第14章:Rolling UpdateとRollback(安全に更新)🔄🛟
Kubernetes の Deployment は「止めずに更新する(Rolling Update)」と「やっぱ戻す(Rollback)」が標準装備です🎒✨ しかも今は最新が v1.35.1(2026-02-10) なので、学ぶ価値が高いところから押さえていきます💪📚 (Kubernetes)
今日のゴール🎯✨
この章を終えると、次ができるようになります👇
- ローリング更新の仕組みを「図で説明できる」🧠🗺️
- 更新を 安全に見守るコマンドを一通り使える👀⌨️
- わざと壊して(失敗させて)→ 即ロールバックできる🎢🛟
まず超ざっくり:Rolling Updateって何?🤔🔄
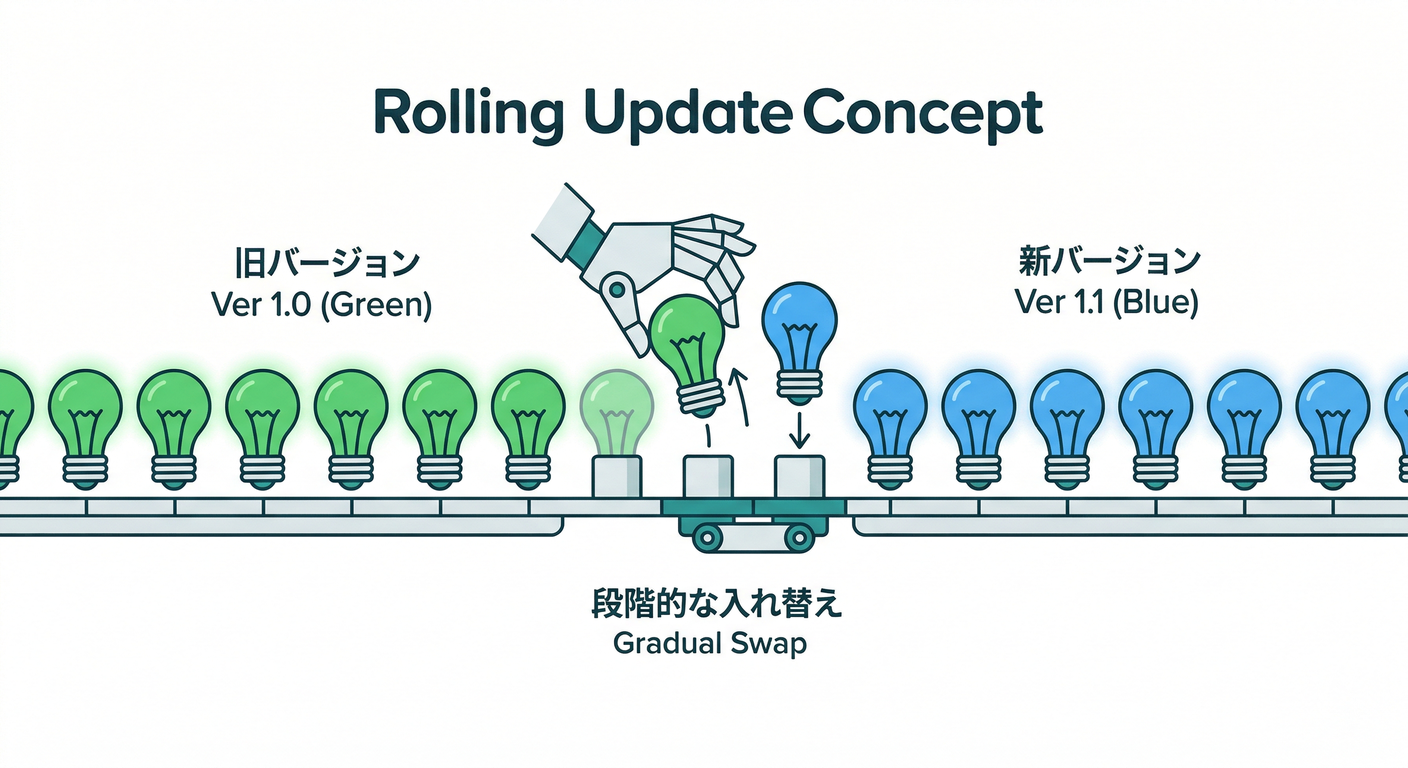
Deploymentを更新すると、裏側ではこうなります👇
- 新しい設定(主に「Podテンプレ」)で 新しいReplicaSet が作られる📦
- 古いPodを少しずつ減らしつつ、新しいPodを少しずつ増やす📉📈
- その“増減の速度”を決めるのが maxSurge / maxUnavailable 🍰📏
Kubernetes公式でも、DeploymentはReplicaSet / Podに対して 宣言型で更新し、制御された速度で実際の状態を近づける…という位置づけです。 (Kubernetes)
重要パラメータ3兄弟👪✨(ここだけで事故が減る!)
