第18章:Job/CronJob(バッチと定期実行)⏰🧑🍳📦
今日は「ずっと動くWeb/API」じゃなくて、“やることやって終わる裏方” をKubernetesで回せるようになります 🎉 たとえばこんなやつ👇
- 🧹 毎晩3時に「期限切れデータ掃除」
- 🧾 毎朝7時に「レポート生成」
- 💾 毎時0分に「バックアップ」
- 📩 5分おきに「キューの未処理を処理」
1) Job と CronJob のざっくり違い 🧠✨

- Job:1回きりの “バッチ実行” 🏃♂️💨 → ✅終わったら終了
- CronJob:スケジュールに従って “Jobを定期的に作る” ⏱️ → Jobを量産する係
Kubernetes公式でも「Jobは完了まで実行し、必要なら失敗したPodをリトライする」って説明されています。(Kubernetes) CronJobは「繰り返しスケジュールでJobを起動する」仕組みです。(Kubernetes)
2) まずは “1回だけ” 動く Job を作る 🧪✅
✅ ゴール
- Jobを apply → 実行 → logs確認 → 後片付け、の流れを体に入れる 💪😺
job-hello.yaml(最小のJob)
apiVersion: batch/v1
kind: Job
metadata:
name: hello-job
spec:
template:
spec:
containers:
- name: hello
image: busybox:1.36
command: ["/bin/sh", "-c", "date; echo 'Hello Job 👋'; sleep 2; echo 'Bye 👋'"]
restartPolicy: Never
実行コマンド
kubectl apply -f job-hello.yaml
kubectl get jobs
kubectl get pods -l job-name=hello-job
kubectl logs -l job-name=hello-job
🧠 ここがポイント
restartPolicyは Jobの性格に直結します(よく使うのはNeverorOnFailure)。- Jobは「完了」しても Podが残ることがあるので、ログが見やすい反面、放置すると増えます(後でちゃんと片付けます🧹)。
