観測性(ログ/メトリクス/ヘルスチェック):30章アウトライン
1. 観測性の全体像をつかむ 🗺️👀
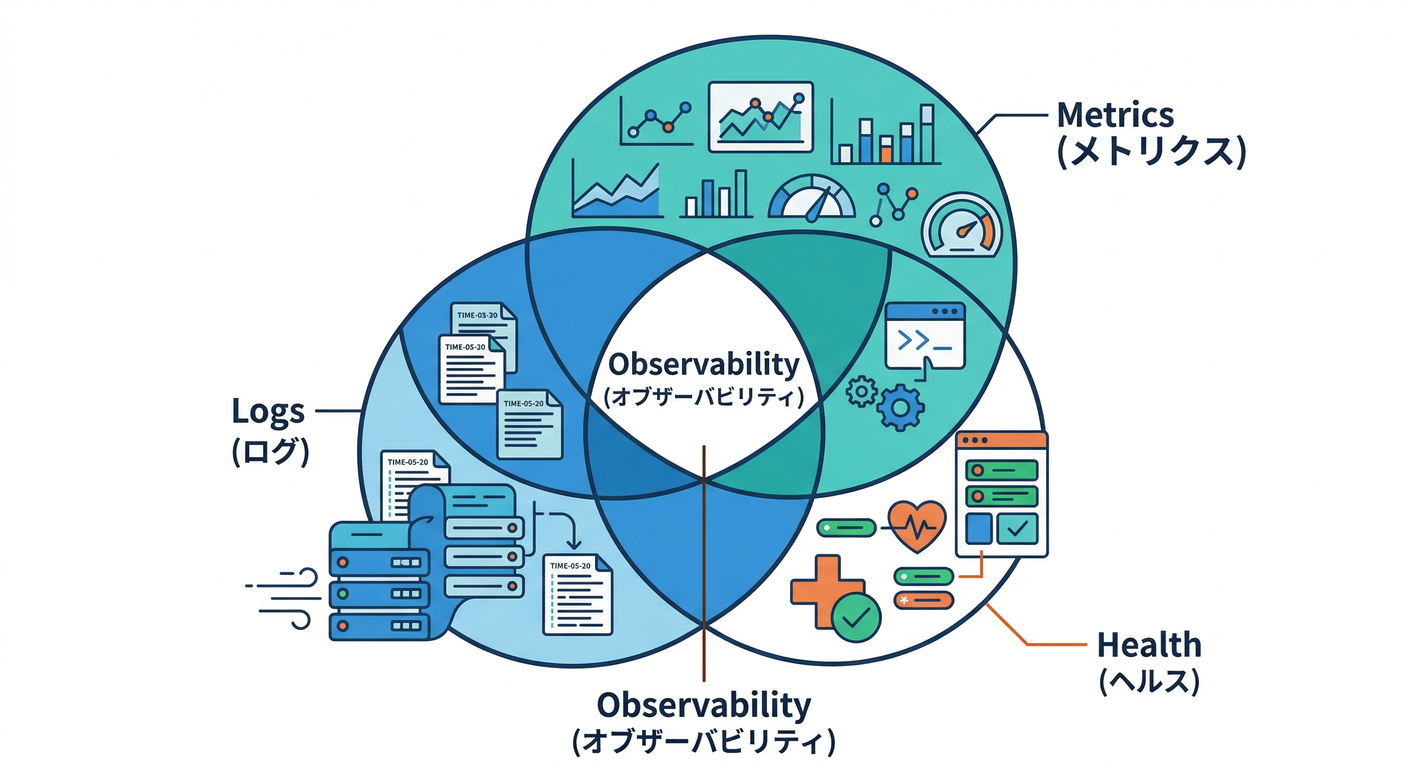
- ゴール:ログ🧾/メトリクス📈/ヘルスチェック💚の役割を一言で説明できる
- 触る:3つがそれぞれ「原因」「影響」「復旧判断」に効くイメージ
- ミニ課題:例)「遅い」「落ちる」「繋がらない」を3つに分類してみる
- AI活用🤖:症状から「まず見るべき観測データ」を箇条書きで出させる
2. “よくある障害”を3パターンに分ける 🧩😵💫
- ゴール:①アプリ起因 ②依存起因 ③環境起因 をざっくり判定できる
- 触る:原因候補を“短いリスト”にする癖
- ハンズオン:わざとエラーを返すエンドポイントを作る(/boom など)💥
- チェック:ログで「どのルートで落ちたか」が分かる
3. コンテナで見えにくいポイントを先に知る 📦🕳️
- ゴール:「入るのが面倒」「再現が短命」「数が増える」を理解
- 触る:コンテナの中に“手がかり”を置かない(標準出力に出す)📣
- ハンズオン:ログの出力先を統一(console.log / console.error)
- チェック:落としても logs で追える
4. “観測の実験場”ミニAPIを用意する 🧪🚀
- ゴール:APIがDockerで起動し、HTTPが返る
- 触る:Composeで1サービス起動→次章以降で徐々に増やす
- ハンズオン:/ping(常にOK)と /slow(遅い)を作る 🐢
- チェック:/slow で「遅い」が再現できる
ログ編 🧾🔥
