第14章:バックアップの2系統:ダンプ型 vs ファイル丸ごと型🧠
この章はひとことで言うと、「うちのPJは、どっちでバックアップ取るのが正解?」を自力で決められるようになる回です😎✨ (そして、間違えると地獄を見るポイントも先に潰します🧯💥)
この章のゴール🎯
- **ダンプ型(論理バックアップ)とファイル丸ごと型(物理バックアップ)**の違いを、ふんわりじゃなく判断できる🙆♂️
- 自分のPJで **「採用する方式」**を決めて、短いメモに残す📝✨
- 「復元するとき何が起きるか」までイメージできる👀🔁
まず結論:どっちが“上”じゃなく、用途が違う🥊🤝
✅ ダンプ型(論理バックアップ)=「DBの中身を“データとして”取り出す」📤🧾
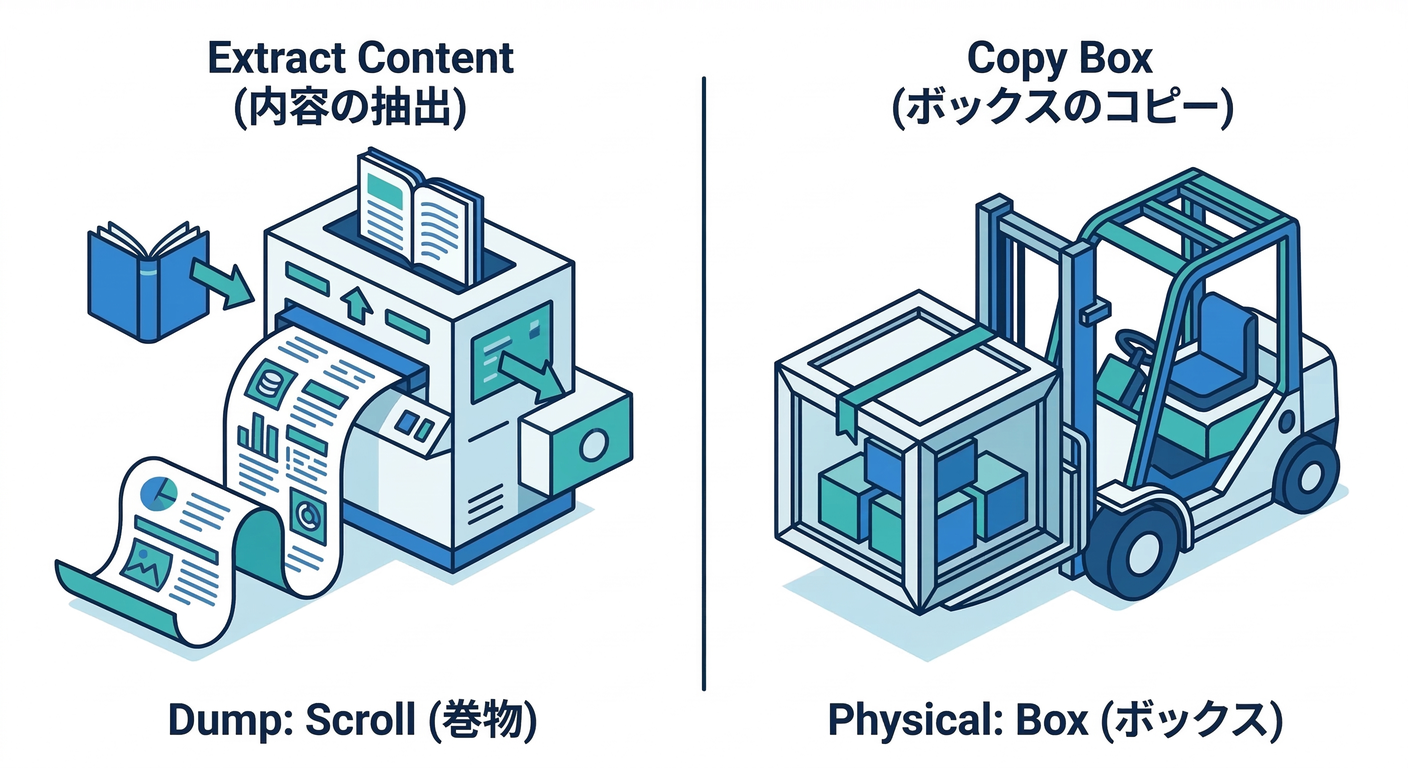
代表例:PostgreSQLなら pg_dump 🐘
pg_dump は、DB全体を吐き出して、あとで pg_restore 等で戻せるやつです。しかも custom形式(-Fc)や directory形式(-Fd)が柔軟で強いです。(PostgreSQL)
- 強み💪
-
別環境への引っ越しに強い(“DB製品として”移動できる)🚚
-
“必要なテーブルだけ戻す”みたいな選択復元がしやすい(形式による)🧩
-
pg_restore -jで並列復元できて速いこともある⚡(PostgreSQL) -
弱み🧊
- 大規模になると、ダンプ/復元に時間がかかる⌛
- DB以外(アップロードファイル等)は別で考える必要あり📁
✅ ファイル丸ごと型(物理バックアップ)=「volume(中身)を“箱ごと”固める」📦🗜️

