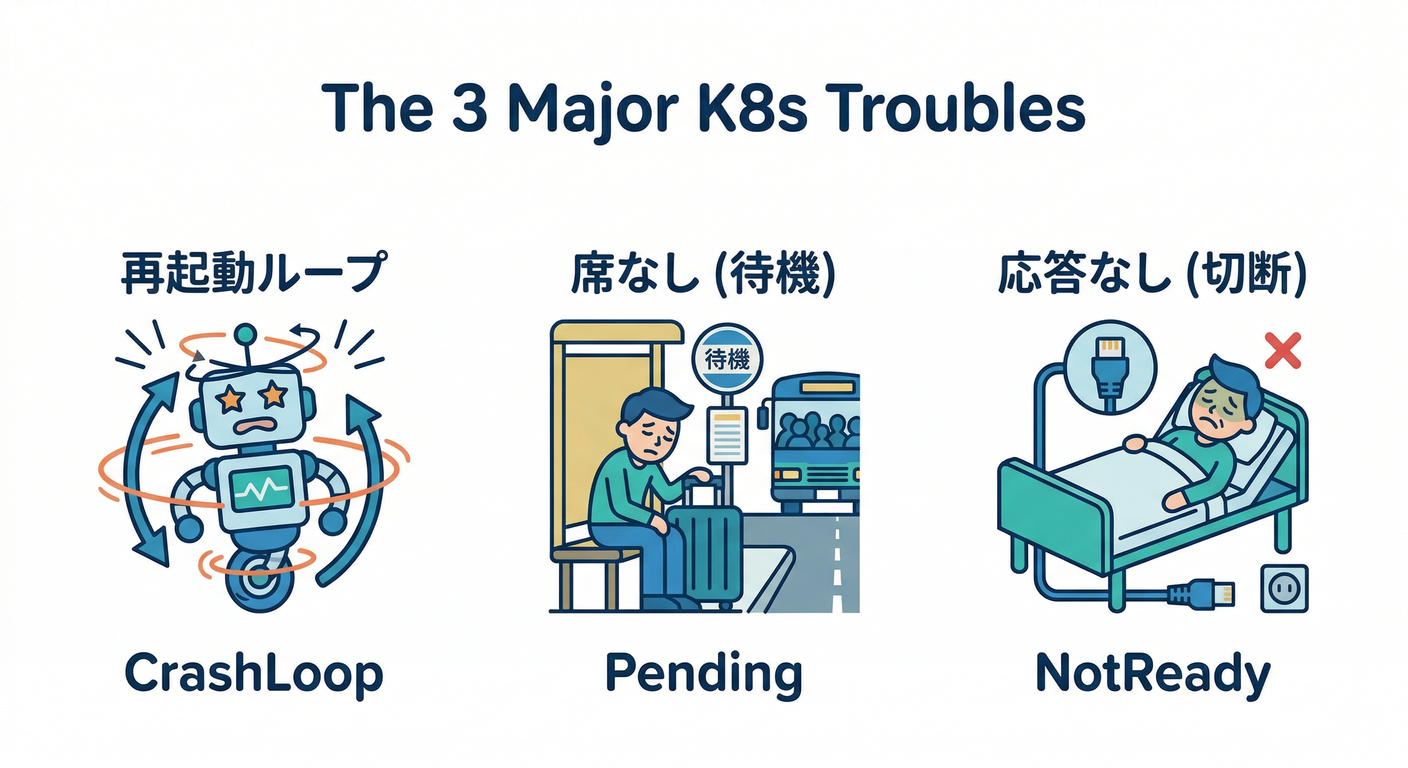
第28章:トラブルシュート道場(CrashLoop / Pending / NotReady)🥋🔥
この章は「事故っても直せる人」になる回です😎✨ Kubernetesは“落ちたら勝手に立ち上げ直す”のが得意。でも、なぜ落ちたかを放置すると永遠に苦しみます😂 ここでは ありがち3大事故を、**最短ルートで切り分ける“型”**として体に入れます🧠💪 (Kubernetes v1.35系の最新ドキュメント内容を前提にしています)(Kubernetes)
0) 道場の“型” 🥷(困ったらこれだけ)
まずは30秒ルーティン⏱️
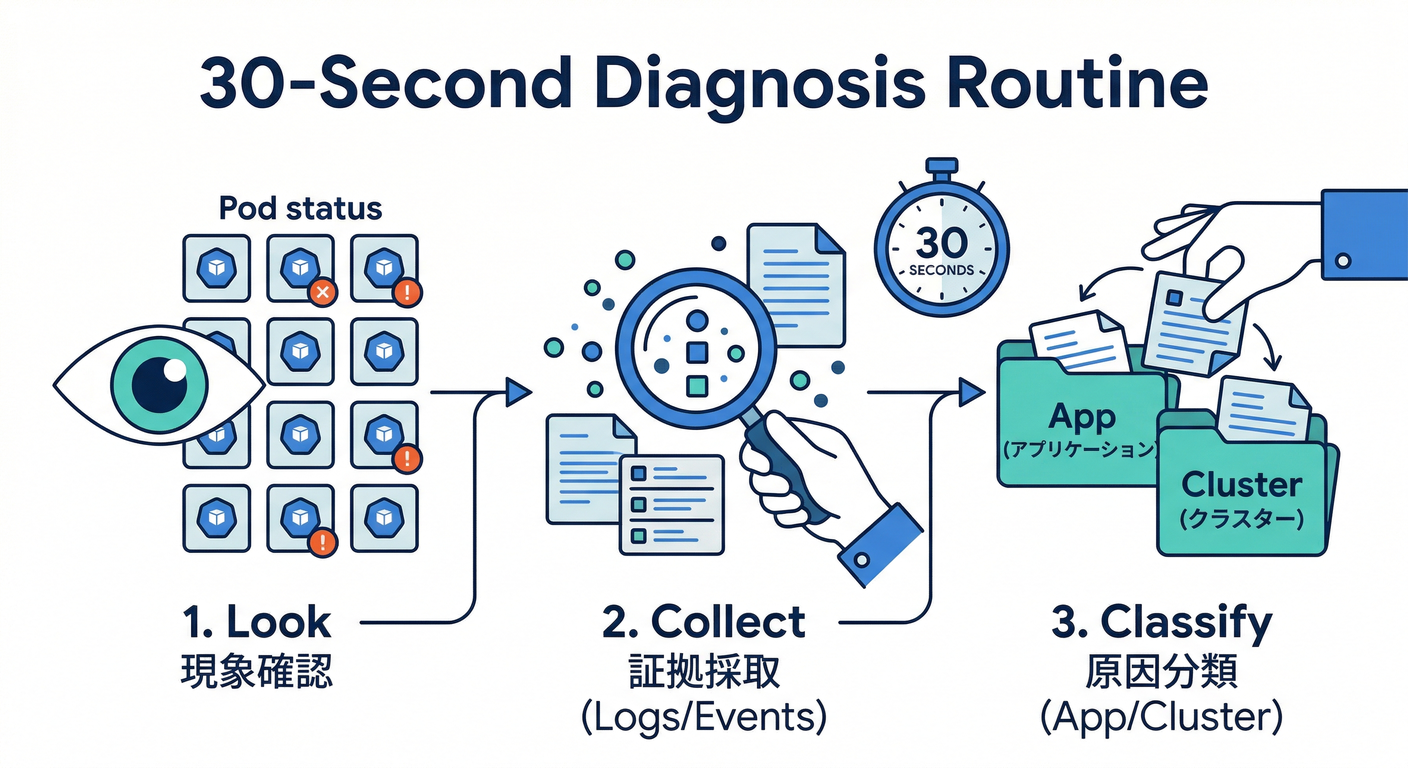
-
現象確認:Podが何状態?(CrashLoop?Pending?RunningだけどReady=0?)
