第13章:Probe(liveness / readiness / startup)で“壊れにくく”❤️🩹☸️
この章は「Kubernetesの自己回復力を“ちゃんと使える人”になる」回です😊 Probe(プローブ)は、超ざっくり言うと Kubernetesがアプリに当てる“体温計” です🌡️
0) この章でできるようになること 🎯✨
- liveness / readiness / startup の役割を、混ぜずに説明できる🧠
- Node/TS API に /livez / readyz / startupz を用意して使い分けできる🧪
- Probeの失敗で起きる現象(再起動 / 切り離し)を 自分で再現 できる😈➡️😇
- 2026の地雷:exec probe の timeoutSeconds を理解して事故を避けられる⚠️ (Google Cloud Documentation)
1) まず“3つの体温計”の違いをつかむ 🌡️🧠
Kubernetes公式の定義はこういう感じです👇(要点だけ噛み砕きます)
- liveness probe:ダメなら 再起動(「固まってる」「進んでない」を疑う)🔁 (Kubernetes)
- readiness probe:ダメなら トラフィックを止める(Serviceの宛先から外す)🚫📮 (Kubernetes)
- startup probe:起動が遅い子を守る(成功するまで liveness/readiness を無効化)🛡️🐢 (Kubernetes)
覚え方(超大事)📝
- liveness = 「生きてる?(死んでたら蘇生)」🧟♂️✨
- readiness = 「今、客を入れていい?」🧑🍳🚪
- startup = 「起動中は怒らないで!」🙏💤
2) Node/TypeScript 側:3つのヘルスエンドポイントを作る 🍔🧩
ここでは例として Express で書きます(他のフレームワークでも考え方は同じ)😊 ポイントは「チェック内容を混ぜない」です🧠✨