1) maxSurge / maxUnavailable(更新の“混み具合”)🚦
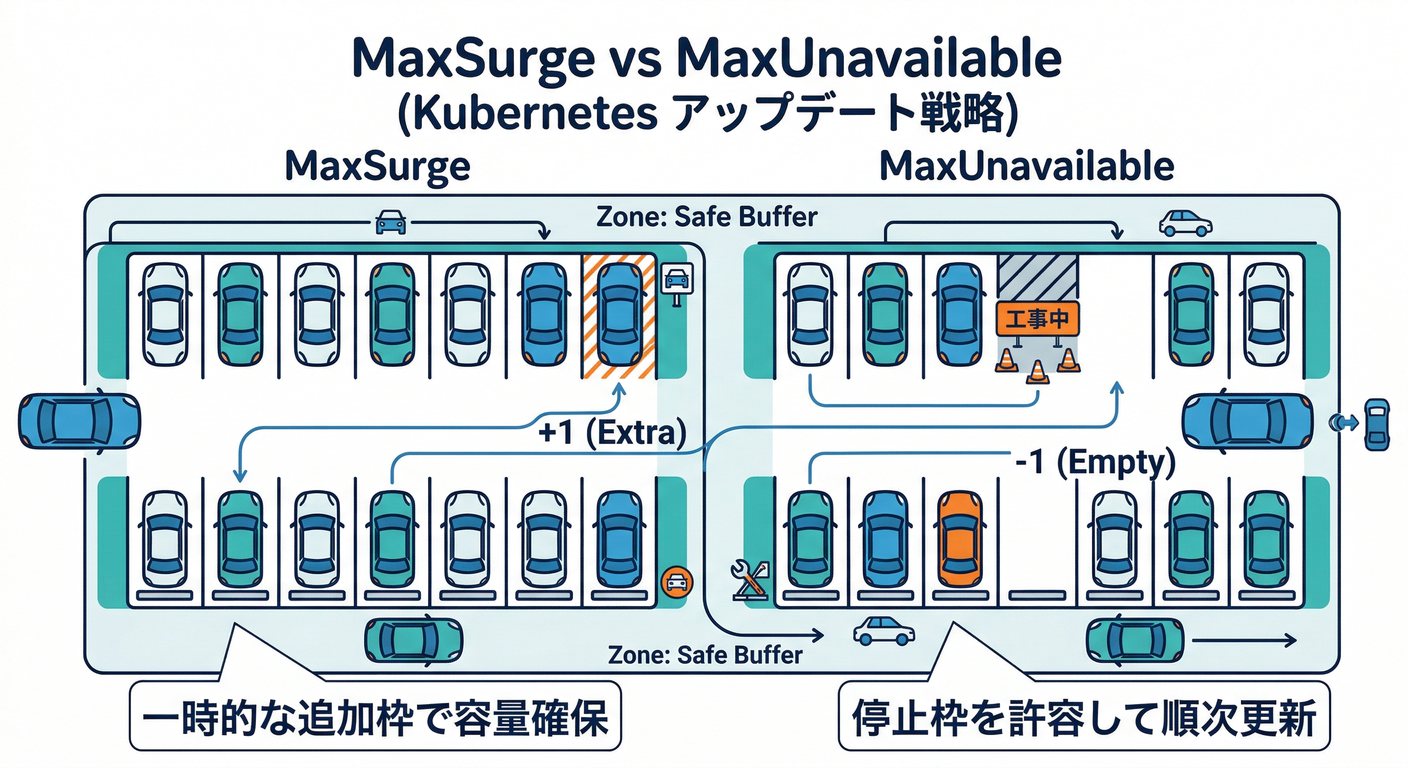
RollingUpdate戦略はこの2つで「安全さ」と「速さ」を調整します🎛️
- maxSurge:一時的に“余分に増やしていいPod数”
- maxUnavailable:一時的に“減ってもいいPod数”
デフォルトは maxSurge 25% / maxUnavailable 25% です(割合でも整数でも指定OK)📌 (Kubernetes)
💡イメージ(replicas=4の例)
- maxSurge=25% → 最大 +1(合計5までOK)
- maxUnavailable=25% → 最大 -1(利用可能3までOK)
2) revisionHistoryLimit(“戻れる回数”)🕰️🛟
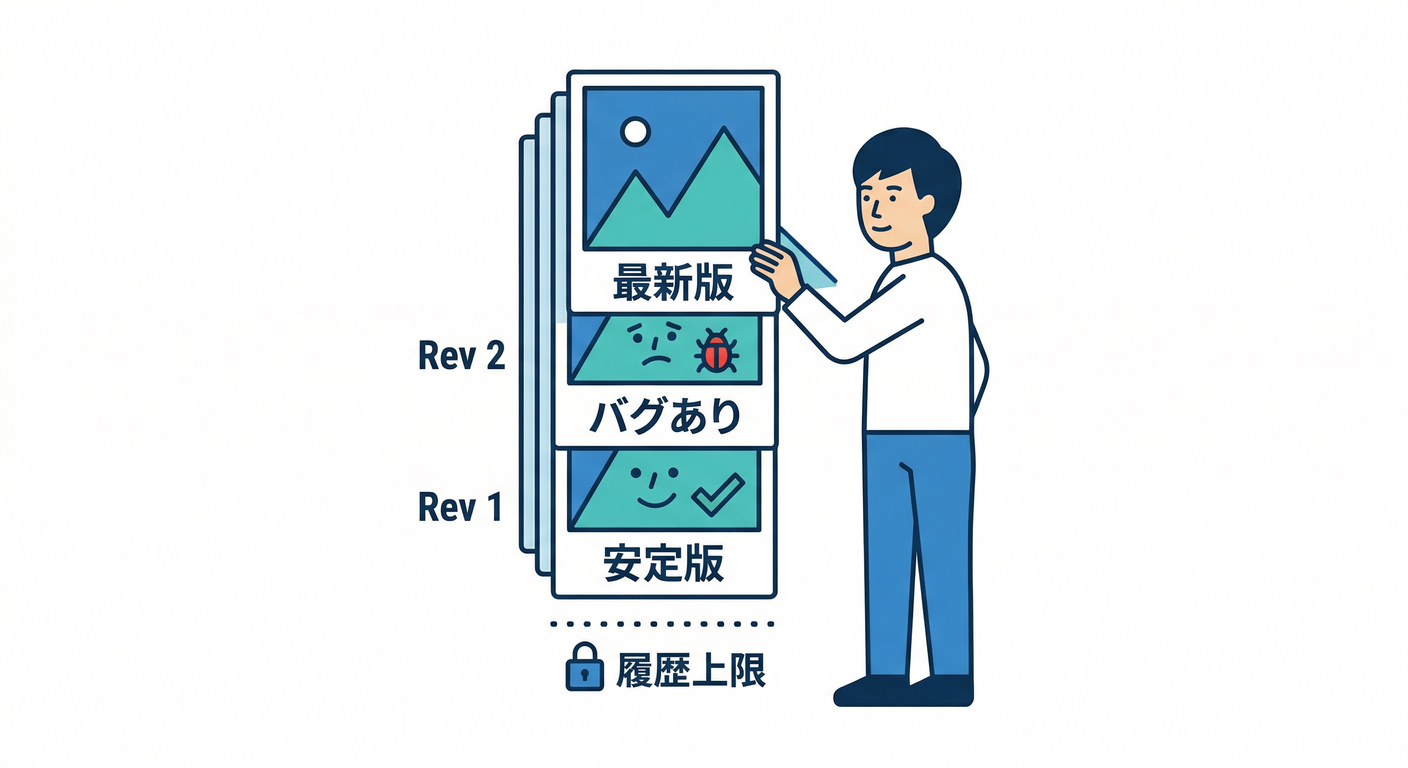
過去のReplicaSetをどれだけ保持するかです。
- デフォルトは 10
- 0にすると履歴を残さないので、基本ロールバックしづらくなります⚠️ (Kubernetes)
3) progressDeadlineSeconds(“いつ諦める?”)⏳🧯
ロールアウトが進まない状態が続いたら「失敗」と判定するタイムリミットです。
- デフォルトは 600秒(10分)
- ちなみに pause中はこの判定が止まるので、ゆっくり調査したい時に便利です🕵️♀️🧊 (Kubernetes)
ロールアウト観測の“神コマンド”セット👀⌨️✨
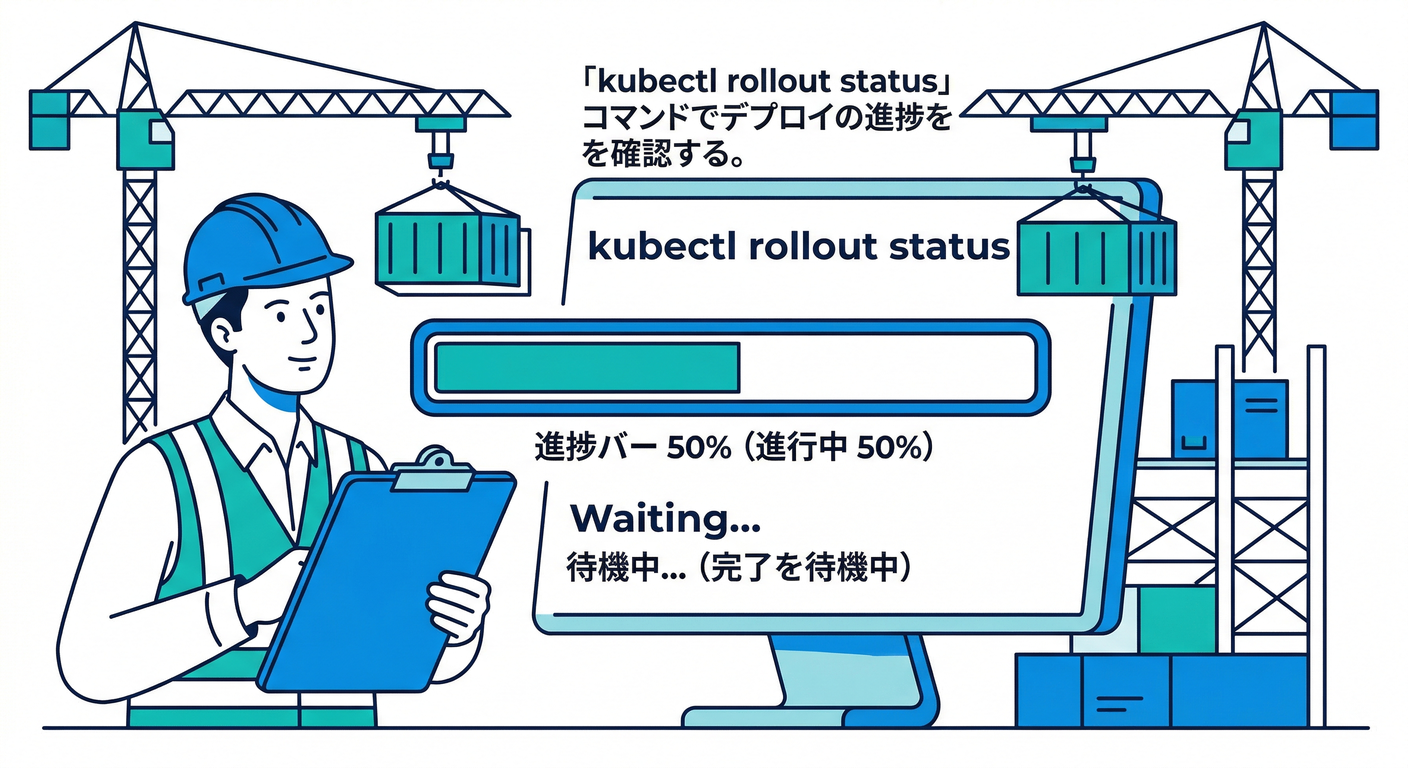
困ったらこの順で見ると強いです👇
- 状態を見る
kubectl get deploy
kubectl get rs
kubectl get pod
- ロールアウトを見守る(超重要)
kubectl rollout status deployment/<デプロイ名>
- 履歴を見る(どこまで戻れる?)