Dockerで言うと、volumeをバックアップ/リストアする手順が公式にもあるタイプです。(Docker Documentation) イメージとしては「フォルダごとコピー」「tarで固める」みたいな世界🌍
-
強み💪
- DB以外もまとめて扱いやすい(画像/添付/ストレージ全部)📦📦
- “環境を丸ごと戻す”用途に向く(復旧スピード重視)🚑
-
弱み🧊
-
DBを動かしたまま雑にコピーすると壊れることがある😇
- Postgresでも、ファイルシステムレベルのバックアップは「整合性のあるスナップショット」等の手順が前提になってます。(PostgreSQL)
-
DBのメジャーバージョン違い・環境差で詰みやすい(“箱ごと”ゆえの罠)🕳️
-
すぐ使える判断ルール(迷ったらこれ)🧭✨
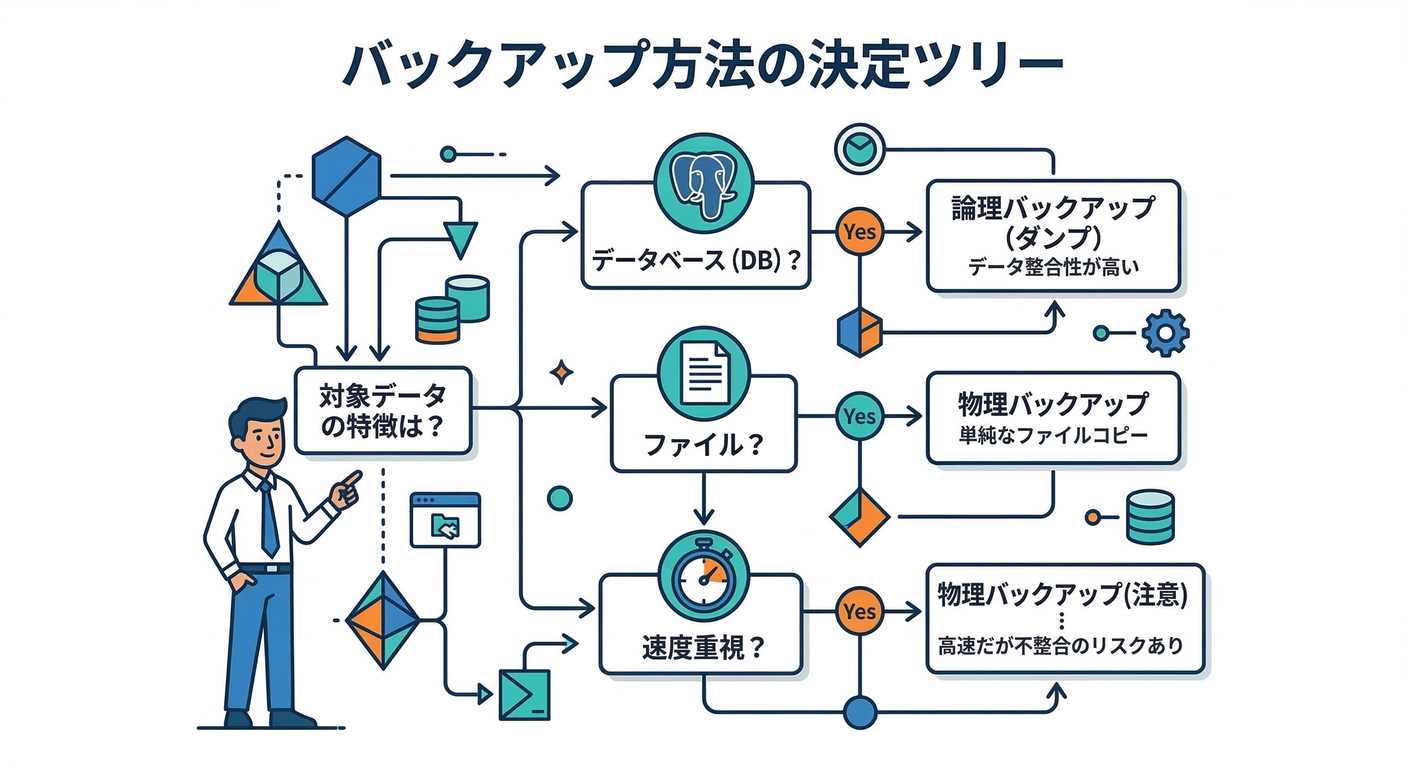
1) バックアップ対象がDB中心なら:まずダンプ型が基本🧠🐘
- 例:Postgres/MySQL など
- 理由:DBは「中身(論理)」として取り出す方が安全に運べることが多い🚚
2) DB以外(アップロード/添付/ユーザー生成ファイル)が主役なら:ファイル丸ごと型が強い📁📦
- 例:ユーザーの画像、PDF、動画、S3代わりにvolumeに入れてる、など
3) “すぐ復旧”が最優先なら:ファイル丸ごと型寄り🚑
- ただしDBは注意!(停止して取る/スナップショット等)⚠️
4) “別PCに引っ越し”もしたいなら:ダンプ型が無難🧳
- “箱ごと移動”は、環境差で事故りやすい💥
超重要:DBの「物理バックアップ」が難しい理由(初心者が落ちる穴)🪤😱
🧨 なぜ壊れる?

DBは、ディスクに書き込み中の瞬間があります。 そのタイミングでファイルを丸ごとコピーすると「途中の状態」が混ざって復元不能になることがあるんです💣