5. ログの基本:まずは“標準出力”に出す 📣🖥️
- ゴール:ログは「どこに出せば拾えるか」が分かる
- 触る:INFOはstdout、ERRORはstderrの感覚
- ハンズオン:起動ログ・リクエストログ・エラーログを分けて出す
- チェック:コンテナ再起動してもログ確認できる
6. ログを見る練習:追いかける・絞る 👀🏃♂️
- ゴール:目的のログを“最短操作”で見つけられる
- 触る:tail / follow / サービス指定 / 時間帯の意識 ⏱️
- ハンズオン:/ping を連打→ログが増える体験
- チェック:最後の10行だけ見て状況説明できる
7. アクセスログ:1行で“何が起きたか”を書く 🚪🧾
- ゴール:最低限の項目(method/path/status/ms)を揃える
- 触る:人間が読むログは“短く・揃える”
- ハンズオン:レスポンス時間を計って1行に入れる ⏱️
- チェック:「遅いルート」がログで当てられる
8. ログレベル入門:DEBUG/INFO/WARN/ERROR 🎚️🟢🟡🔴
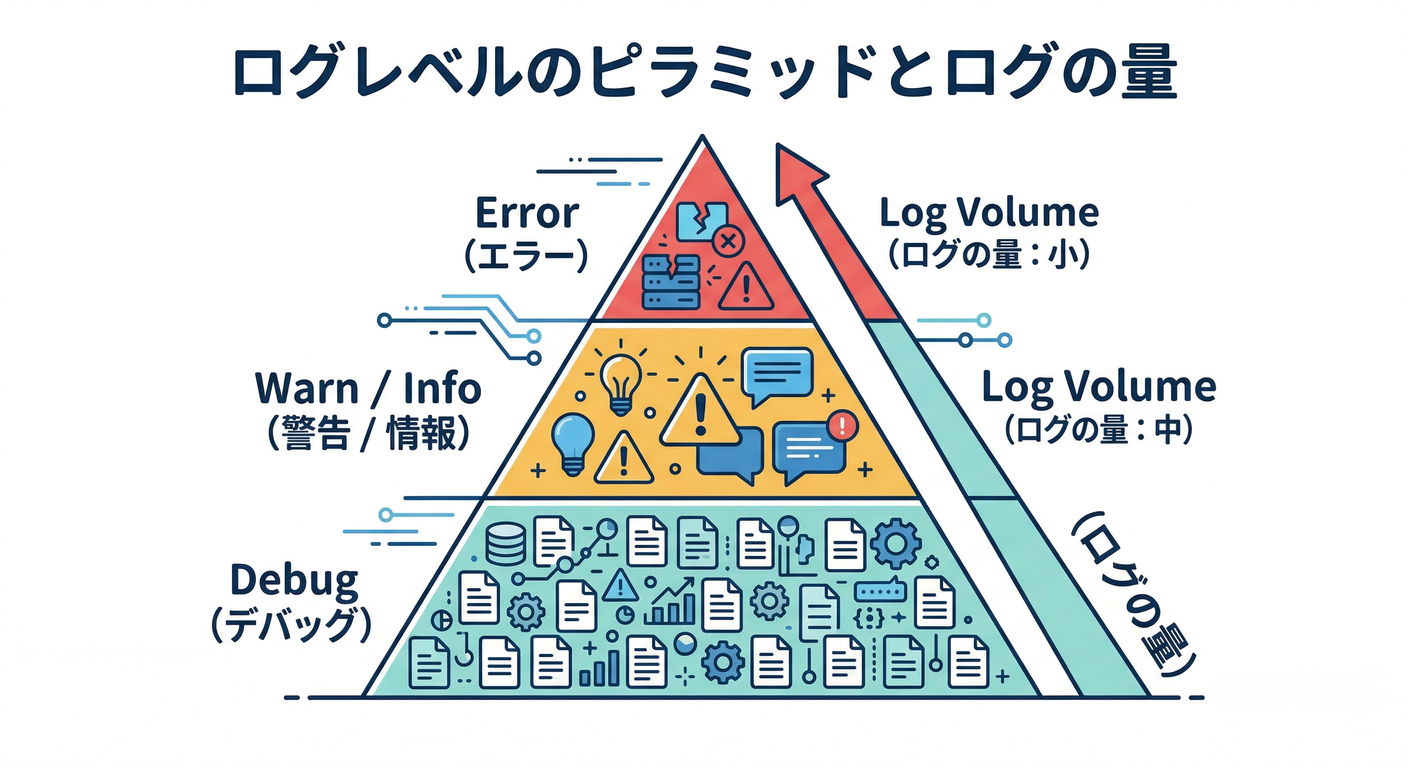
- ゴール:どれをどこで使うか説明できる
- 触る:本番でDEBUGを垂れ流さない理由(量・コスト)💸
- ハンズオン:環境変数でログレベル切替(例:LOG_LEVEL)
- チェック:同じ操作で出るログが変わるのを確認
9. 構造化ログ(JSON):検索しやすい形にする 🧱🔎
- ゴール:ログを“文字列”から“データ”にする感覚が分かる
- 触る:keyを揃える(msg, level, time, route, status, ms…)