/livez:軽い。基本は「プロセスが動いてる」確認(DBチェックとか入れない)🏃♂️💨/readyz:依存先が揃ったらOK(DB接続・キャッシュ温め完了など)🔌✅/startupz:初期化が終わったらOK(起動が遅い場合の保険)🐢🛡️
import express from "express";
const app = express();
const port = Number(process.env.PORT ?? 3000);
// 例:起動後しばらくは ready にしない(学習用)
const readyDelayMs = Number(process.env.READY_DELAY_MS ?? 0);
let isReady = readyDelayMs === 0;
let isAlive = true; // 学習用スイッチ(わざと壊す用)
// 起動直後の“準備中”を再現
setTimeout(() => {
isReady = true;
console.log("[boot] ready ✅");
}, readyDelayMs);
// liveness: とにかく軽く!「固まってない?」の入口
app.get("/livez", (_req, res) => {
if (!isAlive) return res.status(500).send("dead ❌");
return res.status(200).send("ok ✅");
});
// readiness: 依存が揃ったらOK(ここではフラグで代用)
app.get("/readyz", (_req, res) => {
if (!isReady) return res.status(503).send("not ready ⏳");
return res.status(200).send("ready ✅");
});
// startup: 起動が完了したか(ここでは ready と同義でもOK)
app.get("/startupz", (_req, res) => {
if (!isReady) return res.status(503).send("starting ⏳");
