データの扱い(永続化・初期化・バックアップ):30章アウトライン📦🧠
(内容は公式ドキュメント中心に、2026年2月11日現在の情報を踏まえています。(Docker Documentation))
1. データって何?まず「守る/捨てる」を仕分けよう🧹🗂️
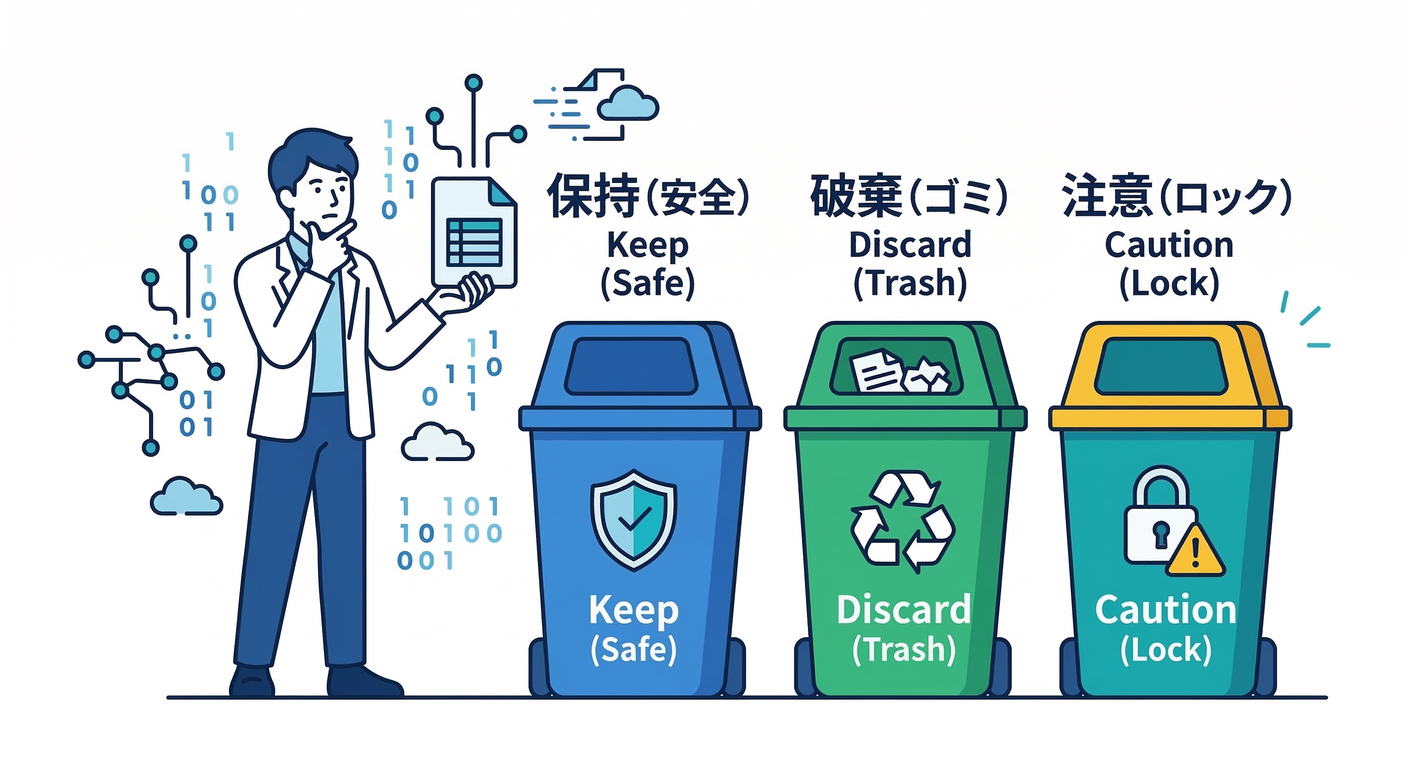
- やること:設定・ソース・DB・キャッシュ・ログを分類
- 成果物:プロジェクトの「データ分類メモ」📝
- AI:分類をコピペして「消していい/ダメ判定の理由もつけて」って聞く🤖
2. “永続化”の3兄弟:bind / volume / tmpfs をざっくり掴む👪
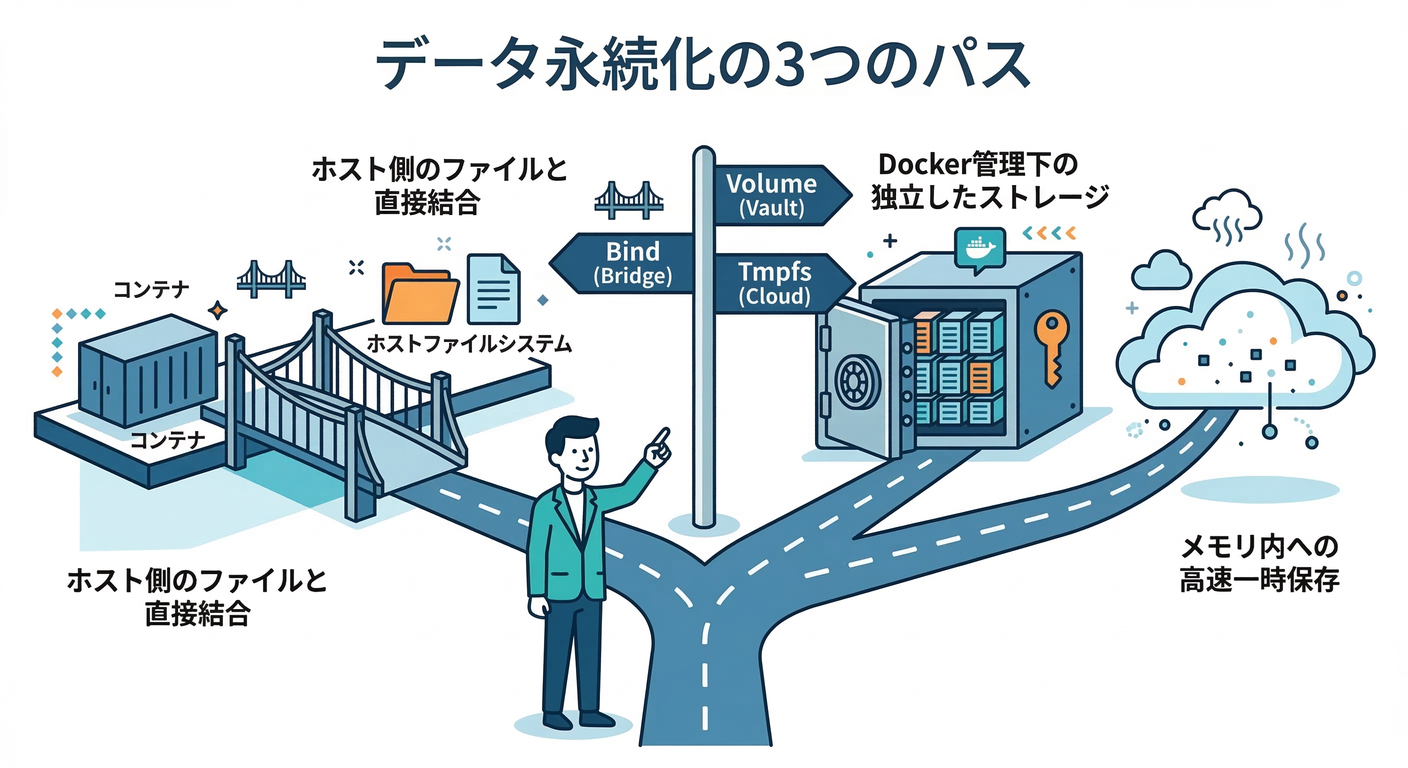
- やること:使い分けの直感(開発・本番・一時)を作る
- 成果物:自分用チートシート📌
- 重要ポイント:bind mountはホストのフォルダをそのまま載せる、volumeはDockerが管理する永続領域。(Docker Documentation)
3. 事故る前に知る:マウントが「上書き」になる話🫠
- やること:マウント先に既にあるファイルが隠れるパターン
- 成果物:事故例メモ(「どこが消えた?」)🧯
- AI:ログと構成を投げて「原因候補3つ」出させる🤖
4. Composeで“データ箱”を定義する(named volume入門)📦
- やること:
volumes:(トップレベル)の意味、サービスからの参照 - 成果物:DB用 named volume を持つ compose 🧩
- 参考:Composeのvolume定義は公式リファレンスが分かりやすい。(Docker Documentation)
5. 「volume名が思ったのと違う」問題を先に潰す😇
- やること:Composeのプロジェクト名とvolume名の関係を理解
- 成果物:
docker volume lsで“自分のvolume”を見つける練習🔎
6. データの置き場所を“図”で描けるようにする🗺️
- やること:ホスト / コンテナ / volume の対応図