Postgresのファイルシステムレベルバックアップでも、整合性のあるスナップショットなどの前提が明示されています。(PostgreSQL)
✅ じゃあ、DBの物理系はどうする?
Postgresだと、稼働中でも取れる“ベースバックアップ”用の仕組み(pg_basebackup)があります。(PostgreSQL)
ただしここは設計・運用が一段上がるので、最初は「ダンプ型+(必要なら)volumeバックアップ」の2段構えが安心です🙂🛡️
ミニ演習:あなたのPJを“3分で仕分け”しよう⏱️📝
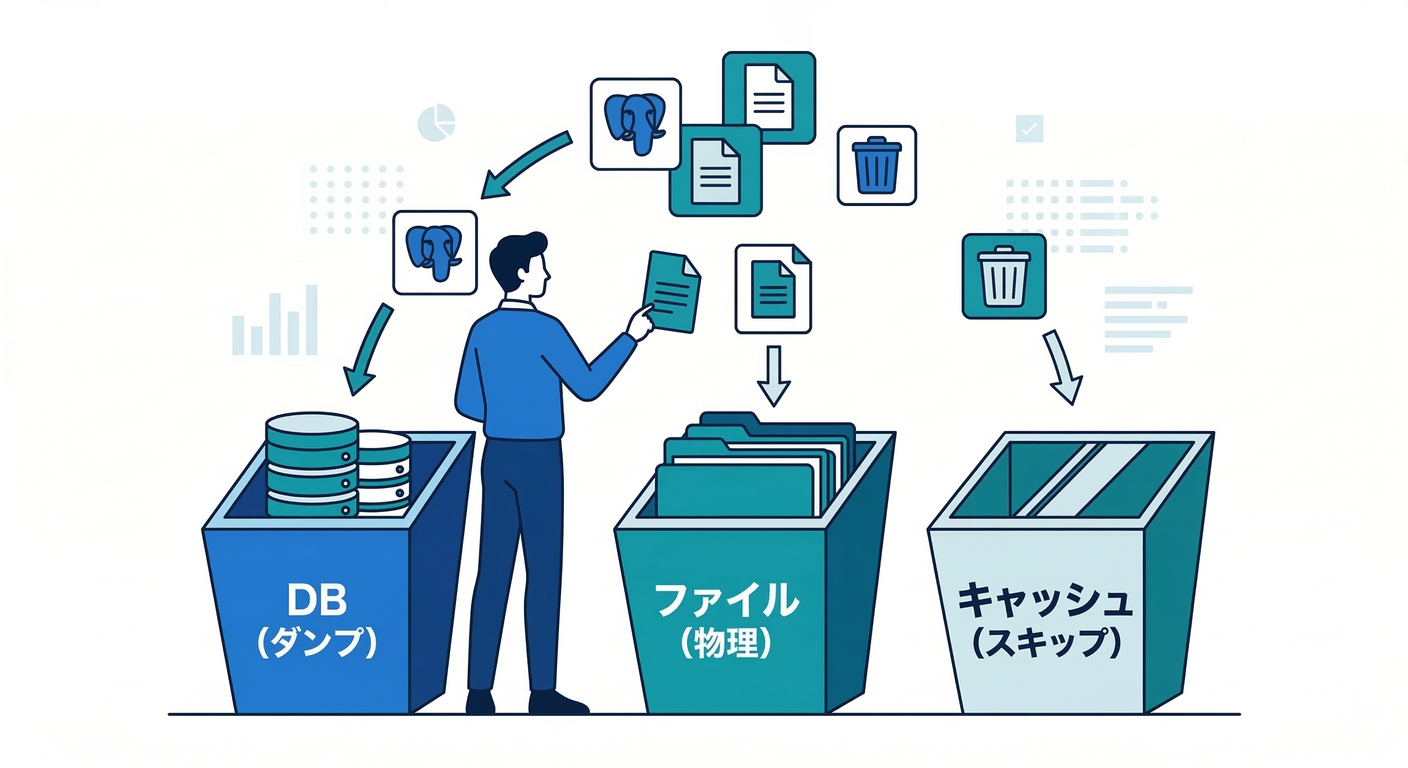
次の3つに分けて考えます👇
A. DB(例:Postgres)🐘
- 第一候補:ダンプ型(
pg_dump)(PostgreSQL) - 理由:復元・移行が素直になりやすい
B. ユーザー生成ファイル(アップロード等)📁
- 第一候補:ファイル丸ごと型(volumeを固める)(Docker Documentation)
- 理由:ファイルは“そのまま”が一番速いことが多い
C. 捨ててもいい(キャッシュ/一時)🧹
- バックアップ不要にする方が、運用がラク🙆♂️
(例)Node + TypeScript + Postgres の“ありがち構成”で決めてみる🧩✨
- DB(Postgres):ダンプ型(
pg_dump)🐘 - アップロード(/uploads をvolume):ファイル丸ごと型📦
- Redisキャッシュ:基本バックアップ不要🧹
- .env や secrets:バックアップに混ぜない(後の章で徹底🔒)
ここで作る成果物(コピペOK)📝✅
あなたのPJ用に、これだけ書けば勝ちです🎉
-
採用方式:
- DB:ダンプ型(例:pg_dump)