return res.status(200).send("started ✅");
});
// 学習用:わざと壊す(本番には置かないでね😇)
app.post("/__kill_livez", (_req, res) => {
isAlive = false;
res.status(200).send("liveness will fail 😈");
});
app.listen(port, () => console.log(`listening on ${port}`));
3) Kubernetes 側:Deployment に probe を足す 🧱🩺
3-1) まず“おすすめ構成”をそのまま貼れる形で ✅✨
- startupProbe:起動が遅い可能性があるなら付ける(迷ったら付けてOK)🐢
- readinessProbe:/readyz を見る(トラフィック制御)🚦
- livenessProbe:/livez を見る(再起動制御)🔁
## Deployment の containers 配下に追加するイメージ(必要に応じて merge)
containers:
- name: api
ports:
- containerPort: 3000
startupProbe:
httpGet:
path: /startupz
port: 3000
# 起動猶予 = failureThreshold * periodSeconds
# 例: 30 * 2 = 最大60秒待つ
periodSeconds: 2
failureThreshold: 30
timeoutSeconds: 2
readinessProbe:
httpGet:
path: /readyz
port: 3000
periodSeconds: 5
failureThreshold: 3
timeoutSeconds: 2
livenessProbe:
httpGet:
path: /livez
port: 3000
periodSeconds: 10
failureThreshold: 3
timeoutSeconds: 2
3-2) “数値の意味”をざっくり理解 🧠🔢