kubectl rollout history deployment/<デプロイ名>
## 詳細(特定リビジョン)
kubectl rollout history deployment/<デプロイ名> --revision=1
(履歴表示自体が公式コマンドとして提供されています) (Kubernetes)
ハンズオン🎮:わざと壊して→即ロールバック🎢🛟(一番覚える)
ここでは “動くもの” が大事なので、例は nginx でいきます🍔 (自作Node/TS APIでも、Deployment名とimageを書き換えれば同じ流れでOKです👌)
STEP 0:サンプルDeploymentを作る🏗️
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-demo
spec:
replicas: 4
revisionHistoryLimit: 10
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 0
selector:
matchLabels:
app: web-demo
template:
metadata:
labels:
app: web-demo
spec:
containers:
- name: web
image: nginx:1.27
ports:
- containerPort: 80
適用👇
kubectl apply -f web-demo.yaml
kubectl rollout status deployment/web-demo
kubectl get pod -l app=web-demo
✅ここでの狙い
- maxUnavailable: 0 → “利用可能Podを減らさない”=無停止寄り😇
- maxSurge: 1 → その代わり“余分に1個だけ増やす”=安全に入れ替え🧷
STEP 1:普通に更新してみる🔄✨
nginxのタグをちょい上げ(例)👇
kubectl set image deployment/web-demo web=nginx:1.28