-
証拠採取:
describeとlogsとevents -
原因を分類:
- アプリが死んでる?(exit / 例外 / 設定ミス)
- クラスタ都合?(スケジューリング / リソース / ノード)
- 設定ミス?(env / volume / probe / image)
Kubernetes公式も、CrashLoopBackOffは「指数バックオフで再起動を繰り返す状態」で、まず ログ / イベント / 設定 / リソースを見ろって言ってます🧾(Kubernetes)
1) 道場の準備(練習用namespace)🏗️
PowerShellでOKです🪟✨
kubectl create namespace dojo
kubectl config set-context --current --namespace=dojo
「dojo」内だけで壊して直すので安心😌🛡️
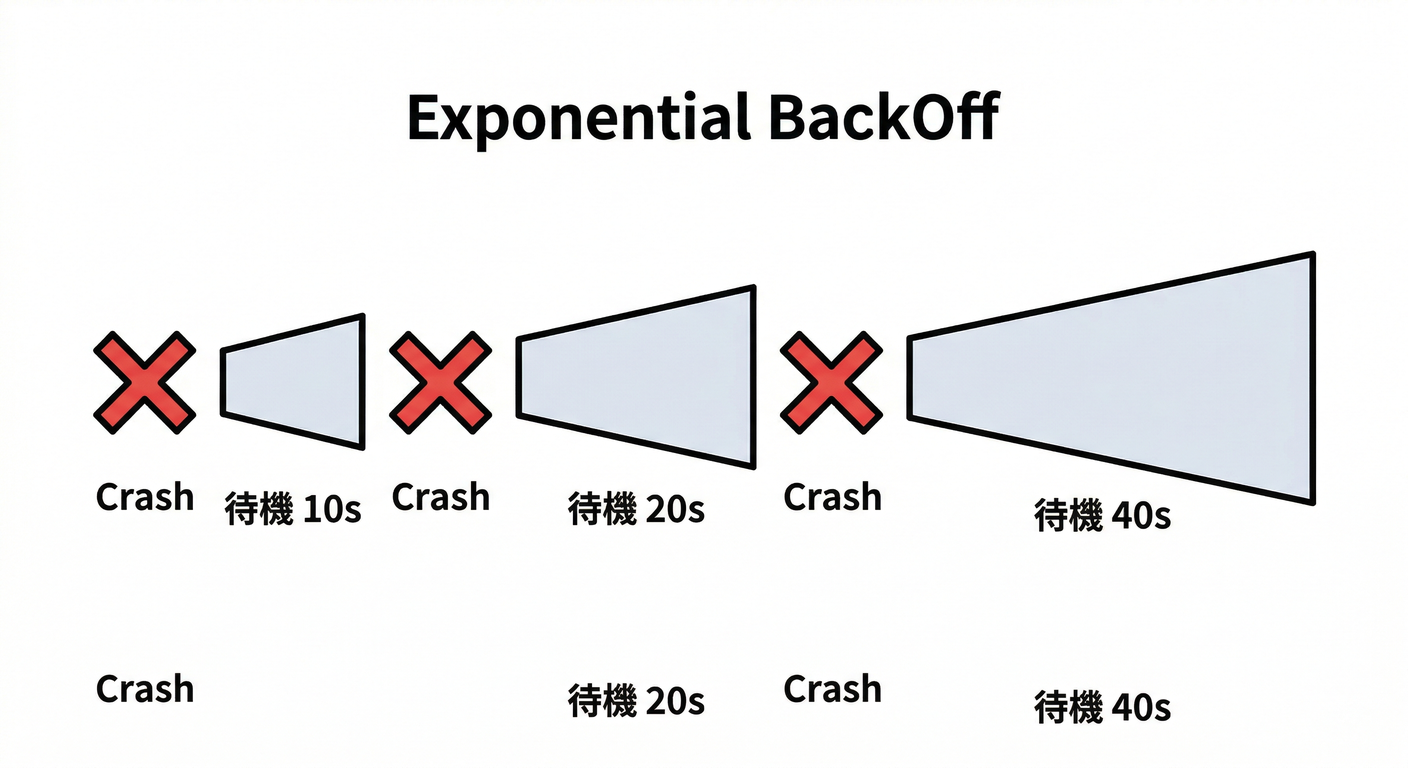
2) CrashLoopBackOff 道場 💥🔁(“落ちて→起きて→また落ちる”)
2-1) わざと壊す(最小のCrashLoop)😈
apiVersion: v1
kind: Pod
metadata:
name: crashloop-sample
spec:
containers:
- name: app
image: busybox:1.36
command: ["sh", "-c", "echo boom; sleep 1; exit 1"]
restartPolicy: Always
kubectl apply -f .\crashloop.yaml
kubectl get pods -w
しばらくすると CrashLoopBackOff が出ます👀
これはKubernetesが「すぐ再起動→また失敗」を繰り返すので、再起動間隔を指数的に伸ばしてる状態です(過負荷防止)(Kubernetes)
2-2) 最短3手で切り分ける ✂️
手1:状態を掴む(終了理由・ExitCode)🧾
kubectl describe pod crashloop-sample
見る場所(超重要)👇
State:/Last State:(Terminated の reason / exit code)Events:(BackOff / probe失敗 / 取得失敗 など)
手2:ログを見る(“直前に何が起きたか”)🪵
kubectl logs crashloop-sample
手3:ひとつ前の落ちた回のログを見る(これ神🙏)
kubectl logs crashloop-sample --previous
--previous は、再起動を繰り返してる時の鉄板ムーブです🧠(Kubernetes)
2-3) 典型原因と“直し方テンプレ”🧰✨
Kubernetes公式が挙げる代表原因はこんな感じ👇(ここ、まんま現場で出ます)(Kubernetes)
- アプリが落ちる(例外・exit 1) → まずログ。次に設定(env/ConfigMap/Secret)を疑う
- 設定ミス(環境変数名ミス、必要ファイルが無い、volume mount先違い)
