフィックでも暴れにくい式に直して(ゼロ割/NaN対策も)」
- 「Alertmanager の route を、warn はまとめて1時間に1回、page は即通知、みたいに分岐したい。設定例ちょうだい」
おまけ(今どき注意メモ)📌
Alertmanager は v1 API が削除されていて、古い記事の /api/v1/... はハマりがちです(今は v2)。(GitHub)
次の章(第23章)は、ここで作ったアラートとダッシュボードを「毎日3分で見る」運用ルーチンに落としていきます🧹📅✨