第15章:メトリクスの基本:数で見る世界 🧮📊
① 今日のゴール 🎯
この章が終わったら、こんな会話ができるようになります👇
- 「これは Counter だね(回数を数えるやつ)🔢」
- 「これは Gauge(今の値)だね📍」
- 「これは Histogram(分布)だね📦」
- 「“遅い”は平均じゃなくて p95 で語ろう😇」
② ざっくり図 1枚 🖼️
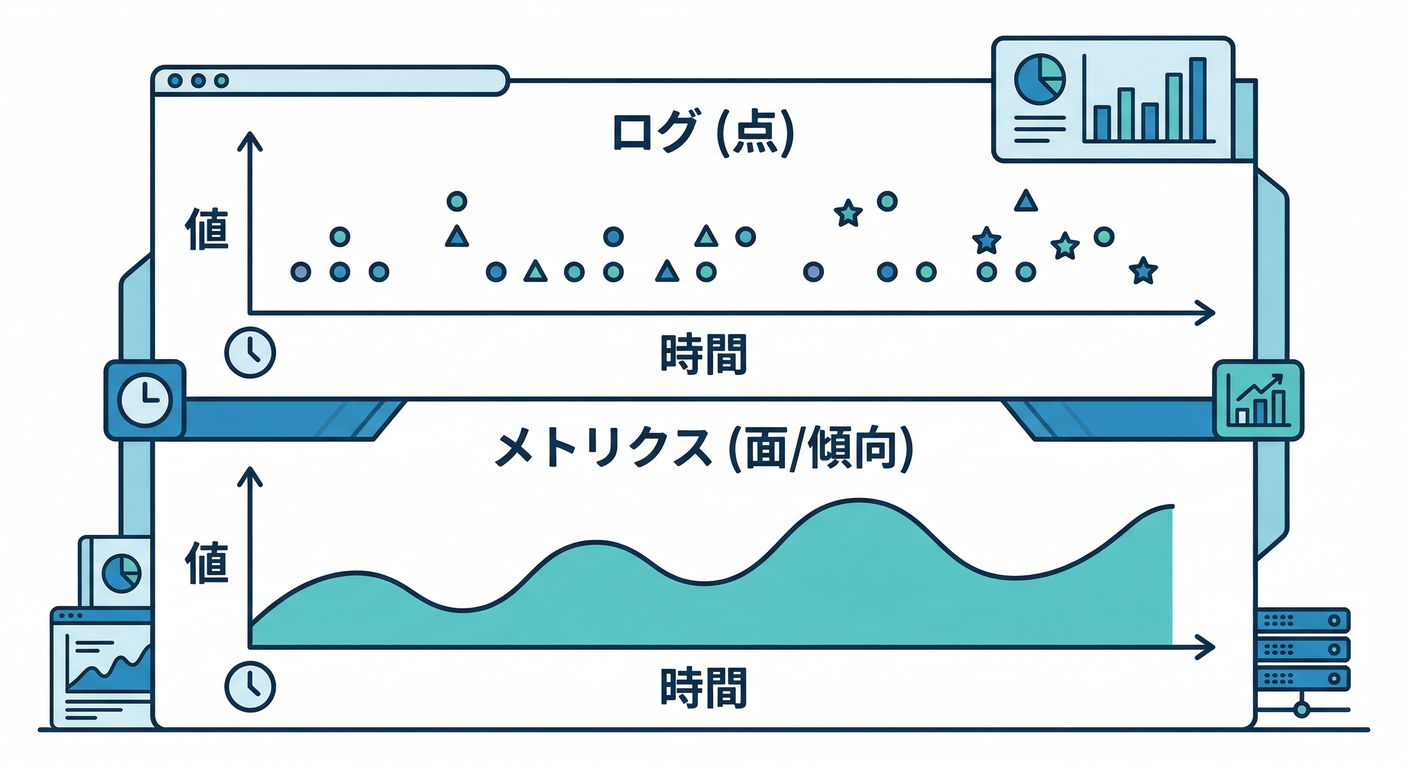
メトリクスは「数字が時間とともに並ぶ」イメージです📈
ログ : 1回1回の出来事(点) • • • • •
メトリクス: 数字の流れ(面) ─────────→ 時間
10 12 11 50 13 12 ...