→
describeの Events がヒントをくれることが多い - リソース不足(メモリ足りず起動できない、OOMKill)
→
describeでOOMKilledとか出る。requests/limits見直し - probe失敗(起動に時間かかるのにreadiness/livenessが厳しすぎ)
→
startupProbeを入れる or 初期猶予を伸ばす(前章のprobe知識が活きる❤️🩹)
2-4) “直ったか確認”の儀式 ✅🎉
kubectl get pods -o wide
kubectl describe pod crashloop-sample
kubectl logs crashloop-sample --previous
- Readyが
1/1になった? - Eventsが落ち着いた?
--previousに致命ログが残ってない?
2-5) 2026っぽい小ネタ(CrashLoopの“仕様”が言語化された)📌
v1.35系のPod Lifecycleドキュメントでは、CrashLoopBackOffの仕組み(指数バックオフ・リセット条件など)がかなり明確に整理されています🧠 「なぜ間隔がどんどん伸びるの?」って疑問がスッと消えます😄(Kubernetes)
3) Pending 道場 ⏳🚧(“スケジュールできない”)

Pendingは一言でいうと👇 **「実行する席(ノード)が決まらない/座れない」**状態です🪑💦
3-1) わざとPendingにする(CPU要求を盛りすぎ)🍚盛りすぎ注意
apiVersion: v1
kind: Pod
metadata:
name: pending-sample
spec:
containers:
- name: app
image: nginx:1.27
resources:
requests:
cpu: "100" # わざと無茶
memory: "256Mi"
kubectl apply -f .\pending.yaml
kubectl get pods -w
3-2) Pendingの最短3手 ✂️
手1:まずEventsを見る(答えが書いてある率高い)📣
kubectl describe pod pending-sample
Events: にだいたいこういうのが出ます👇
FailedSchedulingInsufficient cpu/Insufficient memorynode(s) had taint ...0/3 nodes are availableなど
公式ドキュメントでも、Pendingは describe のイベント確認が基本ムーブです🧭(Kubernetes)
手2:Node側の状況をざっくり見る 🏢
kubectl get nodes
kubectl describe node <node-name>
手3:要求(requests)と条件(nodeSelector/affinity/taint)を疑う🔍
- requestsが強すぎ → まず下げる / Pod数を減らす
- nodeSelector / affinity が厳しすぎ → 合うノードが無い