- ハンズオン:ログ出力をJSONに切り替える
- チェック:同じキーで並ぶログを見て「追いやすい!」を体感
10. リクエストID(相関ID):1リクエストを追跡する 🧵🪪
- ゴール:複数ログを“1本の線”でつなげられる
- 触る:受け取る→なければ作る→レスポンスヘッダにも返す
- ハンズオン:middlewareでreqId付与、全ログに埋め込む
- チェック:1つのreqIdで一連のログを読める
11. エラーを逃さない:例外・Promise・プロセス終了 🧯⚠️
- ゴール:“落ちた理由”がログに残る
- 触る:try/catchだけじゃ足りないパターン
- ハンズオン:未処理Promise・例外をわざと起こしてログに出す
- チェック:終了前に最後のメッセージが残る
12. 秘密情報を守る:マスキングと禁止ルール 🙈🔒
- ゴール:何をログに出しちゃダメか分かる
- 触る:Authorization / Cookie / password / token を隠す
- ハンズオン:ヘッダやボディをログに出す時のマスキング関数
- チェック:ログにtokenが出てないことを確認
13. ログ量と保存:増えすぎ問題と“削る設計”💽🌀
- ゴール:ログが増えるほど“読めなくなる”ことを理解
- 触る:粒度(全件か、エラー中心か)、サンプリングという発想
- ハンズオン:/spamlog を作ってログ地獄を体験 😇
- チェック:必要ログだけ残す方針を書ける
14. “集めて検索”の入門:Lokiで探せるログにする 🧲🔍📊
- ゴール:CLIだけじゃなく“検索UI”で探す体験をする