- 成果物:1枚図(手書きでもOK)✍️
- AI:構成を渡して「図にするならどう描く?」って聞く🤖
7. DBコンテナの“データディレクトリ”ってどこ?(例:Postgres)🐘
- やること:DBが永続化するパスの意味
- 成果物:DB用volumeマウントの宣言✅
8. 初期化の基本:初回だけ動く“entrypoint初期化”の正体🎬
- やること:初回起動だけ走る初期化の流れ
- 成果物:初期化のタイミング表🗓️
9. 初期化の王道:docker-entrypoint-initdb.d でDBに種を入れる🌱
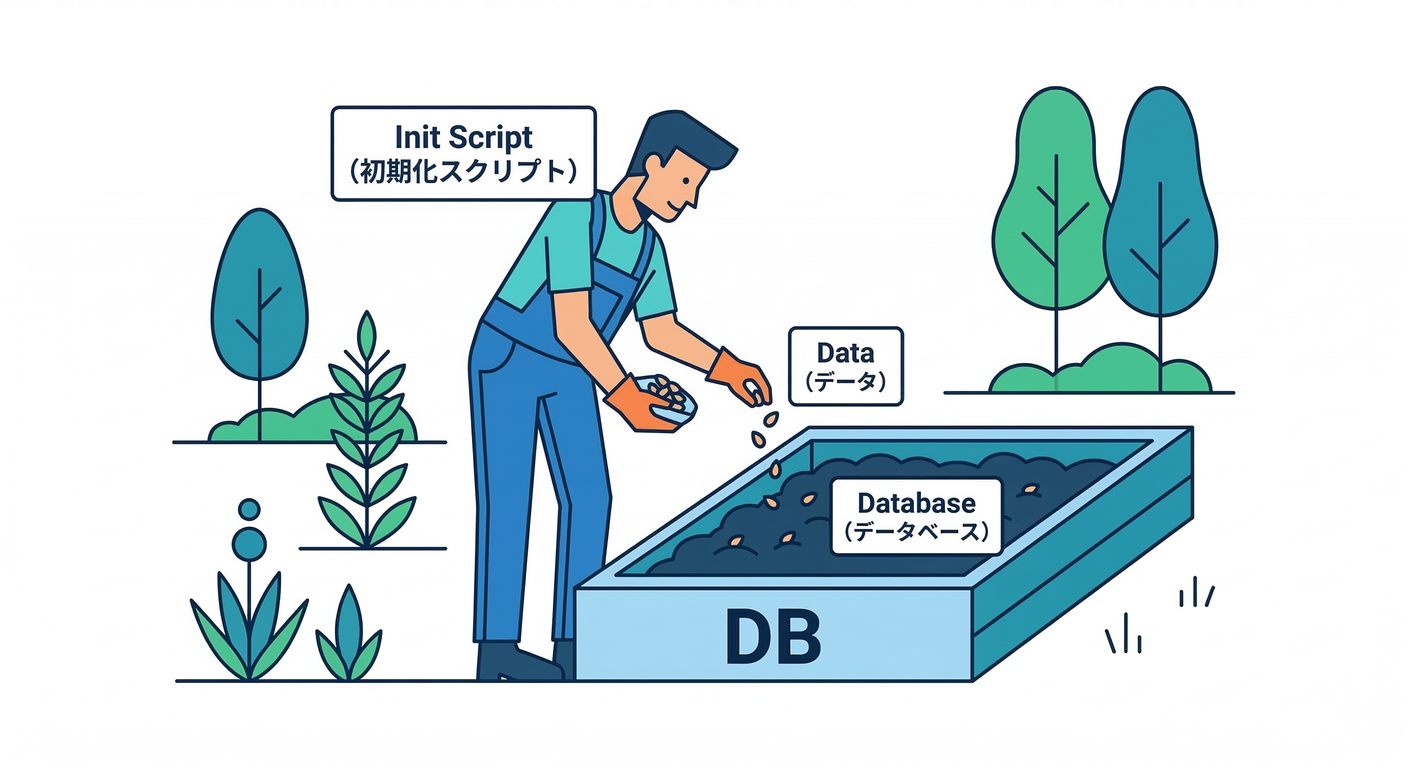
- やること:SQL/シェルで初期データ・ユーザー・スキーマ作成
- 成果物:
init/フォルダ(SQL + README)📁 - 参考:Postgres公式イメージは
docker-entrypoint-initdb.dをサポート。(Docker Hub)
10. 「初期化スクリプトが2回目に動かない」罠を体験する🪤
- やること:volumeが残ってると初期化は基本走らない、を体感
- 成果物:再現手順&直し方メモ📝
- AI:現象を書いて「原因と最短修正」って聞く🤖
11. “seed”設計:開発用ダミーデータはどこまで作る?🎲
- やること:最低限のseed/テストデータ戦略
- 成果物:seed方針(少量/中量/大量の使い分け)📌
12. “migration”設計:DBの変更は「履歴」で管理する📜
- やること:手動SQLでもOK、まず“履歴が残る”を優先
- 成果物:
migrations/の運用ルール🧷 - AI:テーブル変更案を投げて「migration SQL案」を出させる🤖
13. 開発中のデータ破壊を怖がらない:リセット手順を標準装備💣➡️🧯
- やること:
down -vの意味、消していい時/ダメな時 - 成果物:「初期化からやり直す」ワンコマンド化🎛️
14. バックアップの2系統:ダンプ型 vs ファイル丸ごと型🧠

- やること:
pg_dumpみたいな“論理バックアップ”と、volumeを固める“物理バックアップ” - 成果物:自分のPJでどっち採用するか決める✅