ログは「その瞬間に何が起きた?」に強い🧾 メトリクスは「増えてる?悪化してる?」みたいな 傾向 に強い📊✨
③ まず大事な前提 何を測ると強いの 🧠💡
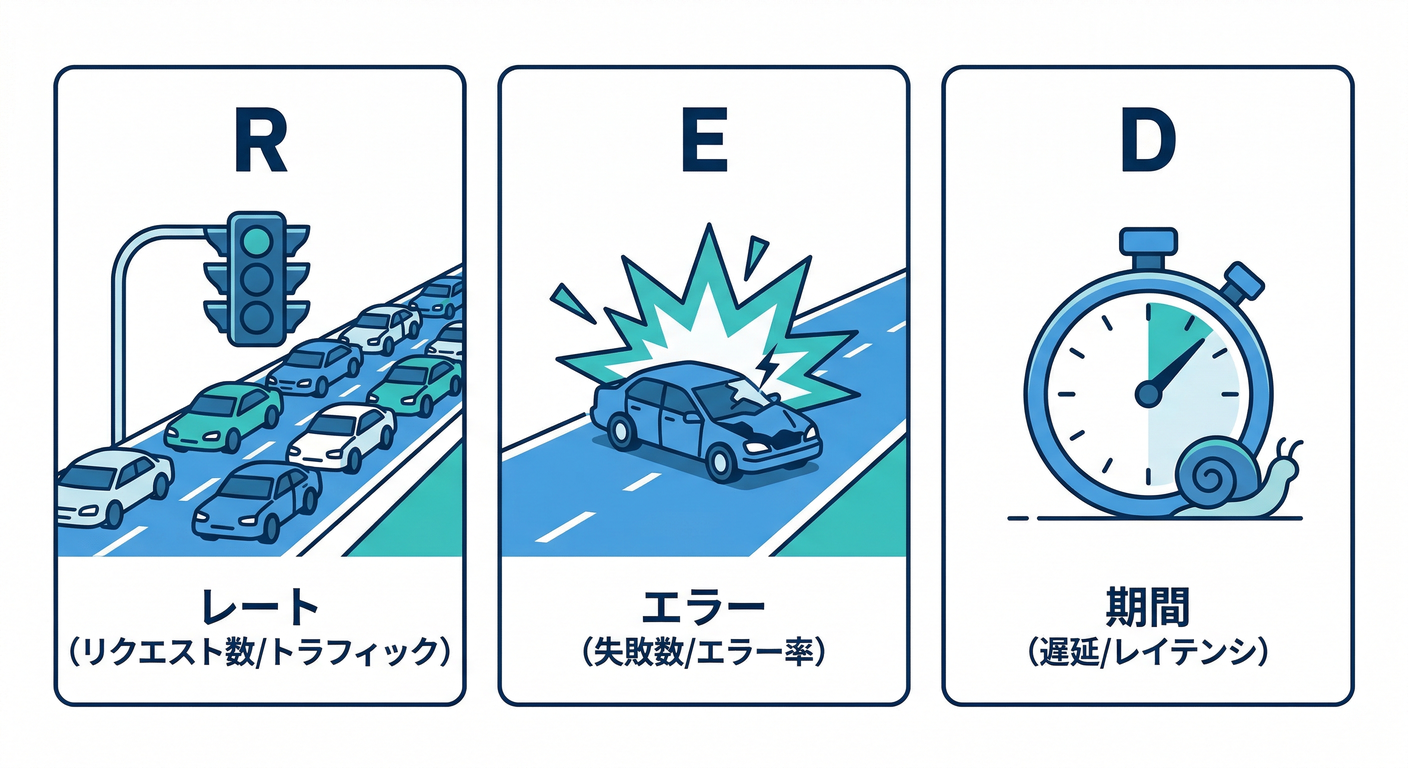
Web API みたいな“リクエスト駆動”の世界では、最初は RED が超つよいです🔥
- Rate:どれだけ来てる?(リクエスト数/秒)🚦
- Errors:どれだけ失敗してる?(5xx率など)💥
- Duration:どれだけ遅い?(p95など)🐢
これは運用の考え方としてよく使われます。(Grafana Labs)
④ メトリクスの3種類を一撃で覚える 🥊💥
1) Counter カウンタ 🔢
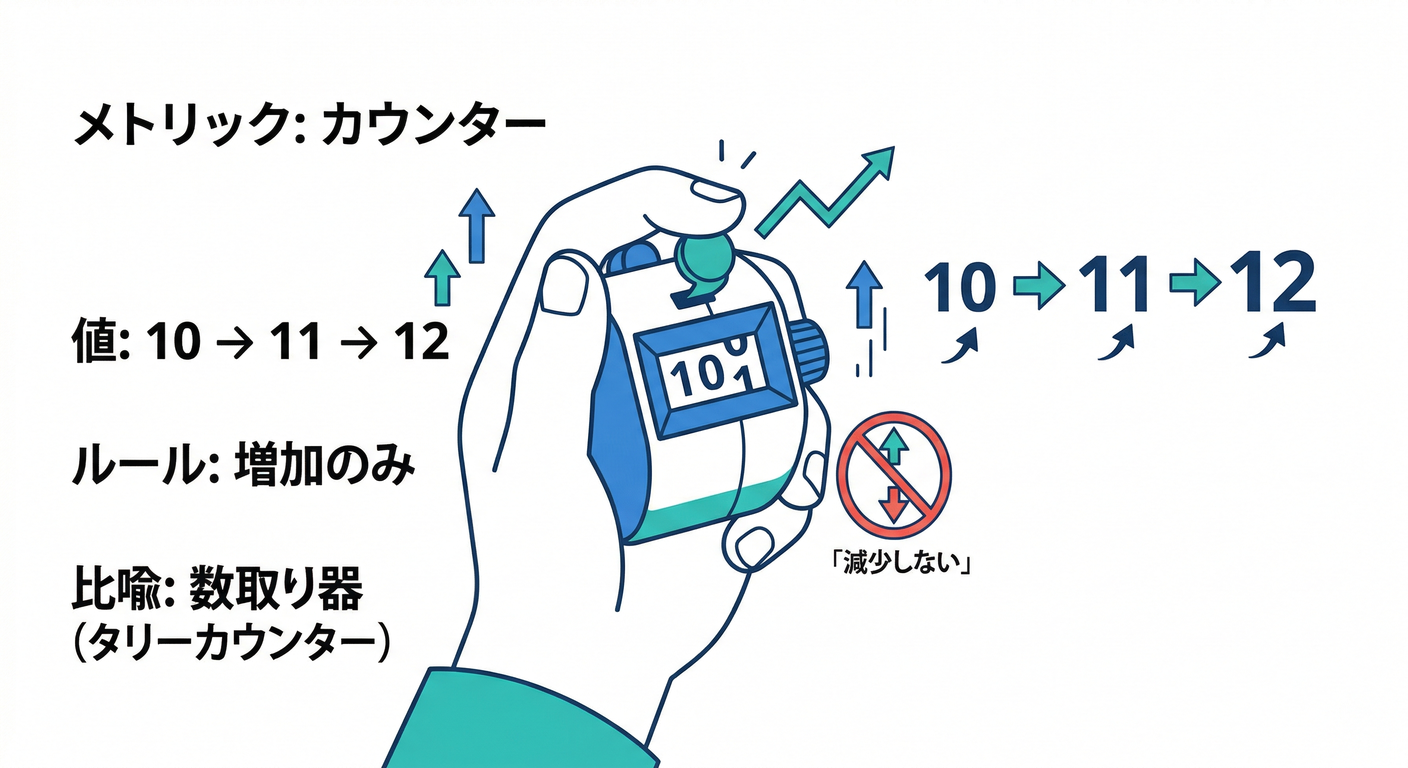
増えるだけ(基本は減らない) 例:
http_requests_total(リクエスト総数)🚪http_errors_total(エラー総数)🧯
「減る可能性があるもの」を Counter にしちゃダメだよ、って公式も言ってます。(OneUptime)
2) Gauge ゲージ 📍
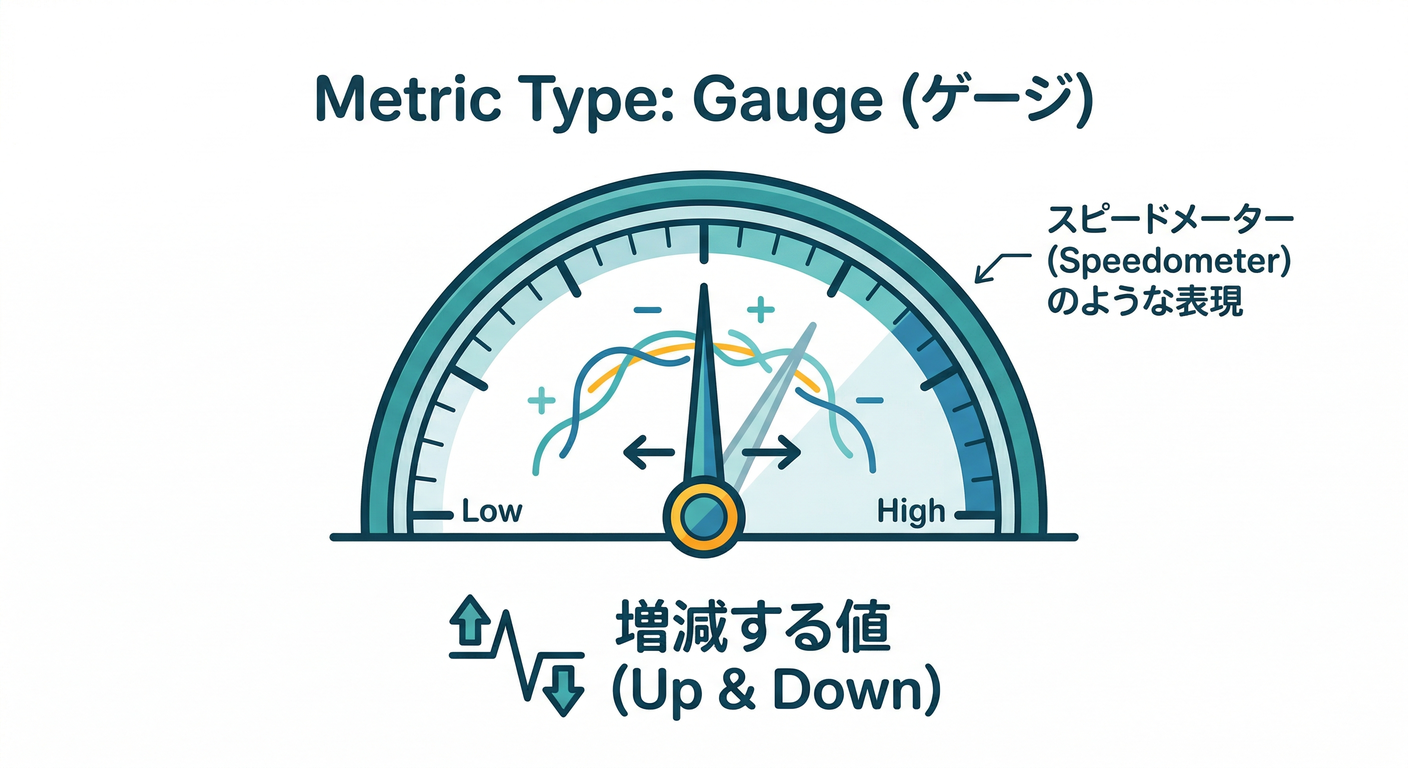
いまの値(上がったり下がったりOK) 例:
in_flight_requests(処理中のリクエスト数)🧵memory_bytes(使用メモリ)🧠
「現在いくつ?」の世界は Gauge が自然です。(OneUptime)
3) Histogram ヒストグラム 📦📉
分布を見るやつ(“遅い”を語る主役) 例:
http_request_duration_seconds(リクエスト時間)⏱️
ヒストグラムは「速いのが多い」「遅いのが混ざる」みたいな形が見えます。