- taint に弾かれてる → toleration無いと座れない(次の節)
- PVC未バインド → ストレージが確保できず詰む(PV/PVC回の復習💾)
3-3) Pending原因ランキング(体感)🏆
① requests盛りすぎ問題 🍔
複数マシン世界では「みんなの冷蔵庫」なので、取り分宣言が強すぎると席が無い😂 requests/limitsの基本は公式タスクにもまとまってます(Kubernetes)
② taintで弾かれてる問題 🧷
代表例:Control Planeに「アプリ載せるな」taintが付いてる、など。
tolerationが無いPodは NoSchedule で弾かれます🚫(Kubernetes)
③ 条件が厳しすぎ問題(nodeSelector/affinity)🎯
「このラベルのノードにしか置かない!」って言ってるのに、そんなノードが存在しない、よくある🥲
4) NotReady 道場 🚑🧱(“ノードが病んでる”)
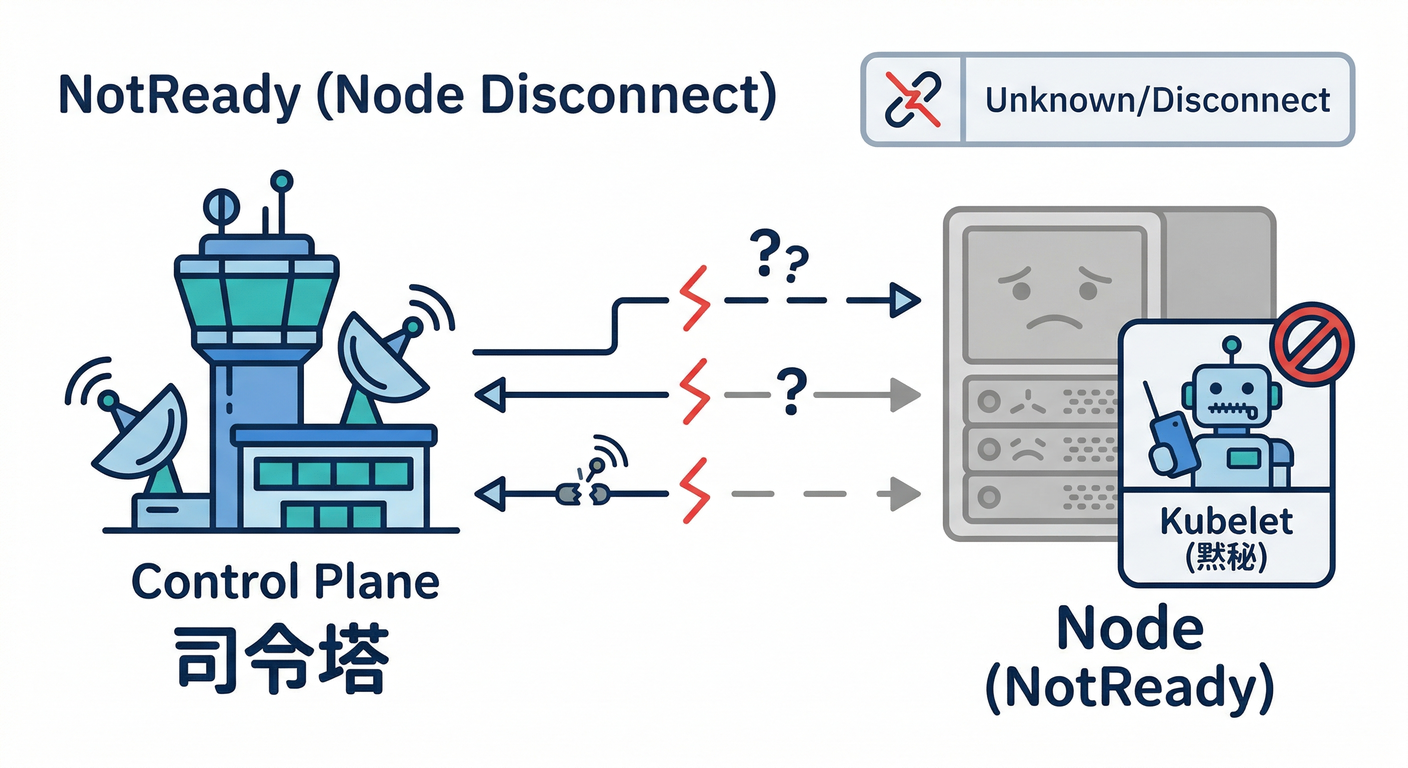
NotReadyは、ざっくり言うと👇 **「そのノードのkubeletがControl Planeに健康報告できてない」**状態です📡💥 GKEのトラブルシュートでも、NotReadyは「kubeletが正しく報告できてない状態」で、新しいPodを載せられなくなって容量が減る=障害につながる、と整理されています(Google Cloud Documentation) またKubernetes公式のクラスタデバッグでも、NotReadyが続くとPodが追い出され得る点に触れています(Kubernetes)
4-1) まずは現象確認 👀
kubectl get nodes -o wide
kubectl describe node <node-name>
Conditions: のここを見る👇
ReadyMemoryPressure/DiskPressure/PIDPressureNetworkUnavailable
4-2) ローカル練習:kindなら“ノード停止”で再現できる 🧪(任意)
kindはノードがDockerコンテナなので、止めるとそれっぽく再現できます😈 (※普段の環境を壊したくない人は読み物としてOK)
docker ps --format "table {{.Names}}\t{{.Status}}"
## 例: kind-worker, kind-control-plane などが見える
docker stop kind-worker
kubectl get nodes -w
4-3) NotReadyの原因“あるある”と復旧の方向性🧯
- ノードが落ちてる/ネットワーク不通 → そのノードが復帰するまで待つ or 再起動 or 交換
- ディスク逼迫(DiskPressure) → ログ/イメージが溜まりすぎ、など
- コンテナランタイム/kubeletが死んでる → “kubeletが報告できない”系(NotReadyの本丸)(Google Cloud Documentation)