15. まずは公式ど真ん中:volumeをtarでバックアップする🧳
- やること:一時コンテナでvolumeをマウント→
tarで固める - 成果物:
backup/にyyyymmdd.tar.gzが作れる🗜️ - 参考:Docker公式に「Back up / Restore volume」手順がある。(Docker Documentation)
16. リストア手順:戻せないバックアップは“無い”のと同じ😱
- やること:別名volumeへ復元→動作確認→切り替え
- 成果物:復元のチェックリスト✅
17. バックアップの粒度:1日1回?変更時だけ?決め方📅
- やること:頻度・世代数・保存場所のバランス
- 成果物:バックアップポリシー(超ミニでOK)📝
18. “検証”が本体:復元テスト(DRごっこ)をやる🎭
- やること:壊す→戻す→起動→確認 を手順化
- 成果物:復元テスト手順書(10分で回せる版)⏱️
19. バックアップを自動化:Windowsでも回るスクリプトにする⚙️
- やること:PowerShell or WSL で実行できる形に寄せる
- 成果物:
scripts/backup.ps1(または.sh)🧰 - AI:スクリプト雛形を作らせて、あなたが安全チェックする🤖🛡️
20. “バックアップファイル”の管理:命名・世代・掃除🧽
- やること:日付命名、古いの削除、容量の把握
- 成果物:運用ルール(3行でOK)📝
21. “秘密”が混ざる問題:バックアップに入れちゃダメな物🚫🔑
- やること:APIキー、
.env、認証情報の分離 - 成果物:除外リスト(gitignoreとは別に)🧷
22. 圧縮と暗号化:持ち出すなら最低限ここまで🔒
- やること:圧縮、パスワード、保管場所の考え方
- 成果物:バックアップ保管フロー🧊
23. “ログ”もデータ:障害調査のための保存期間を決める🪵
- やること:ログは永続化する?しない?の判断
- 成果物:ログ方針メモ📝
24. dev/prodで分ける:開発データの扱いを“本番に持ち込まない”🚧