3) “失敗したらどうなる?” をわざと体験する 😈➡️😇
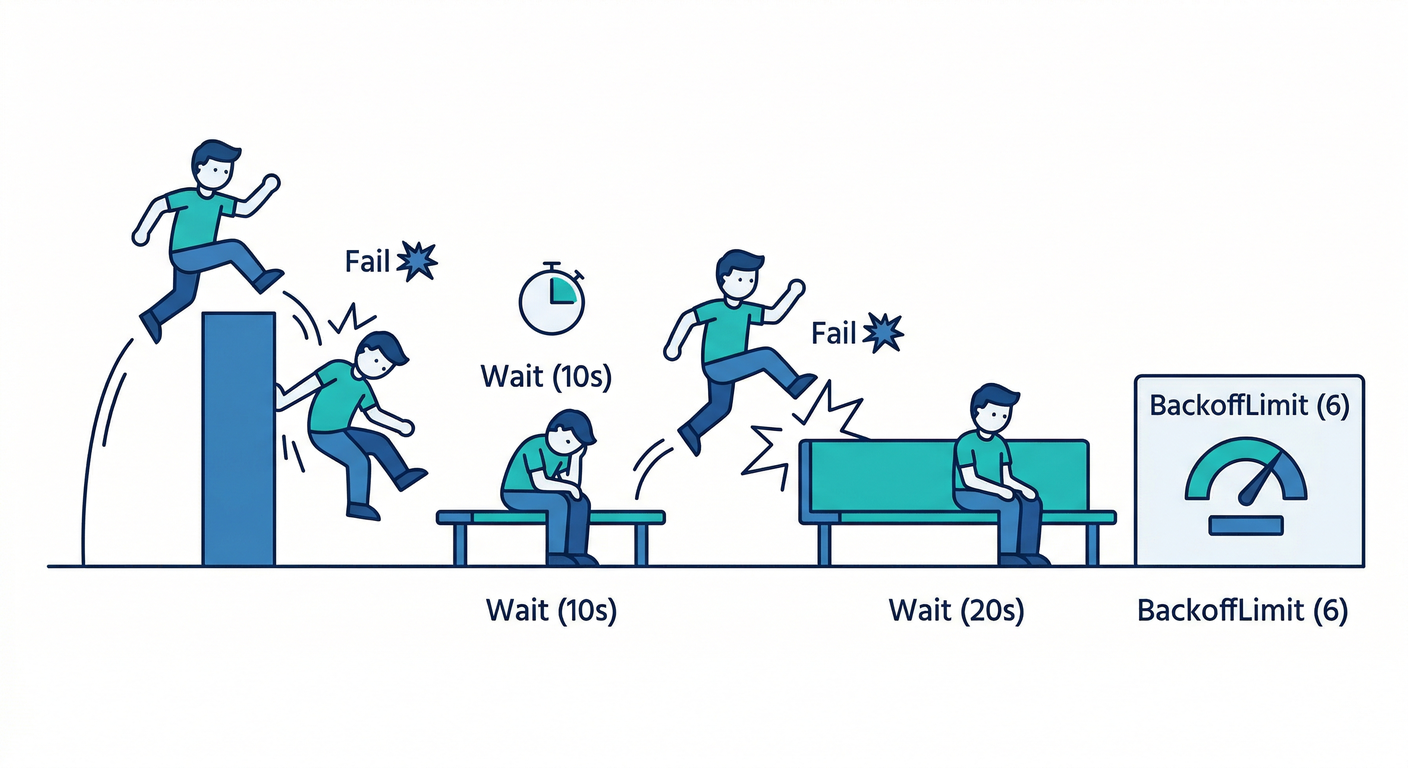
Jobは失敗すると、リトライします。
その回数の上限が backoffLimit で、デフォルトは 6 です。(Kubernetes)
job-fail-sometimes.yaml(2回失敗してから成功する例)
Nodeでやると「Exit codeで遊べて」わかりやすいです 😺 (2026-02時点で Node v24 が Active LTS 扱いなので、学習用途でも安心枠 🧷)(Node.js)
apiVersion: batch/v1
kind: Job
metadata:
name: flaky-job
spec:
backoffLimit: 4
template:
spec:
containers:
- name: main
image: node:24-alpine
command:
- /bin/sh
- -c
- |
node -e "
const fs=require('fs');
const p='/tmp/trycount';
const n=(fs.existsSync(p)?Number(fs.readFileSync(p,'utf8')):0)+1;
fs.writeFileSync(p,String(n));
console.log('try=',n);
if(n<3){ process.exit(42); } // 2回失敗
console.log('success 🎉');
"
restartPolicy: Never
観察コマンド
kubectl apply -f job-fail-sometimes.yaml
kubectl get pods -l job-name=flaky-job -w
kubectl logs -l job-name=flaky-job --tail=200
kubectl describe job flaky-job
🧠 “タイムアウト”も欲しい:activeDeadlineSeconds ⏳