kubectl rollout status deployment/web-demo
kubectl get rs
👀ポイント
- 新しいReplicaSetが増えて、古いReplicaSetが減っていくのが見えるはずです📦📉📈
STEP 2:わざと壊す😈💥(ImagePullBackOffを起こす)
存在しないタグにして、確実に失敗させます👇
kubectl set image deployment/web-demo web=nginx:9.99-nope
kubectl rollout status deployment/web-demo
たぶん途中で止まります🧊 状態を観察👇
kubectl get pod -l app=web-demo
kubectl describe pod -l app=web-demo
kubectl get rs
kubectl rollout history deployment/web-demo
STEP 3:ロールバック🛟✨(“前の動いてた版”に戻す)
kubectl rollout undo deployment/web-demo
kubectl rollout status deployment/web-demo
kubectl get pod -l app=web-demo
これが基本の戻し方です。--to-revision で狙ったリビジョンにも戻せます🎯 (Kubernetes)
✅大事な注意(ここテストに出る)📌
- **ロールバックも“新しいロールアウト”**として扱われます(履歴が進むことがある)
- DBや外部状態までは戻りません(アプリ側の設計も必要)🧠🧱
「更新が遅い/増えすぎる」って時の正体👻💡
Rolling Update中、**古いPodが終了待ち(graceful shutdown)**だったりすると、思ったよりPodが多く見えることがあります👀💦 公式にも「古いPodが終了中は、望む数より多く見えることがある」系の注意が書かれています。 (Kubernetes)
