第11章:“seed”設計:開発用ダミーデータはどこまで作る?🎲
開発で詰まりやすいのって、実は 「データが無い/毎回手で作ってる」 ところなんですよね😇 この章は「seed(シード)」=開発用のダミーデータを、やりすぎず・足りなさすぎずに設計する回です💪✨
1) seedって結局なに?何のため?🤔🧩
seedの目的はだいたいこの3つです👇
- 画面が動く(一覧・詳細・検索・ページングが試せる)📺
- バグ再現が速い(「このデータだと壊れる」が共有できる)🐛⚡
- レビューが進む(UI/仕様の確認が一気に進む)👀✅
逆に「seedを作って満足」になりがちなので、まずは**“seedの責任範囲”**を決めます✍️
2) seedは「3段階」に分けるのが超ラク😌📌
おすすめは、最初から 小・中・大 を決めちゃうことです🎮
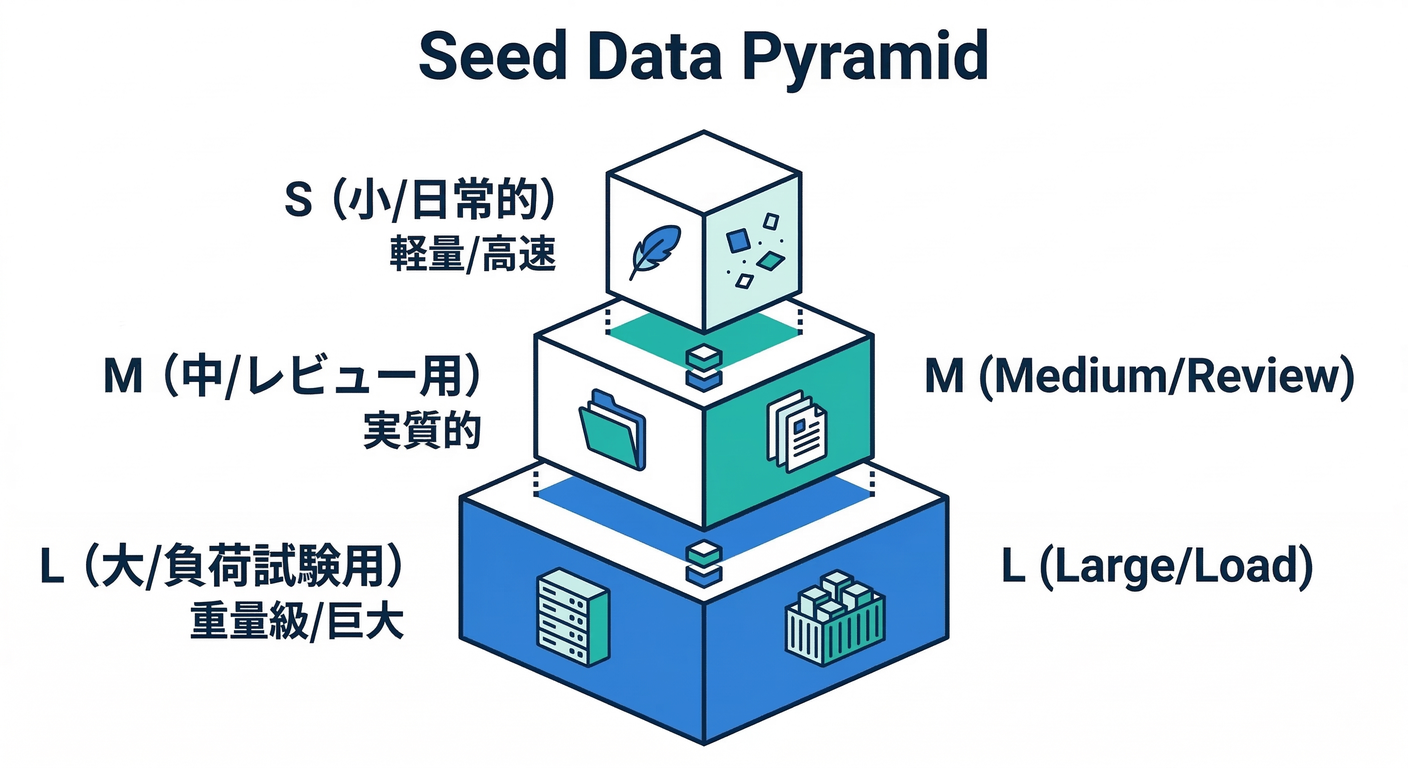
| レベル | 目的 | データ量の目安 | 守るべきルール |
|---|---|---|---|
| S(Small) | ふだんの開発 | 数十〜数百行 | 必須。毎日使う。秒で入る🚀 |
| M(Medium) | デモ/レビュー/結合確認 | 数千〜数万行 | 週に数回。やや重くてもOK🙂 |
| L(Large) | 性能/負荷/運用テスト | 数十万〜数百万行 | たまに。Gitに入れないこと多い🧱 |
S(Small)は「UIが一通り触れる最小セット」だけでOK🙆♂️
例:ECなら「ユーザー3人+商品20件+注文5件」みたいな感じ🛒
M(Medium)は「“それっぽい偏り”」を入れると強い💡