Jobがダラダラ走り続けるのは困るので、時間で打ち切ることもできます。
activeDeadlineSecondsは 全体の実行時間に効く- しかも activeDeadlineSeconds は backoffLimit より優先されます (Kubernetes)
例(60秒超えたら失敗にする)👇
spec:
activeDeadlineSeconds: 60
backoffLimit: 10
4) 後片付け(超重要)🧹✨:TTL で Job を自動削除する
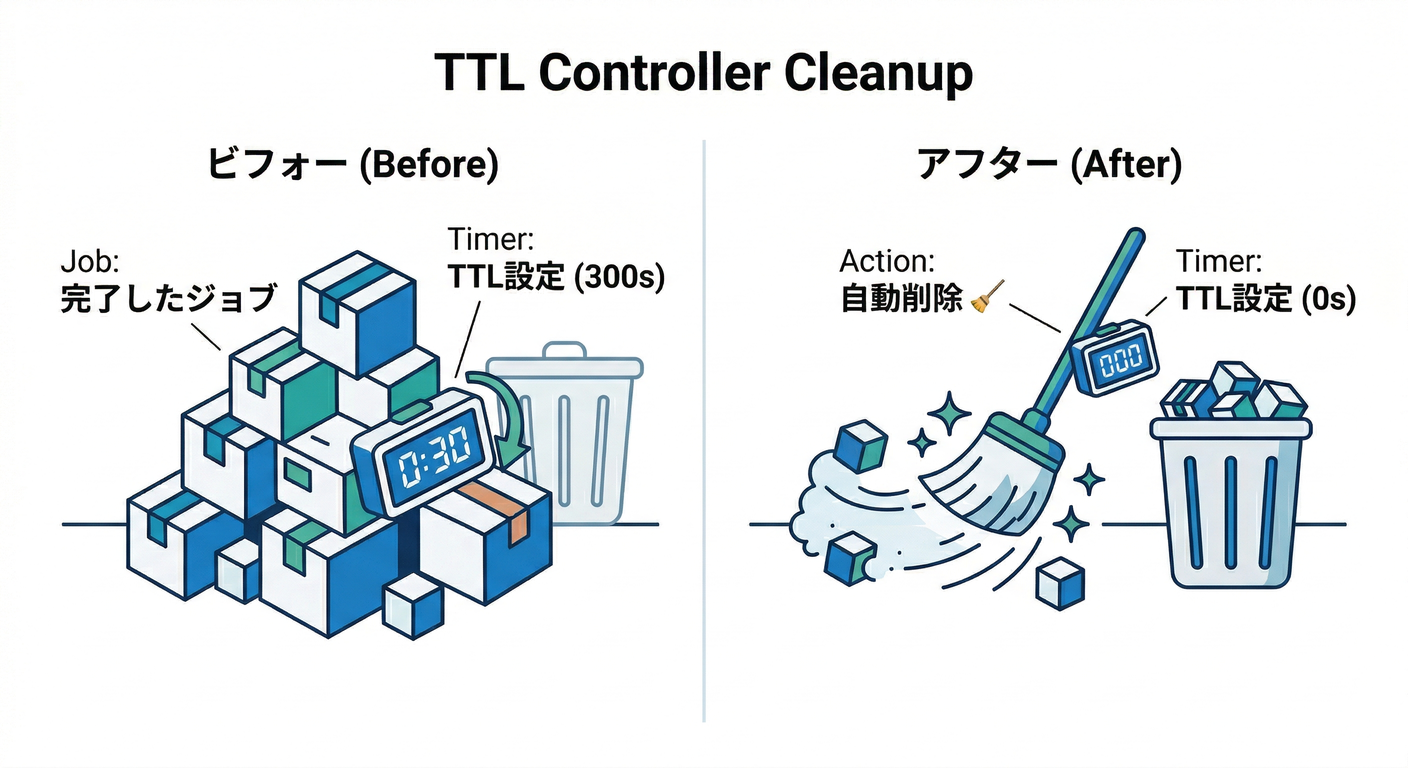
Jobは放置すると溜まります 😇💦
そこで ttlSecondsAfterFinished!
- Job完了後、指定秒数で Jobと関連Podが自動削除されます
- これは v1.23でstableです (Kubernetes)
例(完了後5分で消す)👇
spec:
ttlSecondsAfterFinished: 300
5) CronJob:定期実行の本体へ ⏰🚀
CronJobの重要フィールドはこれ👇(覚える順に並べたよ🧠)
(1) schedule:いつ動かす?🗓️
spec.scheduleはcron形式- CronJobの基本は公式ドキュメントどおりです (Kubernetes)
例:
- 毎分:
*/1 * * * * - 毎日3:05:
5 3 * * *
(2) timeZone:タイムゾーン地獄を回避 🌏⚠️
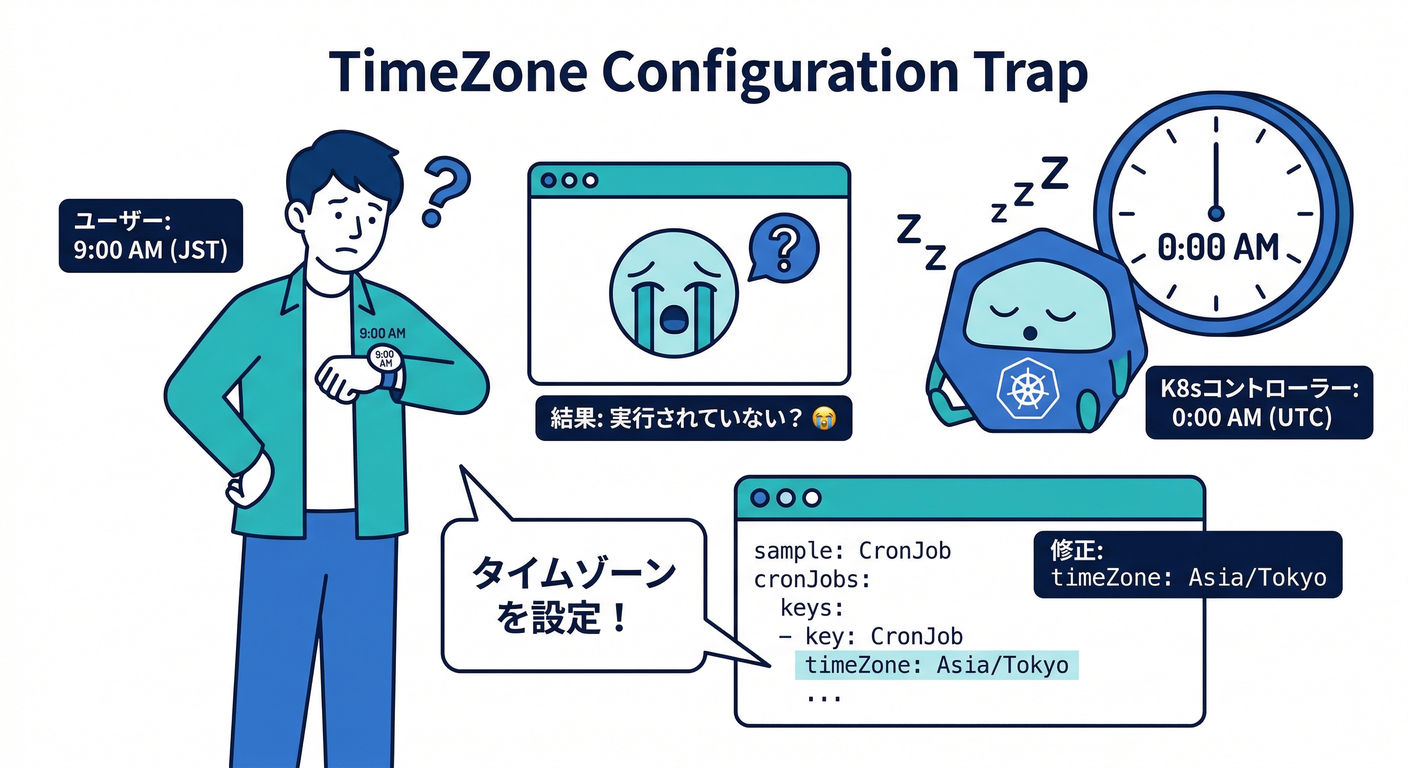
- v1.27で stable
- 指定しないと
kube-controller-managerのローカルTZで解釈されます (Kubernetes) → 管理環境だとUTCだったりして「思ってた時間と違う😇」が起きがち
例(日本時間で解釈させる)👇
spec:
timeZone: "Asia/Tokyo"
⚠️ TZ= や CRON_TZ= を schedule に埋め込むのは 非サポートで、バリデーションエラーになります(公式が明言)。(Kubernetes)
(3) concurrencyPolicy:重なったらどうする?🧯