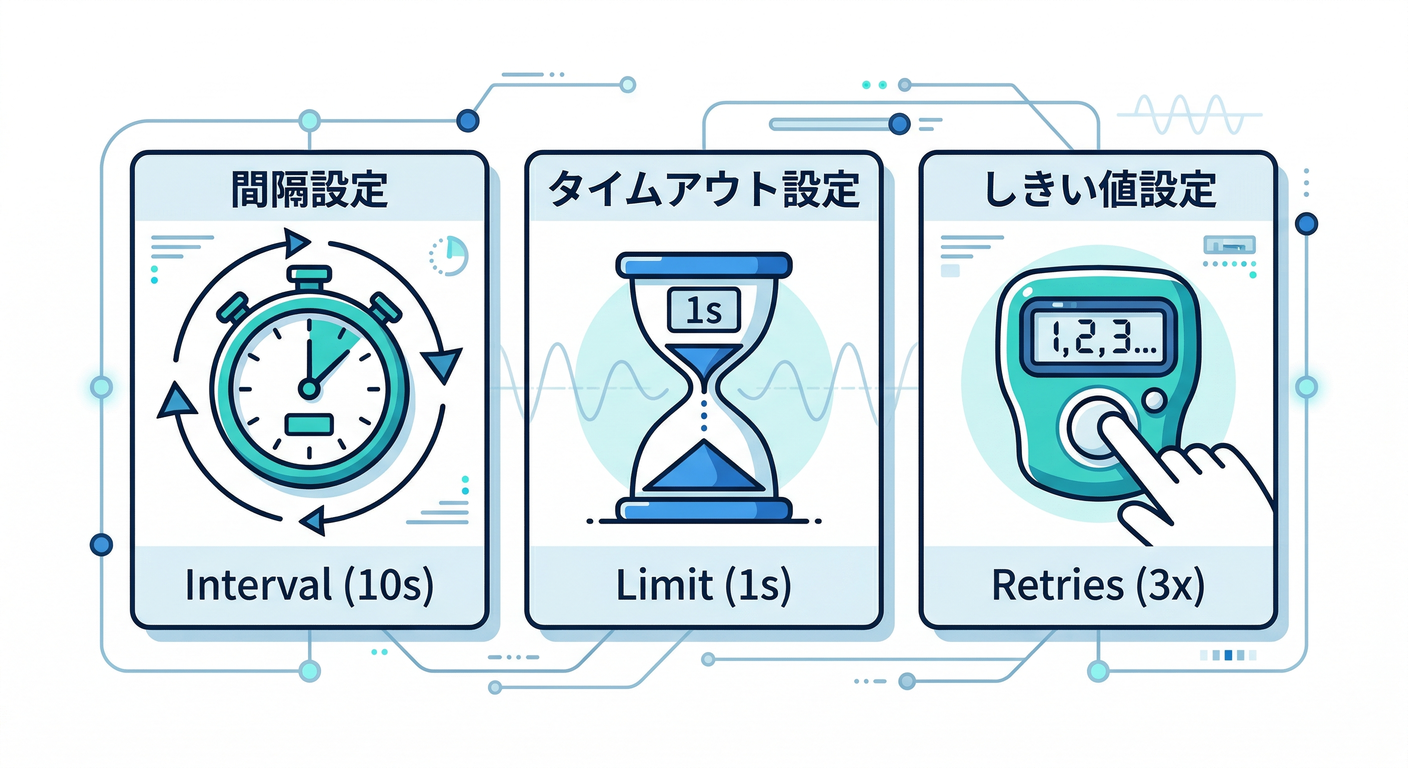
periodSeconds:何秒ごとに測る?⏱️(デフォルト10秒)(Kubernetes)timeoutSeconds:何秒でタイムアウト?⌛(デフォルト1秒)(Kubernetes)failureThreshold:何回連続で失敗したらアウト?💥(デフォルト3回)(Kubernetes)- startupProbe は
failureThreshold * periodSecondsで“起動猶予”を作るのが定番です🐢🛡️ (Kubernetes)
4) 動いてるか確認するコマンド(超よく使う)👀⌨️
kubectl get pods
kubectl describe pod <pod-name>
kubectl get events --sort-by=.lastTimestamp
kubectl get endpoints <service-name>
見るポイント👇
describeの Events に probe の失敗理由が出ることが多いです🧾✨endpointsが空なら readiness で全員落ちてる可能性大😵💫📮
5) 実験①:readiness で「起動直後の事故」を防ぐ 🚦🛡️
やること 😈➡️😇
READY_DELAY_MS=30000(30秒)で起動を遅くする- readiness を入れておく
- 起動直後は Service から外れて、準備できたら 合流するのを見る👀✨ (Kubernetes)
READY_DELAY_MS を Deployment の env に足す例👇
env:
- name: READY_DELAY_MS
value: "30000"
期待する挙動 🎉
- Podは動いてるけど、ready になるまで トラフィックが行かない🚫
- ready になった瞬間に Service の宛先に入る📮✅ (Kubernetes)
6) 実験②:liveness で「固まった/死んだ」を再起動させる 🔁🧯
やること 😈
