第17章:HPAでオートスケール(負荷で増える)📈🔥
この章は「アクセスが増えたらPodが増える😆」「落ち着いたら減る😴」を、目で見て体験する回だよ〜!
1) HPAってなに?🤔(超ざっくり)
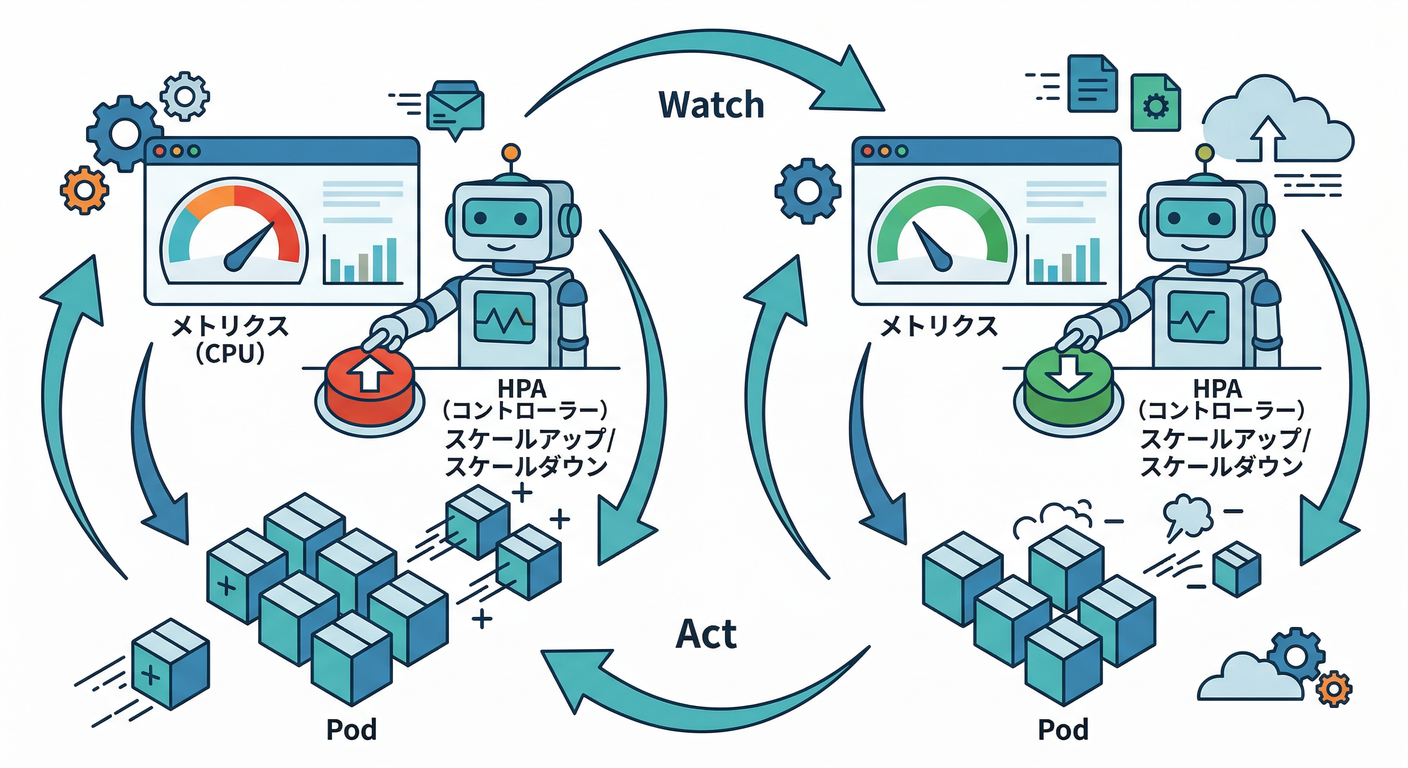
**HPA(HorizontalPodAutoscaler)**は、Deploymentなどの「Podの数」を、**メトリクス(例:CPU使用率)**を見て自動で増減してくれる仕組みだよ📈📉
コントローラは定期的にメトリクスを見て、必要なら .spec.replicas を書き換える感じ(デフォは 15秒周期)。(Kubernetes)
2) 今日の最重要ポイント🔑:「動く条件」が2つある
✅ 条件A:Metrics API が必要(だいたい metrics-server)
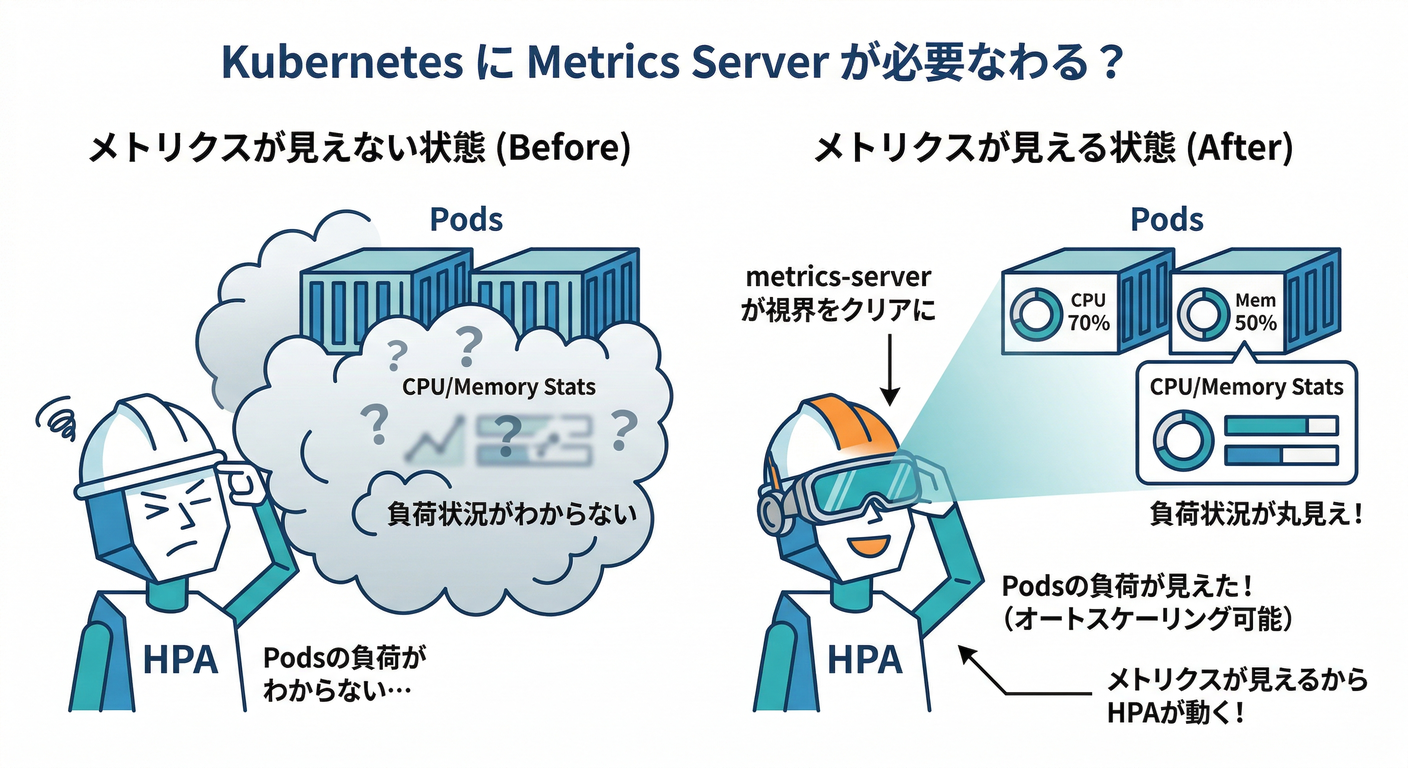
HPAがCPU/メモリなどのリソースメトリクスを見るには、クラスタに Metrics API(metrics.k8s.io) が必要で、一般的には metrics-server を入れるよ。(Kubernetes)
✅ 条件B:CPUの「requests」を書かないと、CPU%でスケールできない
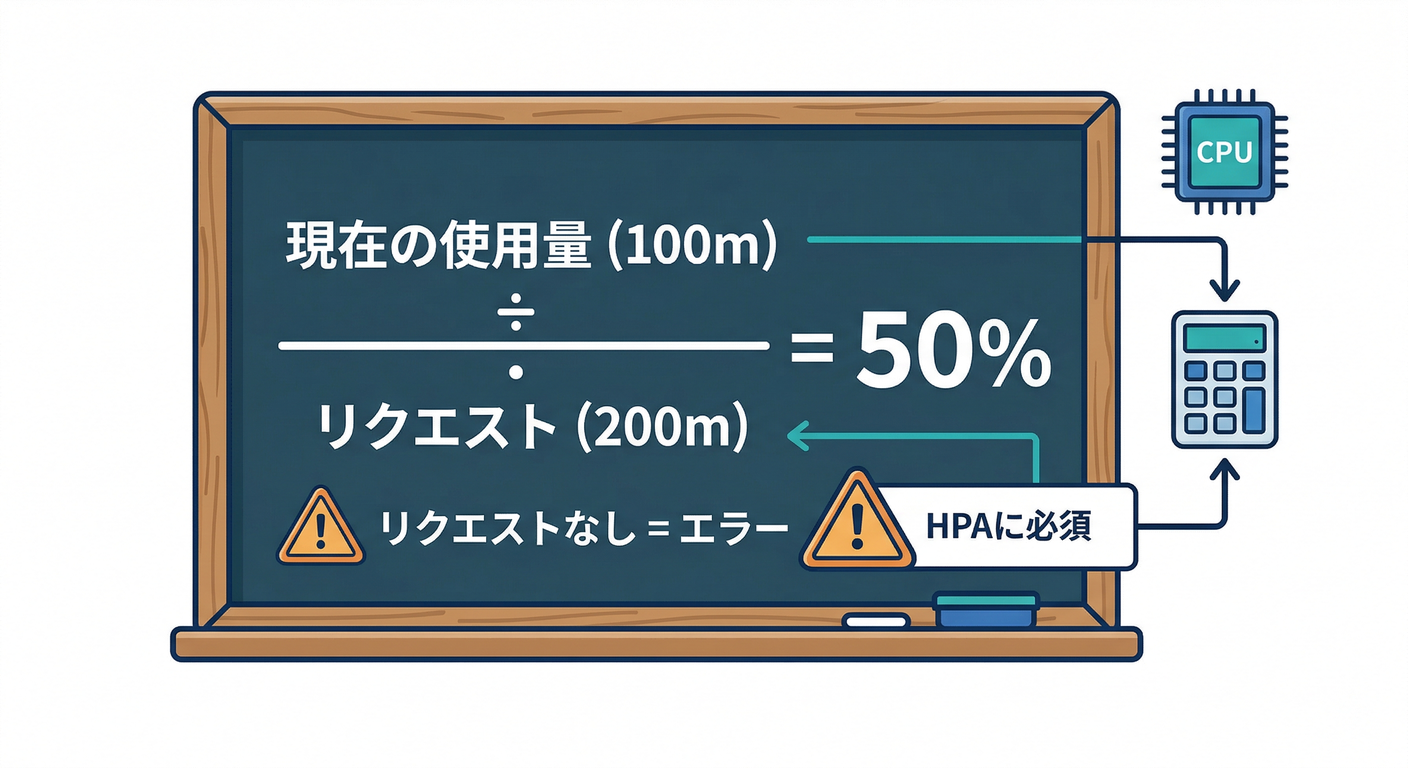
CPU使用率(%)は requests に対する比率で計算されるから、requests未設定だとHPAは動けない(メトリクスが取れない/計算できない)ことがあるよ。(Kubernetes)