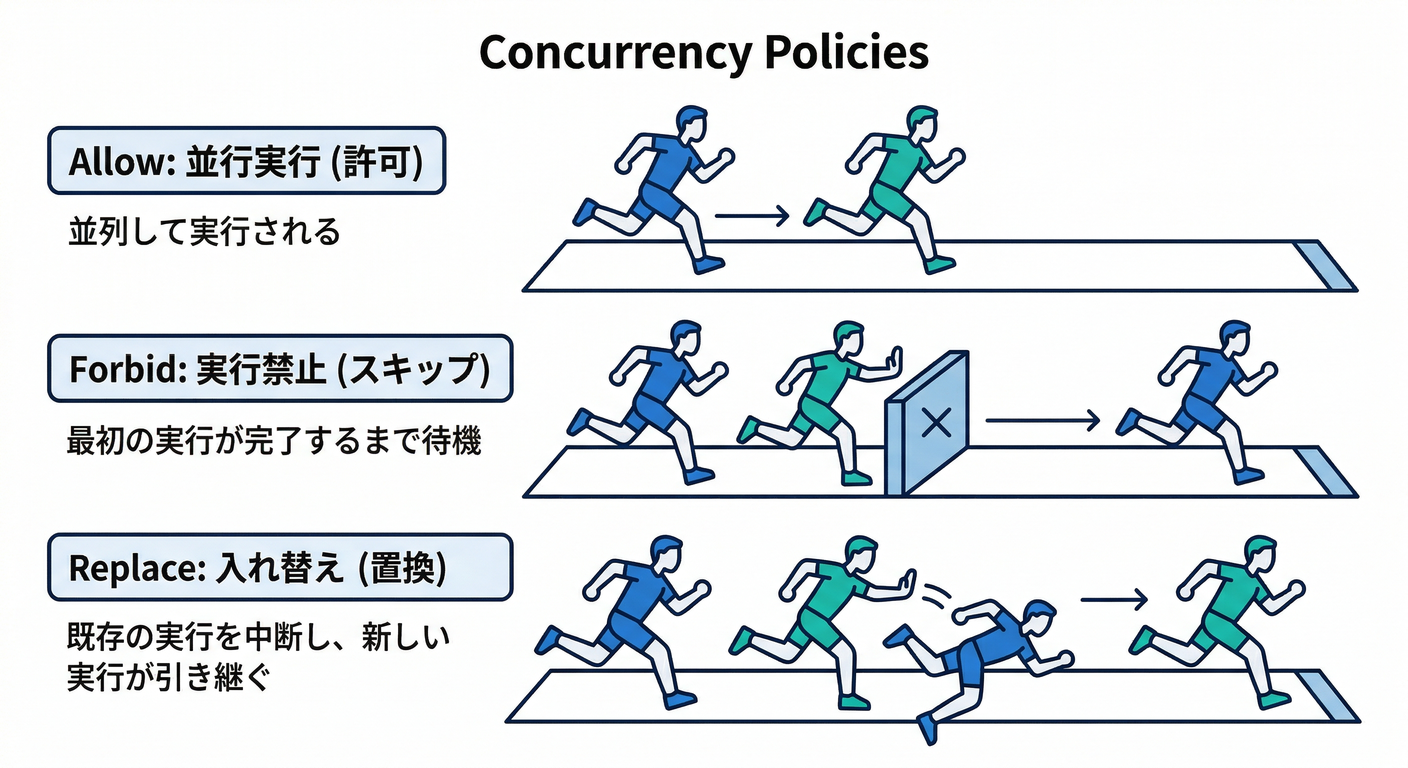
Allow(デフォルト): 重なっても両方走るForbid: 前のJobが走ってたら次をスキップReplace: 前のJobを止めて新しいのに入れ替え
この挙動は公式の “Concurrency policy” にまとまっています。(Kubernetes)
(4) startingDeadlineSeconds:取りこぼしをどこまで許す?⌛
コントローラ停止や時計ズレなどで「予定時刻に作れなかったJob」を、あとから追いかけて作る(catch-up)ことがあります。
その“追いかけ許容時間”が startingDeadlineSeconds です。(Kubernetes)
(5) suspend:一時停止 💤
spec.suspend: trueにすると、その後の起動を止められます (Kubernetes)- ただし注意:停止中に“実行できなかった分”が missed job として数えられ、条件次第で 解除した瞬間にまとめて走ることがあります(公式が注意書きしてます)。(Kubernetes)
(6) history limits:履歴が増えすぎ防止 🧾🧹
successfulJobsHistoryLimit/failedJobsHistoryLimit- 成功のデフォルトは 3 (Kubernetes)
6) ハンズオン:日次の掃除タスクを CronJob で回す 🧹⏰
やりたいこと(学習用)
- 毎日 03:05(日本時間)に動く
- 重なり禁止(Forbid)
- 取りこぼしは 10分まで
- 成功1件・失敗1件だけ残す
- Job完了後 10分で自動削除(TTL)
cronjob-cleanup.yaml
apiVersion: batch/v1
kind: CronJob
metadata:
name: daily-cleanup
spec:
schedule: "5 3 * * *"
timeZone: "Asia/Tokyo"
concurrencyPolicy: Forbid
startingDeadlineSeconds: 600