そして Prometheus では p95/p99 を histogram_quantile() で出すのが王道です。(prometheus.io)
ちなみに Prometheus には Summary もあるけど、まずは Counter/Gauge/Histogram で十分戦えます(公式もこの4タイプを説明)。(OneUptime)
⑤ 「遅い」を数字で言う p95 の正体 📐🐢
平均だけ見てると事故る 😇💣
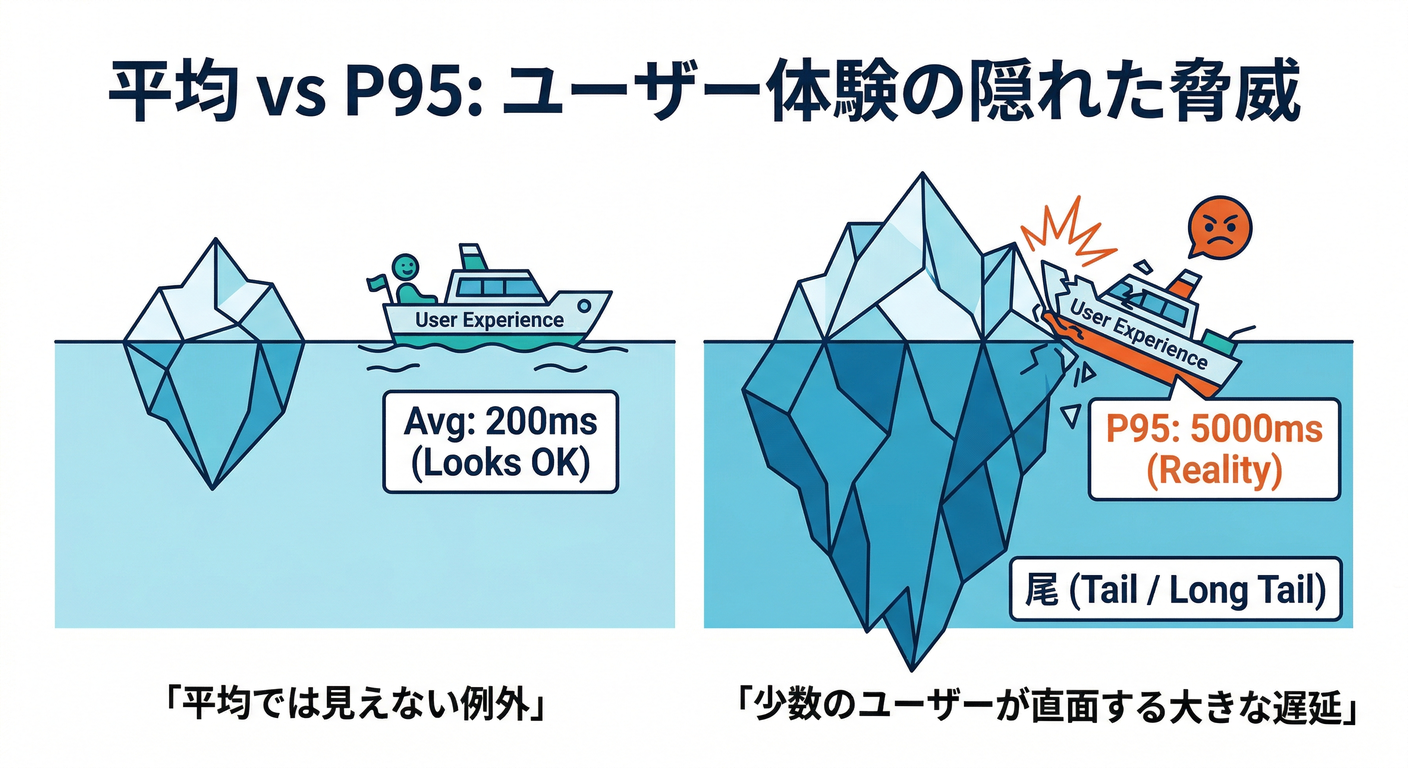
たとえば 10回のうち 9回が 100ms、1回が 2000ms でも… 平均はそこまで悪く見えないのに、体感は「たまに激重」になります😵💫
そこで p95(95パーセンタイル)を使うと、 「95%のリクエストはこれ以下の時間だよ」って言える📣 定義としては「並べて95%地点を見る」感じ。(SigNoz)
⑥ 手を動かす ミニ実験 🧪💻✨
ここでは Prometheus をまだ入れずに、p50/p95 の感覚を体に入れます💪
(次章で /metrics を生やすと一気につながるよ!🌱)
ファイルを作る 📁
tools/percentile.ts を作って👇
type Percentile = 0.5 | 0.95 | 0.99;
function percentile(values: number[], p: Percentile) {
const sorted = [...values].sort((a, b) => a - b);
const n = sorted.length;
if (n === 0) throw new Error("empty");
// 超シンプル版:p*n を使って index を決める(学習用)