3) ハンズオン🧪:公式サンプルで「増える瞬間」を見る(最短ルート)🚀
公式ドキュメントのウォークスルーは、registry.k8s.io/hpa-example を使って「CPU負荷→増える」を体験できるように作られてるよ。(Kubernetes)
3-0) metrics-server を有効化する🧰
A) minikube の場合(超ラク)😺
公式でもこの方法が案内されてるよ。(Kubernetes)
minikube addons enable metrics-server
B) それ以外(kindなど)📦
metrics-server の公式手順(マニフェスト適用)だよ。(GitHub)
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
入ったか確認👇(top が動けば勝ち)✨
kubectl top nodes
kubectl top pods -A
もし
kubectl topが「Metrics API not available」系でコケたら、まずkube-systemの metrics-server Pod を見よう👀
kubectl -n kube-system get pods | findstr metrics
kubectl -n kube-system logs deploy/metrics-server
3-1) サンプルアプリ(Deployment + Service)を立てる🍜
公式の例をそのまま使うのが一番早い!(Kubernetes)
kubectl apply -f https://k8s.io/examples/application/php-apache.yaml
このマニフェストは requests/limits が最初から入ってる(HPA向き)よ。(Kubernetes)
3-2) HPAを作る📈
CPU 50% を目標に、1〜10 Pod の範囲で増減させるよ。(Kubernetes)
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10
状態を見る👇(watchで追いかけるの楽しい😆)
kubectl get hpa
kubectl get hpa php-apache --watch
3-3) 負荷をかける🔥(別ターミナル推奨)
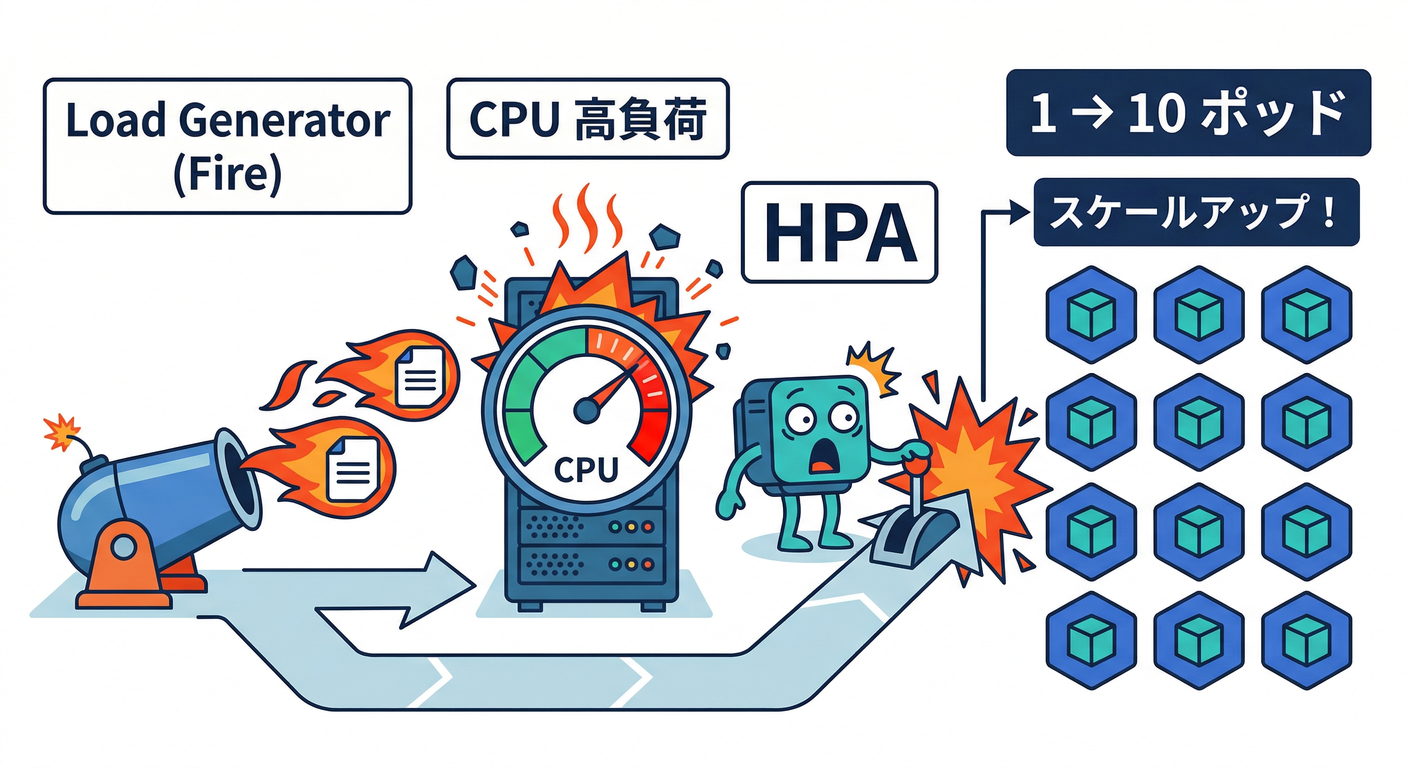
公式の負荷生成コマンド(busyboxで無限アクセス)だよ。(Kubernetes)
kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"
別ターミナルで watch してると、こんな感じで TARGET が跳ねて → REPLICAS が増えるはず!(Kubernetes)
- 例:
305% / 50%みたいに上がる - その後、
REPLICASが 1 → 7 みたいに増える