さらに v1.35 では、Deploymentの .status.terminatingReplicas が導入されて、
「いま終了中のPodが何個いるか」を見やすくする改善も入っています🔍✨ (Kubernetes)
事故りやすい落とし穴トップ5⚠️🕳️
-
imageタグの打ち間違い(今回みたいに即死)🪦
-
readinessProbe無しで“起動途中Pod”にトラフィックが当たる🚑
-
maxUnavailableが大きい → その分だけ同時に落としていい判定になる😱
-
revisionHistoryLimit=0 → 戻りにくくなる🧯
-
変更の記録がなくて「何を戻せばいいか分からない」🤯
- 履歴の“理由”欄に出ることがある
kubernetes.io/change-causeもあるけど、--record依存で挙動が揺れやすいので、Gitのコミット/PRを正とするのが堅いです📌 (annotationの説明) (Kubernetes)
- 履歴の“理由”欄に出ることがある
もう一段安全にする小技3つ🥷✨
1) 一旦止める(pause)🧊
「ちょっと待って!設定を見直したい!」の時に便利👇
kubectl rollout pause deployment/web-demo
pause自体が公式コマンドとして提供されています。 (Kubernetes)
確認して、再開👇
kubectl rollout resume deployment/web-demo
```` :contentReference[oaicite:12]{index=12}
---
## 2) “設定だけ変えた”から再起動したい(restart)🔁
ConfigMap/Secret側を変えて「Podを入れ替えたい」時に便利👇
````bash
kubectl rollout restart deployment/web-demo
kubectl rollout status deployment/web-demo
```` :contentReference[oaicite:13]{index=13}