- 触る:ラベル(service, env)を揃えると強い
- ハンズオン:ComposeでLoki+Viewer(Grafana)を追加
- チェック:「reqIdで検索」or「status=500で絞る」ができる
メトリクス編 📈🧠
15. メトリクスの基本:数で見る世界 🧮📊
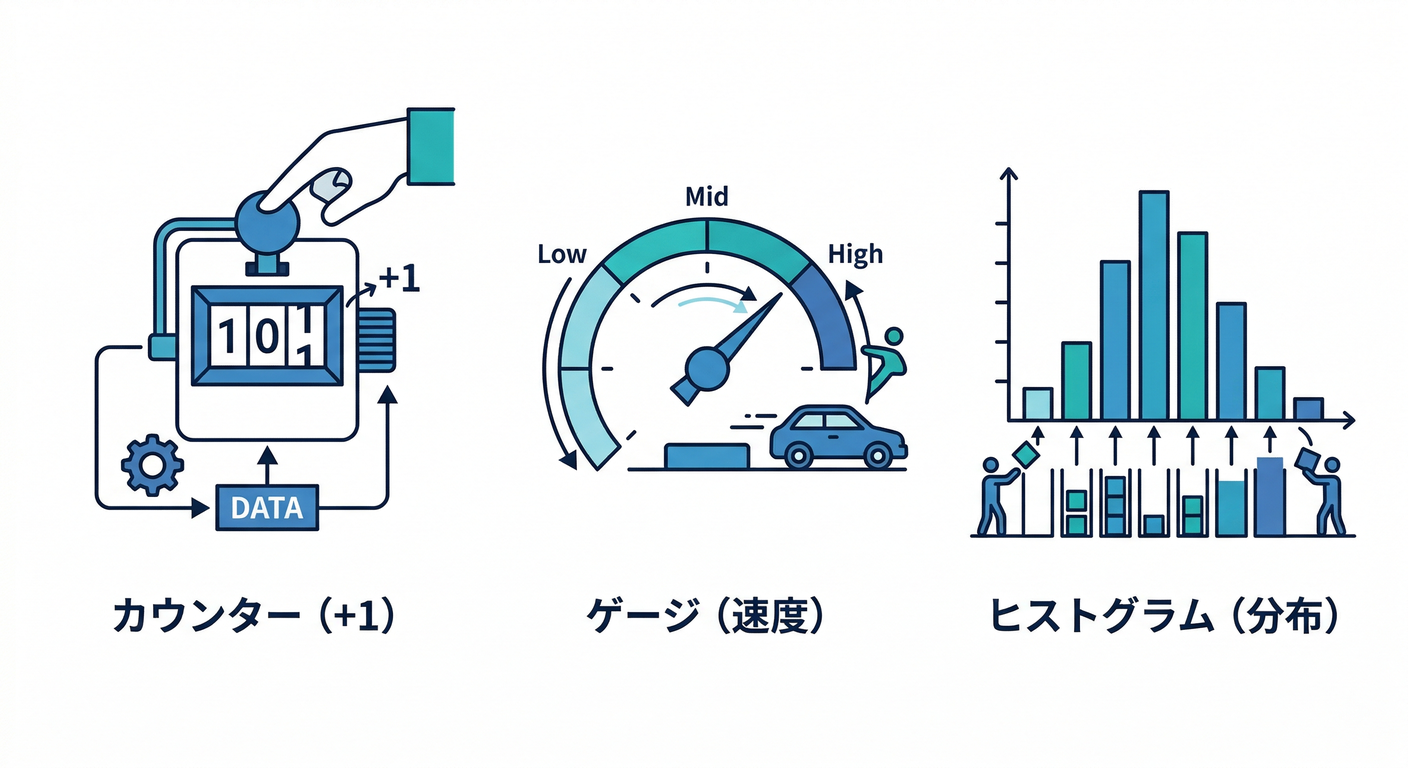
- ゴール:カウンタ/ゲージ/ヒストグラムを例で言える
- 触る:ログは“点”、メトリクスは“面”(傾向)
- ミニ課題:「遅い」を数字で言うなら何?(p95など)📐
- AI活用🤖:API向け“最初に取るべき5指標”を出させる
16. /metrics を生やす:最小のprom-client 🌱📏
- ゴール:メトリクスの吐き出し口ができる
- 触る:メトリクスは“引っ張りに来てもらう”
- ハンズオン:カウンタ(リクエスト数)を増やす
- チェック:/metrics に数値が出ている
17. レスポンス時間を測る:ヒストグラムで速度を見る ⏱️📉
- ゴール:平均じゃなく分布で見る意味が分かる
- 触る:p50/p95/p99のざっくり理解
- ハンズオン:/slow を叩くとヒストグラムが変わる
- チェック:遅いルートが数字で見える
18. エラー率を見る:失敗の数え方 🧯🧾
- ゴール:成功/失敗を「割合」で語れる
- 触る:status別カウント(2xx,4xx,5xx)
- ハンズオン:/boom で5xxを増やす
- チェック:エラー率が上がるのを確認
19. システム系メトリクス:CPU/メモリ/イベントループ 🧠⚙️
- ゴール:アプリ以外のボトルネックにも気づける