const idx = Math.min(n - 1, Math.floor(p * n) - 1);
return sorted[Math.max(0, idx)];
}
function avg(values: number[]) {
return values.reduce((a, b) => a + b, 0) / values.length;
}
// 例:9回は速いけど、1回だけ激遅 🐢💥
const samplesMs = [100, 105, 98, 110, 95, 102, 101, 99, 108, 2000];
console.log("samples(ms):", samplesMs.join(", "));
console.log("avg:", avg(samplesMs).toFixed(1), "ms");
console.log("p50:", percentile(samplesMs, 0.5), "ms");
console.log("p95:", percentile(samplesMs, 0.95), "ms");
console.log("p99:", percentile(samplesMs, 0.99), "ms");
実行する ▶️
(TypeScript を実行できる方法なら何でもOK。例えば tsx を使うなら)
npm i -D tsx
npx tsx tools/percentile.ts
期待する出力イメージ 👀
samples(ms): 100, 105, 98, 110, 95, 102, 101, 99, 108, 2000
avg: 291.8 ms
p50: 101 ms
p95: 110 ms
p99: 2000 ms
ここで感じてほしいこと👇
- 平均:なんか「そこそこ」っぽい顔する🎭
- p50:いつもどおりの体感に近い😌
- p95:普段の“遅さの上限ライン”っぽい📏
- p99:たまに出る地獄が見える😈
実際の Prometheus では、ヒストグラムの bucket から
histogram_quantile(0.95, ...)で p95 を出すのが基本形です。(prometheus.io)
⑦ つまづきポイント あるある3つ 🪤😵💫
-
Counter と Gauge を逆にする 「いまの処理中数」を Counter にしちゃう、みたいな事故⚠️ → “増えるだけ”か?を自問!(OneUptime)
-
ラベルに user_id や reqId を入れて爆死 💥🔥 Prometheus は「ラベルの組み合わせ=別の時系列」なので、 ユニーク値を入れるとメモリも保存も吹っ飛びます😇 公式も「高カーディナリティは避けて」って強く注意してます。(prometheus.io)
-
平均だけで“遅い”を語ってしまう → p95/p99 をセットで見る癖をつけると、運用が一気に楽になる🧘♂️✨
⑧ ミニ課題 15分 ⏳📝
次の項目、どのメトリクス型が合うか書いてみてね👇(理由も一言!)
- リクエスト総数 🚪
- いま処理中のリクエスト数 🧵
- レスポンスタイム(速い/遅いの分布)⏱️
- いまのメモリ使用量 🧠
- 5xx エラーの回数 💥
さらに余裕があれば:
- 自分のミニAPIに「最初に入れる5指標」を RED で箇条書きにする📋(Grafana Labs)
⑨ AIに投げるプロンプト例 コピペOK 🤖📋✨
(「GitHub Copilot」でも「OpenAI Codex」でも使えるやつ🚀)
あなたはSREの先生です。