POST /__kill_livezを叩いて/livezを 500 にする- しばらくすると コンテナが再起動するのを見る👀🔥 (Kubernetes)
(Service にアクセスできる前提で)例👇
curl.exe -X POST http://localhost:<forwarded-port>/__kill_livez
観察ポイント 👀
kubectl get podsのRESTARTSが増える🔁describe podの Events に「liveness probe failed」系が出る🧾
7) 実験③:startupProbe で「起動が遅いせいで殺される」を防ぐ 🐢🛡️
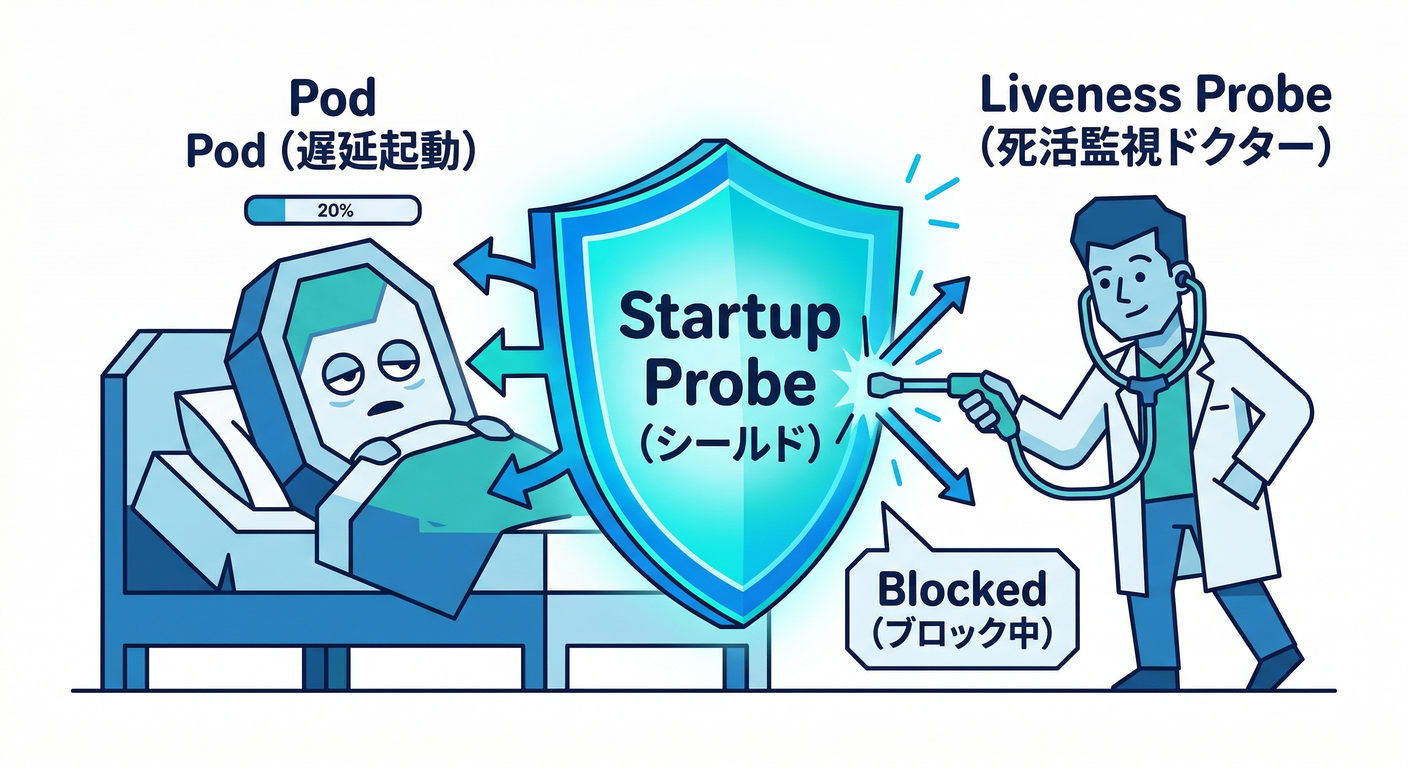
これ、地味に一番ありがち事故です😇💦
- 起動に時間がかかる(DBマイグレーション、キャッシュ温め、初回コンパイル…)
- なのに liveness が先に走って「死んでる!」扱い
- CrashLoopBackOff 地獄へ…😱
startupProbe を入れると、成功するまで liveness/readiness を無効化してくれます🛡️✨ (Kubernetes)
8) ⚠️ 2026の注意点:exec probe と timeoutSeconds(特にGKE 1.35+)⌛💥
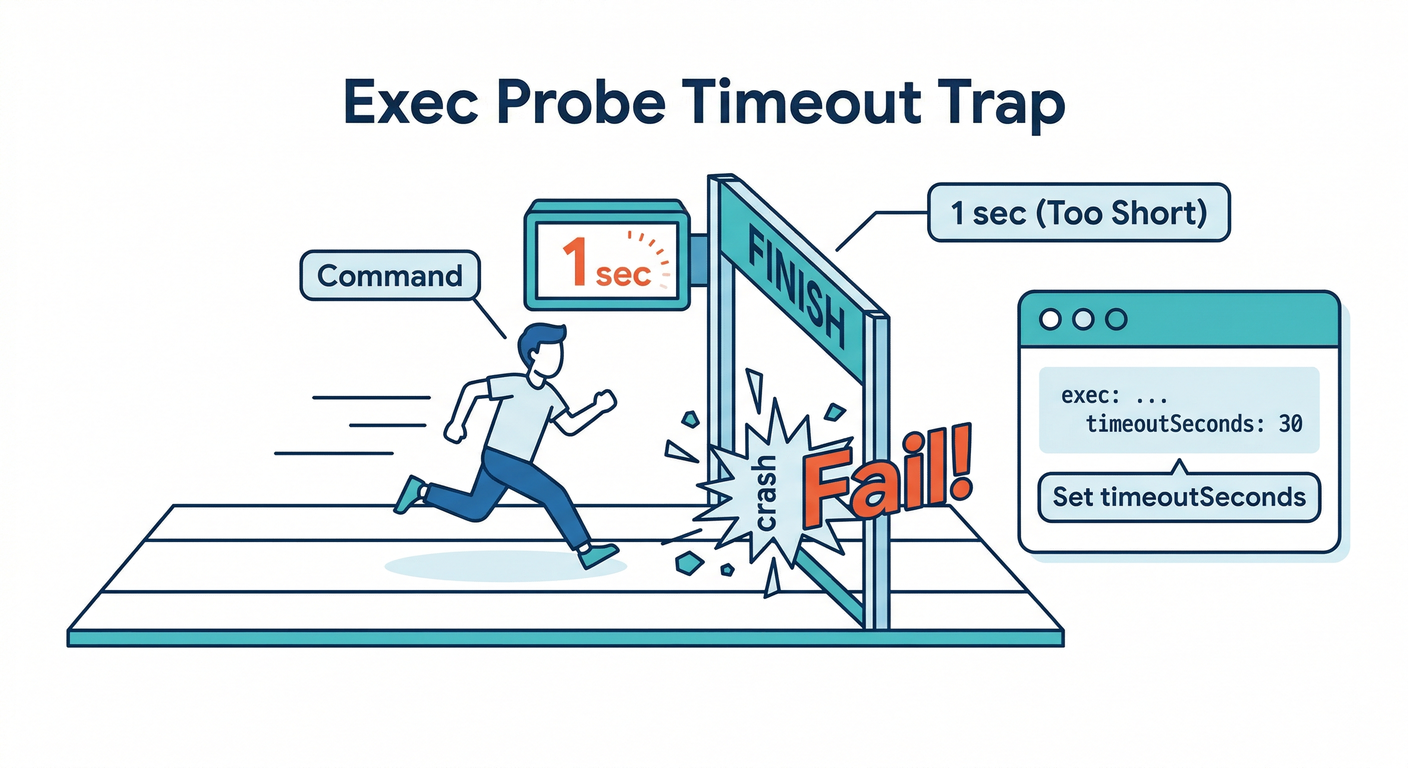
Probe には httpGet / tcpSocket / exec があるんですが、初心者には基本こうおすすめします👇
- まずは httpGet を第一候補にする🌐✅
execを使うなら timeoutSeconds を明示しよう⌛✍️
理由:GKE 1.35 以降は exec probe のコマンド timeout を“正しく”失敗扱いにするようになり、今まで動いてたものが突然コケる可能性があります⚠️
しかも timeoutSeconds を省略すると デフォルト1秒でシビアです😵💫 (Google Cloud Documentation)
なので、exec を使うときは最低でも👇
timeoutSecondsを書く(コマンドが普通に終わる秒数に)⌛- コマンドを重くしない(