- やること:開発用seed・テストユーザーを本番に混ぜない設計
- 成果物:環境別ルール(dev/stg/prod)📛
25. “環境変数で初期化”の設計:最小で安全に🎛️
- やること:初期DB名/ユーザー/パスワードの渡し方
- 成果物:env設計メモ(何をenvで持つ?)🧾
26. Windows特有の注意:ファイル共有が遅い/重いときの逃げ道🐢➡️🐇
- やること:WSL2側にコード置くと速くなりやすい、の理由を知る
- 成果物:自分のPJの“置き場所ルール”📌
- 参考:VS Code Dev Containers でも「WSL2上に置くとパフォーマンスが良い」方針が案内されてる。(Visual Studio Code)
27. Docker Desktopの“丸ごとバックアップ”という選択肢🧰
- やること:プロジェクト単位じゃなく“環境丸ごと”の復旧パターン
- 成果物:緊急用メモ(PC移行/再インストール時)🆘
- 参考:Docker Desktopにはバックアップ/リストア手順がある。(Docker Documentation)
28. チーム/複数PCを見据える:データの“持ち運び”設計🚚
- やること:バックアップから再現できる状態=強い
- 成果物:新PCで復元できるチェックリスト✅
29. AIを“危険にしない”使い方:データ操作はガードレール必須🛡️🤖
- やること:AIに渡す情報の線引き、破壊コマンドの確認手順
- 成果物:AI利用ルール(超短くてOK)📌
- ここは会社名だけ:OpenAI などのAIを使う時も「秘密は貼らない」を徹底🔒
30. 総仕上げ:15分で回る“データ運用ルーチン”を完成させる🏁✨
- やること:初期化→開発→バックアップ→復元テスト を短い儀式にする
- 成果物:
README.mdに「データ運用:これだけ」セクション完成📘🎉
このアウトラインの“芯”だけ最後に3つ🧠✨
- バックアップは“復元できて初めて価値”(復元テストが本体)🧯
- 初期化は「初回だけ」になりがちなので、やり直し手順を最初に作る🪤
- Windowsは置き場所で体感速度が変わるので、早めにルール化🐇(Visual Studio Code)