---
## 3) 無停止寄り設定テンプレ🧷
- **maxUnavailable: 0**(落とさない)
- **maxSurge: 1**(増やして入れ替える)
- readinessProbeをちゃんと入れる❤️🩹
→ これが“最初の鉄板”です🍳✨
---
## AIで楽するポイント🤖✨(コピペでOK)
- 「このDeployment更新、止まった理由を3つ候補で。どのコマンドで確かめる?」🔍
- 「maxSurge/maxUnavailableを、無停止優先・コスト優先の2案で提案して」🍰
- 「rollout status が進まない。describe出力を貼るので原因の優先順位つけて」🧯
- 「ロールバック手順を“作業チェックリスト”化して」✅📝
---
## 理解チェック(ミニクイズ)🧠🎯
1) `maxUnavailable: 0` の強みと弱みは?🍰
2) `revisionHistoryLimit: 0` にしたら何が困る?🛟
3) ロールバックしても **戻らない** 可能性があるものは?(ヒント:DB)🗃️
4) ロールアウトが止まったら、最初に見るべきコマンドは?👀
---
## 宿題(やると強くなる)📚🔥
- replicasを 2 / 4 / 10 に変えて、**同じmaxSurge/maxUnavailable**で更新の挙動がどう変わるか観察する👀
- 故意に「readinessProbe失敗」する設定を入れて、rolloutがどう止まるか見る❤️🩹🧪
- `.status.terminatingReplicas` が出る状況(終了が長いコンテナ)を作って観察してみる🔍✨ :contentReference[oaicite:14]{index=14}
---
次の章(Requests/Limits)へ行く前に、この章のハンズオンを **“壊す→戻す”まで1回通しで**やると、デプロイ恐怖症がだいぶ消えます😌🛟✨
::contentReference[oaicite:15]{index=15}