- 触る:メモリ増加=リーク疑い、CPU張り付き=重い処理疑い
- ハンズオン:簡単な重い計算を入れてCPUっぽさを体験 🧱
- チェック:負荷をかけるとメトリクスが動く
20. Prometheus導入:スクレイプのしくみを知る 🕸️📥
- ゴール:Prometheusが/metricsを取りに来る流れが分かる
- 触る:targets / scrape_interval の超基本
- ハンズオン:ComposeでPrometheus追加→targets確認
- チェック:Prometheus側で時系列が見える
21. Grafanaで可視化:最初のダッシュボード 🖼️✨
- ゴール:“見える化”してテンション上げる 😆
- 触る:パネル(グラフ)・クエリ・時間範囲
- ハンズオン:RPS、エラー率、p95、メモリ を並べる
- チェック:/slow を叩くとグラフが反応する
22. アラート入門:通知は“少なく強く” 🚨📣
- ゴール:アラート疲れを避ける考え方が分かる
- 触る:閾値+持続時間(5分続いたら)などの発想
- ハンズオン:p95が一定以上で警告、5xx率で危険 などを作る
- チェック:わざと壊してアラートが鳴る
23. “見る文化”を作る:運用ルーチン化 🧹📅
- ゴール:毎日/毎週、何を見るか決められる
- 触る:朝イチ確認(落ちてない?遅くない?)
- ハンズオン:ダッシュボードに「今日の健康状態」パネルを作る
- チェック:3分で状態を説明できる
ヘルスチェック編 💚🩺
24. ヘルスの考え方:生存/準備/起動の違い 👶➡️🏃♂️