Node/TypeScriptのHTTP APIに最初に入れるべきメトリクスを、
Counter/Gauge/Histogramに分類して、メトリクス名案も一緒に5〜8個出してください。
条件:
- ラベルの高カーディナリティ(user_idやreqId等)を避ける
- RED(Rate/Errors/Duration)を必ずカバーする
- 「遅い」をp95で見たい前提で、Histogram設計の注意点も一言
ラベル設計で迷ったらこれ👇(地雷回避用🧨)
次の候補ラベルはPrometheus的に危険ですか?危険なら代替案を出してください:
(method, route, status, user_id, reqId, ip, error_message)
高カーディナリティの理由も説明してください。
(高カーディナリティ注意は公式でも重要ポイントです)(prometheus.io)
⑩ 次章へのつながり 🌱➡️📏
この章で「何を測るか・どう語るか」が分かったので、次は 吐き出し口 を作ります👇
/metricsを生やして、数字を外に出す🌱- Counterを実際に増やして「増えてる!」を体験する🔢
(この流れは、Prometheusの“取りに来る”方式とも相性バツグンです🕸️)
参考として押さえておきたい最新トピック小ネタ 📰✨
- Node.js は v24 系が Active LTS、v25 系が Current という扱いで更新されています(本日時点の公式一覧)。(nodejs.org)
- TypeScript は 6.0 Beta が公開され、「将来はGoベースの新コードベースへ」という流れが明言されています。(Microsoft for Developers)
次は第16章「/metrics を生やす」いきましょ〜!🌱📈😆