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 1
jobTemplate:
spec:
ttlSecondsAfterFinished: 600
backoffLimit: 2
template:
spec:
containers:
- name: cleanup
image: node:24-alpine
command:
- /bin/sh
- -c
- |
echo "cleanup start 🧹"
node -e "console.log('delete expired sessions... (dummy)');"
echo "cleanup done ✅"
restartPolicy: Never
実行&観察
kubectl apply -f cronjob-cleanup.yaml
kubectl get cronjob daily-cleanup
kubectl get jobs --watch
「今すぐ動かしたい!」ってときは次のセクションへ👇😺
7) “今すぐ1回だけ” 手動実行したい(CronJob → Job)🕹️
kubectl create job は CronJob からJobを作れます(公式の例にもあります)。(Kubernetes)
kubectl create job manual-cleanup --from=cronjob/daily-cleanup
kubectl logs -l job-name=manual-cleanup
8) トラブルシュート(よくある事故TOP7)🥋💥

-
⏰ 時間がズレる →
timeZoneを明示しよう(v1.27 stable)。(Kubernetes) -
🧟 Jobが増え続ける →
ttlSecondsAfterFinishedと history limits を入れる。(Kubernetes) -
🌀 同時に複数走って二重処理 →
concurrencyPolicy: Forbidをまず検討。(Kubernetes) (設計的には「二重に走っても壊れない=冪等」が理想だけど、まずはForbidで安全柵😺) -
💤 suspend解除した瞬間にドドド! →