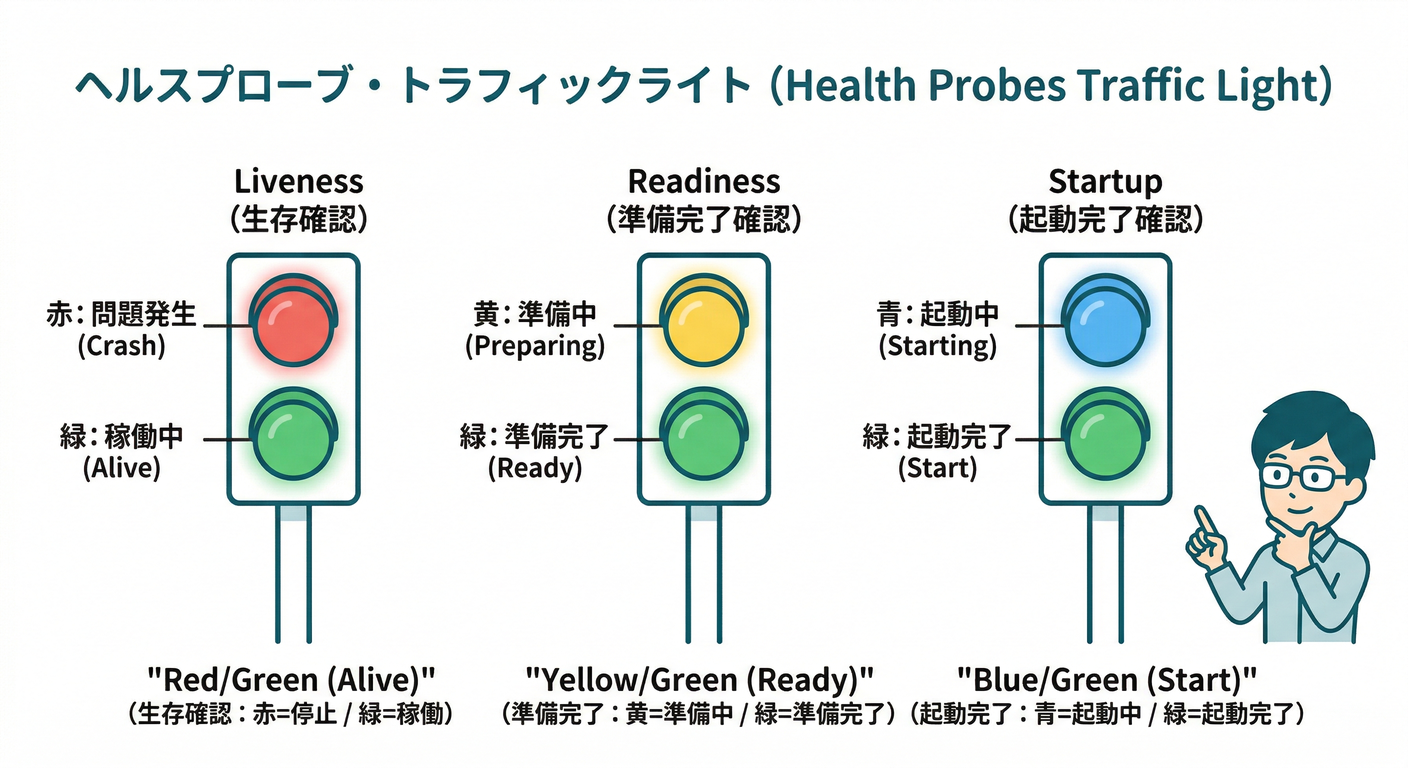
- ゴール:liveness/readiness/startupの役割を言える
- 触る:生きてる=OKじゃない(依存が死んでるとダメ)
- ミニ課題:「DBが落ちてる時、/healthはどう返す?」🤔
- AI活用🤖:状態別のHTTPコード案を作らせる
25. /health を作る:まずは“プロセスが生きてる”✅
- ゴール:最低限のヘルスが返る
- 触る:軽い処理で即返す(重いチェック禁止)⛔
- ハンズオン:/health を200固定で返す
- チェック:落ちてたら当然返らない、を体験
26. /ready を作る:依存サービスがOKかチェック 🧩🔌
- ゴール:依存が死んでる時に“準備できてない”を返せる
- 触る:DBやRedisへの“軽い疎通”
- ハンズオン:依存を止める→/readyが失敗に変わる
- チェック:依存復帰→/readyがOKに戻る
27. Dockerfile HEALTHCHECK:コンテナ自身に健康判定を持たせる 🧪📦
- ゴール:Dockerのhealthステータスが変わるのを理解
- 触る:interval/timeout/retries/start-period の感覚
- ハンズオン:/health を叩くHEALTHCHECKを入れる
- チェック:わざと失敗して unhealthy を見る 😈
28. Composeの起動順:healthyになってから次へ ⏳🔁
- ゴール:依存が準備できるまで待てる
- 触る:depends_on の “条件付き”の意味
- ハンズオン:DB→APIの順に起動が整う構成にする