ローカル学習では「ノード(VM/コンテナ)再起動」で戻ることが多いですが、本番だと **ノード交換(自動修復)**が基本戦略になります🛠️(ここは第30章の運用ロードマップにつながる🗺️)
5) “最後の切り札” kubectl debug(エフェメラルコンテナ)🪄🕵️♂️
アプリのコンテナが distroless とかで「シェル無い!curl無い!」って時、普通に中に入れなくて詰みます😂
そんな時に kubectl debug で デバッグ用コンテナを横付けできます🚀
公式ドキュメントに手順がまとまっています(Kubernetes)
例(BusyBoxを一時的に差し込むイメージ)👇
kubectl debug -it crashloop-sample --image=busybox:1.36 --target=app
--targetは「同じPod内の対象コンテナの名前」を指定する用途(環境によって要否あり)- ここで
nslookup/wget/cat /etc/resolv.confみたいな“現場チェック”ができます🧰
6) チートシート(この章の持ち帰り)🧾✨
CrashLoopBackOff の型 💥
kubectl describe pod <pod>kubectl logs <pod> --previous- 原因分類:アプリ/設定/リソース/probe (公式の整理がこの順で効く)(Kubernetes)
Pending の型 ⏳
kubectl describe pod <pod>のFailedSchedulingを読む- requests / nodeSelector / taint / PVC を疑う
kubectl describe node <node>で根拠を取る(Kubernetes)
NotReady の型 🚑
kubectl describe node <node>の Conditions/Events- Pressure系(Disk/Memory/PID)か、kubelet報告断かを切る
- ローカルはノード再起動、本番はノード交換が基本線(Google Cloud Documentation)
7) AIに投げる用テンプレ(コピペOK)🤖🧠
-
CrashLoop用:
- 「以下は
kubectl describe podとkubectl logs --previousです。原因候補を3つ、それぞれ 確認コマンドと 直し方もセットで出して」
- 「以下は
-
Pending用:
- 「この
FailedSchedulingのEventsを読んで、最も可能性が高い原因と、マニフェスト修正案を出して」
- 「この
-
NotReady用:
- 「この
kubectl describe nodeのConditionsとEventsから、疑う順番を作って。ローカル(kind/minikube)前提の対処も添えて」
- 「この
次の第29章(Helm 4 / Kustomize)に進む前に、ここで一度だけ自分にご褒美をあげてください🍰 **CrashLoop/Pending/NotReadyを“意図的に作って”→“最短で直す”**を1周すると、Kubernetesが一気に怖くなくなります😆🥋