3-4) 負荷を止めて、スケールインを見る😴
負荷生成ターミナルで Ctrl + C で止める → しばらくすると REPLICAS が減って戻るよ。(Kubernetes)
4) 「CPU%って何%?」の腹落ち🍞
--cpu-percent=50 は、ざっくり言うと **「requests に対して平均50%くらいに保て」**って意味だよ。
公式例だと、各Podが requests: cpu: 200m なので、50% は平均 100m くらいを狙う、みたいな説明になってる。(Kubernetes)
5) autoscaling/v2 で「暴れないHPA」にする🧘♀️(フラッピング対策)
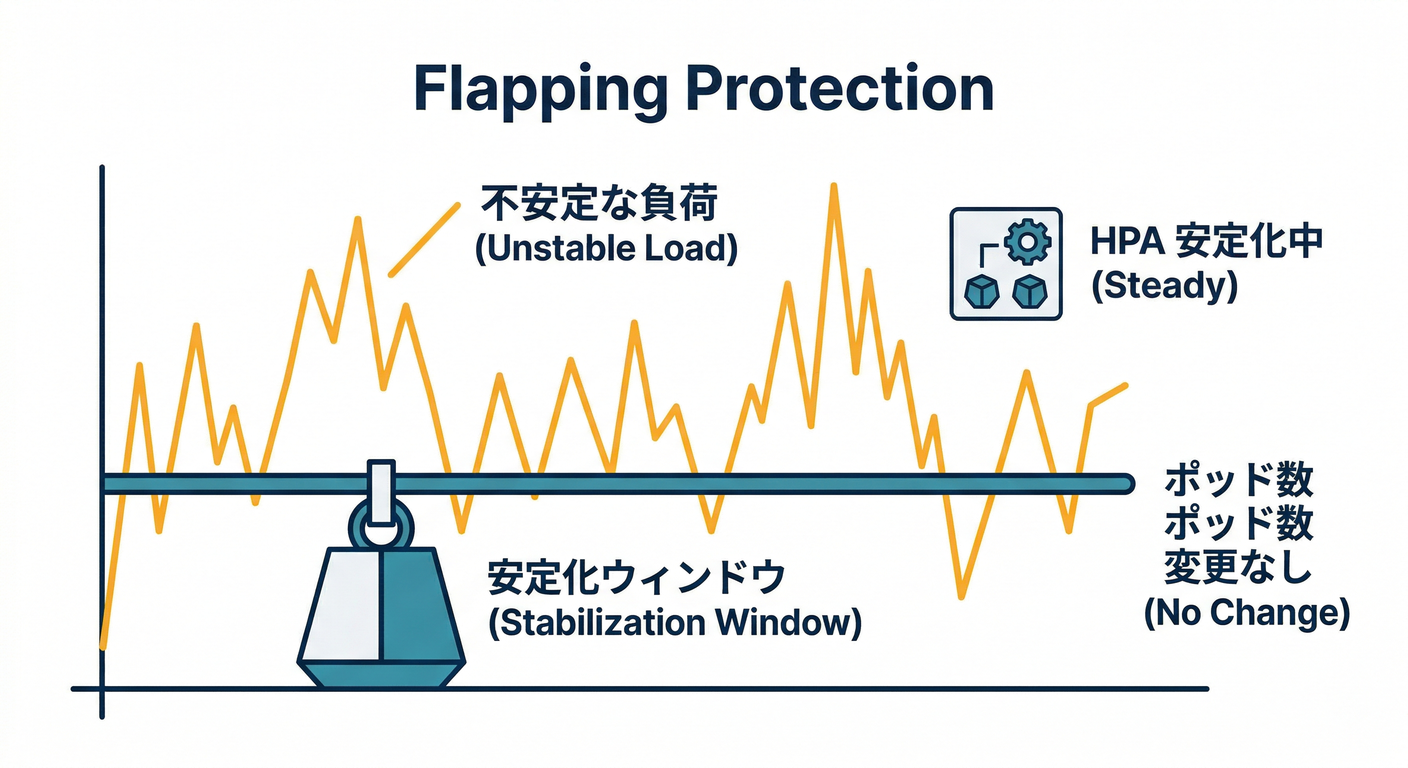
負荷が細かく上下すると、Podが増えたり減ったりして落ち着かないことがある(フラッピング)😵
autoscaling/v2 の behavior で、
- 安定化ウィンドウ(stabilizationWindowSeconds)
- スケール速度の上限(policies)
を調整できるよ(v1.23で安定扱い)。(Kubernetes)
例:スケールダウンを“ゆっくり”にする(学習用の例)
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: php-apache
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: php-apache