startingDeadlineSecondsを入れて“取りこぼし回収”を制限。(Kubernetes) -
🧨 失敗時にリトライしすぎる/しなさすぎる →
backoffLimitを調整(デフォルト6)。(Kubernetes) -
⛔ 長時間ハングする →
activeDeadlineSecondsで時間制限(backoffLimitより優先)。(Kubernetes) -
🤯 「失敗扱い」にしたい条件が複雑 →
podFailurePolicyを検討(ただしrestartPolicy: Neverが必須)。(Kubernetes)
9) AI(Copilot / Codex)に任せると強いところ 🤖✨
- 🗓️ cron式が不安 → 「毎週月曜の9:30をcronで」みたいに聞く
- 🧾 YAMLレビュー → 「このCronJob、事故りそうな点ある?」
- 🧪 失敗シナリオ作り → 「わざと失敗してbackoff挙動を観察したい。Job例作って」
- 🧠 設計相談 → 「この処理、二重実行されても安全にするには?」(冪等の考え方をもらう)
10) 章末ミニ課題 🎒📝
daily-cleanupを「5分おき」に変えて、concurrencyPolicyをAllowにしてみる(重なったらどうなる?)😈suspend: true→ しばらく待つ →falseに戻す。startingDeadlineSecondsの有無で挙動の差を見る 👀(Kubernetes)ttlSecondsAfterFinishedを 30秒にして、Jobが自動で消えるのを確認する 🧹(Kubernetes)
まとめ 🧠✨
- Job:1回実行して終わるバッチ 🧑🍳
- CronJob:スケジュールでJobを作る係 ⏰
- 事故りやすいポイントは 時間(timeZone) と 重なり(concurrencyPolicy) と 掃除(TTL/履歴制限) 🧹
- “取りこぼし回収”は便利だけど、設定次第で暴発するので
startingDeadlineSecondsで柵を作るのが安心 😺(Kubernetes)
次の第19章(PV/PVC)に行くと、ここで作ったCronJobが「本当にバックアップとして意味を持つ」ようになります 💾🚀