curlで外部確認とかは事故りやすい)💣
9) ありがち設計ミス集(先に潰す)🧯✨
❌ liveness に「DB疎通」とか重い確認を入れる
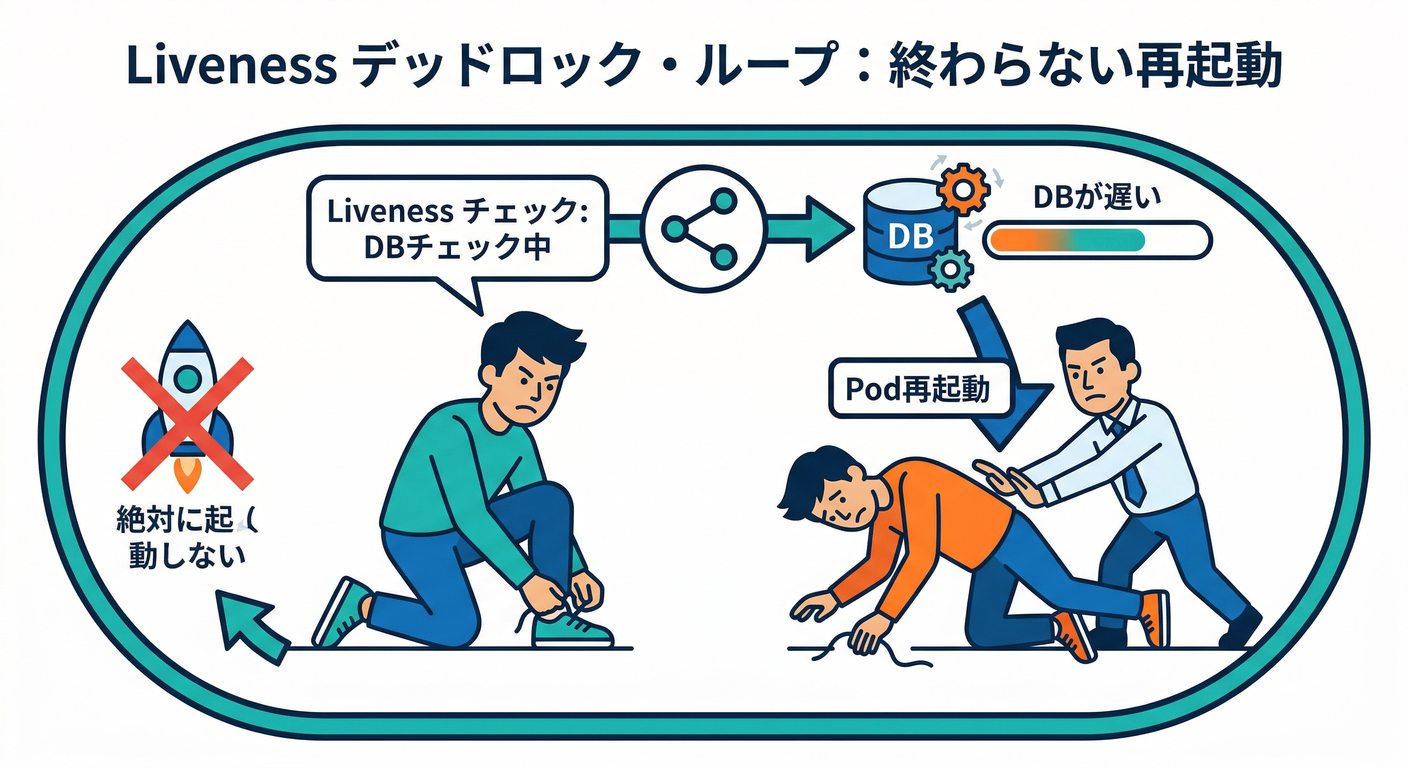
→ DB一瞬遅いだけで 再起動ループになりがち😱 ✅ DB等は readiness に寄せるのが無難🚦
❌ readiness が落ちても「原因がログに出ない」
✅ /readyz の失敗理由をログに出す(ただし秘密情報は出さない)📝🔐
✅ 同じHTTPエンドポイントを使う作戦もある
公式にも「readiness と同じ低コストHTTPを使い、liveness は failureThreshold を高める」パターンが紹介されています(“即死”を避けたいとき)🧠✨ (Kubernetes)
10) まとめ:Probe チェックリスト ✅🧾
/livezは 軽い(基本200返す、重い依存チェックはしない)🏃♂️/readyzは 依存が揃ったらOK(揃わないなら503)🔌- 起動が遅いかも?→ startupProbe を付けて守る🐢🛡️ (Kubernetes)
timeoutSecondsのデフォルトは 1秒(短い!)⌛ (Kubernetes)- exec probe を使うなら timeoutSeconds を必ず明示(GKE 1.35+ で事故りやすい)⚠️ (Google Cloud Documentation)
おまけ:最新メモ(本日時点)🗓️✨
- Kubernetes v1.35.1(2026-02-10) が最新パッチです📌 (Kubernetes)
- ローカル学習は kind v0.31.0(デフォルトKubernetes 1.35.0) / minikube v1.38.0(2026-01-28) あたりが新しめです🧰 (GitHub)
次の章(14章)が「Rolling Update / Rollback」なら、Probeが効いてるとローリング更新がめちゃくちゃ安全になるので、ここは超重要パーツです😊🔄 続けて第14章も同じ温度感で作ります?😆