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
behavior:
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 10
periodSeconds: 60
- 過去5分の“高い方”を採用して、急に減らしすぎない感じになるよ。(Kubernetes)
6) よくある詰まりポイント集😇➡️😇(ハマりどころ救急箱🧰)
❌ kubectl top が動かない
- ほぼ metrics-server 未導入 / 未稼働。まずここ!(Kubernetes) チェック👇
kubectl -n kube-system get pods | findstr metrics
kubectl -n kube-system logs deploy/metrics-server
kubectl get apiservice | findstr metrics
❌ HPAのTARGETが <unknown> のまま
- Metrics API が取れてない or requests未設定のどちらかが多いよ。(Kubernetes)
まず
kubectl describe hpa php-apacheの Events を見よう👀
kubectl describe hpa php-apache
❌ Podは増えたのに、Pending が出る
- これは「スケジュールできる場所がない」現象😵(ノードの空きが足りない)
kubectl describe podで理由が出るよ👇
kubectl get pods
kubectl describe pod <PendingのPod名>
7) AIで楽するポイント🤖✨(ここ超効く)
kubectl describe hpa ...を貼って「今スケールしない理由を3つ」って聞く🕵️- HPAの
behaviorを「安全寄り(減らすの遅く、増やすの早く)」みたいな要件で提案させる🧠 requests/limitsの値を「このAPIは軽い/重い」前提で相談して、まず雑に置く→動かしながら調整🎛️
8) ミニ課題🎓📝(手が動くやつ)
--cpu-percent=30にしたら、増え方はどう変わる?🤔max=3にしたら、TARGETが高いままでも頭打ちになるのを確認👀behavior.scaleDown.stabilizationWindowSecondsを 0 / 300 で比較してみる🧪(体感できる)
9) お片付け🧹
kubectl delete hpa php-apache
kubectl delete -f https://k8s.io/examples/application/php-apache.yaml
次の章(Job/CronJob)に行く前に、もし「自分のNode/TS API(第7〜8章のアプリ)でもHPAしたい!」なら、**そのDeploymentのYAML(resources部分つき)**を貼ってくれたら、HPA化の最短ルートに整えて返すよ😆💪