- ファイル:volume丸ごと型(tar等)
-
復元の最小単位:
- DBはダンプから復元
- ファイルはvolumeを戻す
-
優先順位:
- まず復元できること
- その次に自動化
ちょい注意:Docker Desktop “環境まるごと”系の話🧰🖥️
WindowsでDocker Desktopを使ってると、「環境全部をバックアップ/リストア」みたいな発想も出ます。Docker Desktop公式にも手順があります。(Docker Documentation) ただしこれは プロジェクト単位のバックアップ設計とは別枠になりがちなので、
- 普段の運用:プロジェクト単位(この章の2系統)
- 緊急時:Docker Desktop丸ごと
みたいに“役割分担”するとスッキリします🙂✨
AI活用(安全運転版)🤖🛡️✨
“秘密を貼らない”は大前提として、こう聞くと強いです👇
- 「このPJのデータを A:DB / B:ユーザーファイル / C:捨てていい に分類して、理由もつけて」📦🗂️
- 「ダンプ型とvolume丸ごと型、この構成ならどっちが事故りにくい?復元手順の観点で」🧯
- 「“復元テスト”を最短で回すチェックリストを10個にして」✅⏱️
まとめ:第14章のいちばん大事な一言🧠✨
- DBはまずダンプ型が安全に始めやすい(
pg_dumpは形式も柔軟)(PostgreSQL) - volume丸ごと型は便利だけど、DBは整合性に注意(スナップショット等の前提あり)(PostgreSQL)
- そして最終的には **「復元できることが正義」**🏆🔁
次の第15章では、いよいよ **volumeをtarでバックアップする“公式ど真ん中のやり方”**を、Windowsで事故らない形で手順化していきます🧳🗜️✨