例:商品カテゴリの偏り、在庫0、注文集中、長い検索語、絵文字入り名前…など😈
L(Large)は「別物」だと思うと楽🧠
Lは生成にも時間がかかるので、生成スクリプトだけGit、実データはバックアップ/ダンプ運用に寄せがちです📦(この後の章でやります)
3) seedの置き場所:この2択で迷わない👍📁
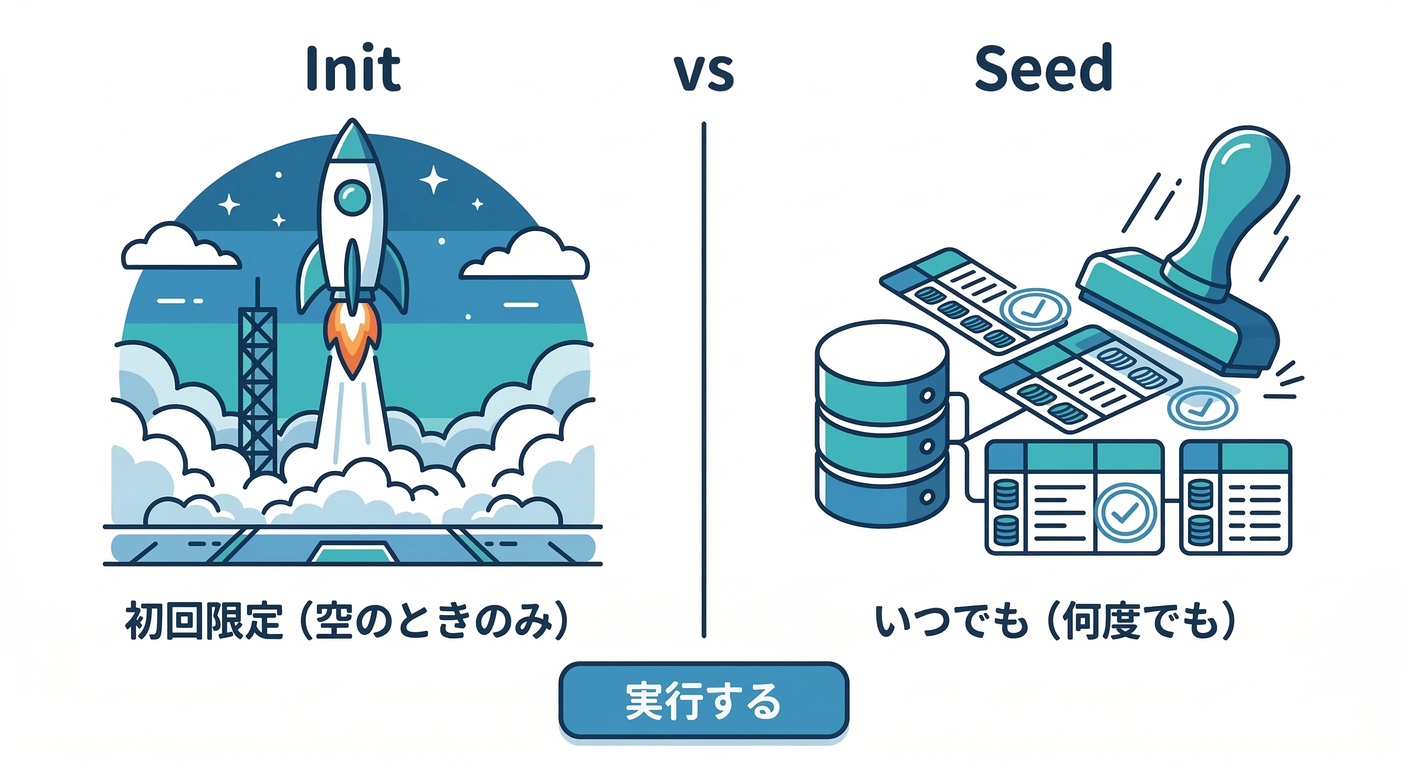
seedって「どこで動かすか?」で事故りやすいです🫠 代表的なのはこの2パターン👇
A) “初回だけ”方式(DBイメージの初期化に混ぜる)🎬
たとえば Docker の公式イメージ(例:Postgres)には、/docker-entrypoint-initdb.d があって、初回起動時にSQLを流せます🌱
でも注意点が超重要で……
- データディレクトリが空の時だけ動く(=volumeが残ってると基本もう動かない)⚠️ (Docker Hub)
👉 なので “S(Small)の最低限” を入れるならアリ。 でも 何度も入れ直すseed には向きません😇
B) “何度でも”方式(seed専用の一回きりコンテナ)🔁
これがいちばん扱いやすいです🎉 Composeの profiles を使うと「seed用サービスは普段は起動しない」が簡単に作れます✅
profilesは、サービスに profiles: を付けると そのプロファイルを有効化した時だけ 起動されます。 (Docker Documentation)
4) ハンズオン:profilesで “seedコンテナ” を作る📦✨