- チェック:起動直後の“接続失敗ログ”が減る
まとめ&実戦 💪🌈
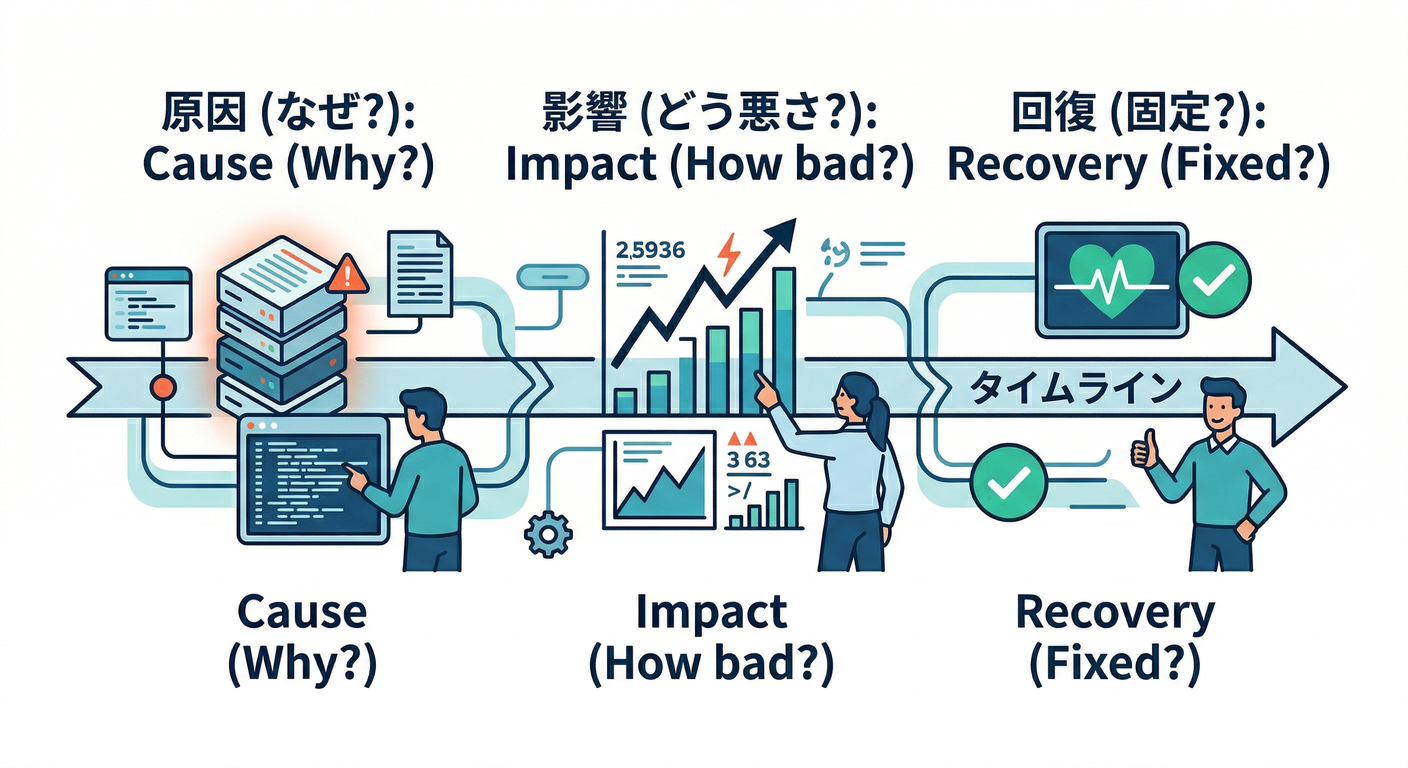
29. 三点セットの連携:原因→影響→復旧判断の流れ 🔁🧭
-
ゴール:障害対応の手順が“型”になる
-
触る:
- ログ=どこで何が起きた
- メトリクス=どれだけ影響が出た
- ヘルス=復旧したと言っていいか
-
ハンズオン:テンプレ手順書(3分・10分・30分)を作る 📝
-
チェック:誰かに読ませても迷いにくい
30. 卒業制作:わざと壊して直す “観測性デバッグRPG”🎮🧨🩹
-
ゴール:観測データだけで復旧まで持っていける
-
シナリオ例:
- /slow が急にp95悪化 🐢➡️🐢🐢
- 5xxが増える 💥
- 依存が断続的に落ちる 🔌⚡
-
進め方:
- まずログで「どこ?」
- 次にメトリクスで「どれくらい?」
- 最後にヘルスで「戻った?」
-
成果物:自分専用の“観測性テンプレ”+ダッシュボード+ヘルス設計 🏆
おまけ:各章につけると強い“固定フォーマット”📌✨
章ごとに、本文はこの型にすると学びやすいよ〜😊
- ① 今日のゴール 🎯
- ② 図(1枚)🖼️
- ③ 手を動かす(手順5〜10個)🛠️
- ④ つまづきポイント(3つ)🪤
- ⑤ ミニ課題(15分)⏳
- ⑥ AIに投げるプロンプト例(コピペOK)🤖📋
次はさらに一段深くして、各章に「具体的なファイル構成(/src, compose.yml, Dockerfile)」「コマンド」「期待する出力(例:ログの1行見本)」まで埋めた“執筆用アウトライン”にもできるよ 😊✍️📦