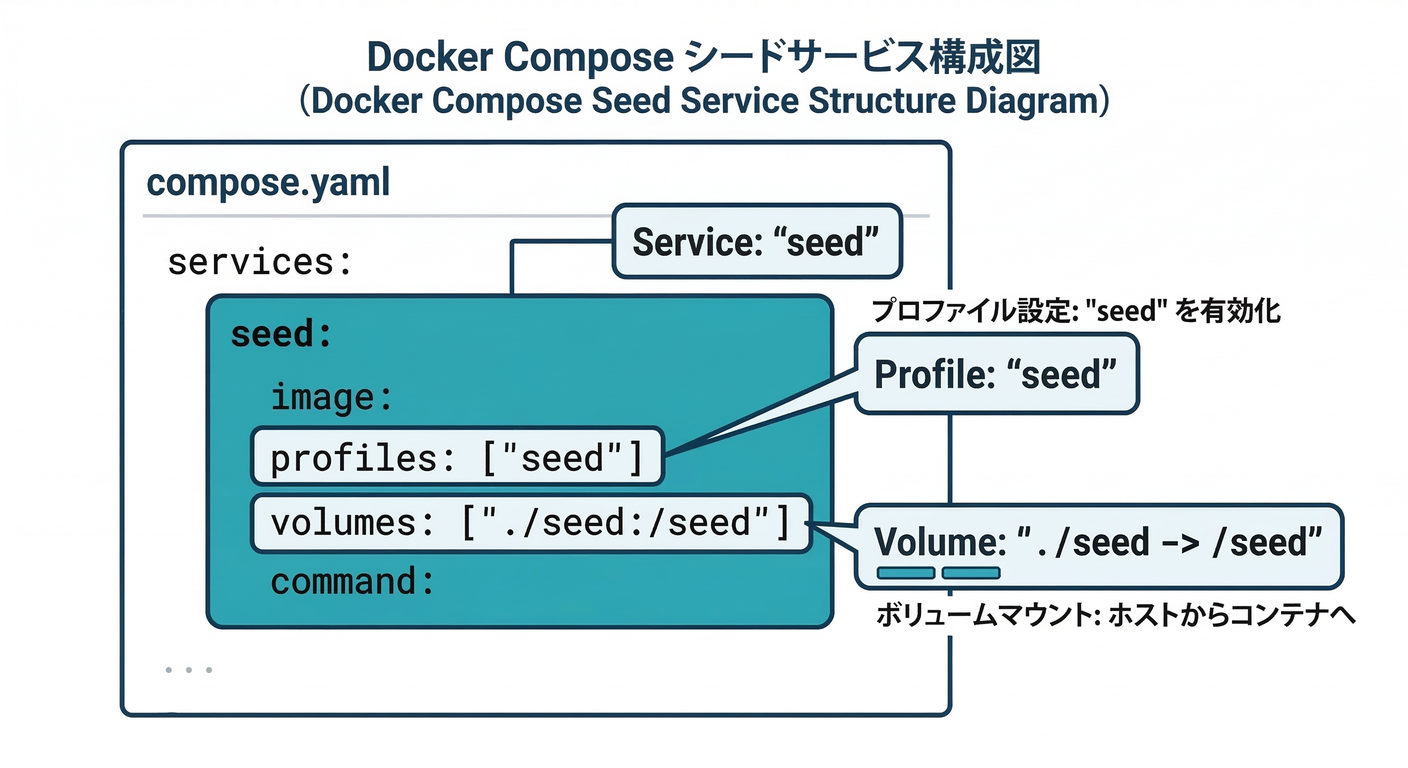
ここでは「DBにseedを流す専用サービス」を作ります😊 (まずは SQL seed が一番簡単で壊れにくいです👍)
フォルダ構成(例)🗂️
compose.yamlseed/seed_small.sqlseed/seed_medium.sql(任意)seed/README.md(seedの使い方メモ)
compose.yaml(例)🧩
services:
db:
image: postgres:16
environment:
POSTGRES_USER: app
POSTGRES_PASSWORD: apppass
POSTGRES_DB: appdb
volumes:
- db-data:/var/lib/postgresql/data
seed:
image: postgres:16
profiles: ["seed"] # ← これがポイント!
depends_on:
- db
environment:
PGPASSWORD: apppass
volumes:
- ./seed:/seed:ro
command: >
bash -lc "
psql -h db -U app -d appdb -f /seed/seed_small.sql
"
restart: "no"
volumes:
db-data:
profiles: ["seed"]のサービスは、普段docker compose upしても起動しません🙌 (Docker Documentation)- named volume(ここでは
db-data)は、Composeで使い回せる永続ストアです📦 (Docker Documentation)
seed/seed_small.sql(例)🌱
「二回流しても壊れない(=設計がラク)」方向に寄せるのがコツです🙂 まずは雑に “全部消して入れ直す” でOK(開発用だけ!)💣➡️✅
BEGIN;
CREATE TABLE IF NOT EXISTS users (
id SERIAL PRIMARY KEY,
name TEXT NOT NULL,
email TEXT NOT NULL UNIQUE
);
TRUNCATE TABLE users RESTART IDENTITY;
INSERT INTO users (name, email) VALUES
('Alice', 'alice@example.com'),
('Bob', 'bob@example.com'),
('Carol', 'carol@example.com');
COMMIT;
本番に近い運用だと「TRUNCATEしない」「UPSERTで差分だけ」などに進化させますが、最初はこれでOKです😄
実行コマンド(PowerShellでもOK)▶️
- DB起動
docker compose up -d db
- seed実行(profilesを有効化して run)
docker compose --profile seed run --rm seed
profilesは --profile か COMPOSE_PROFILES 環境変数で有効化できます✅ (Docker Documentation)
5) seed設計の“ちょうどいい線”の決め方🎯🧠
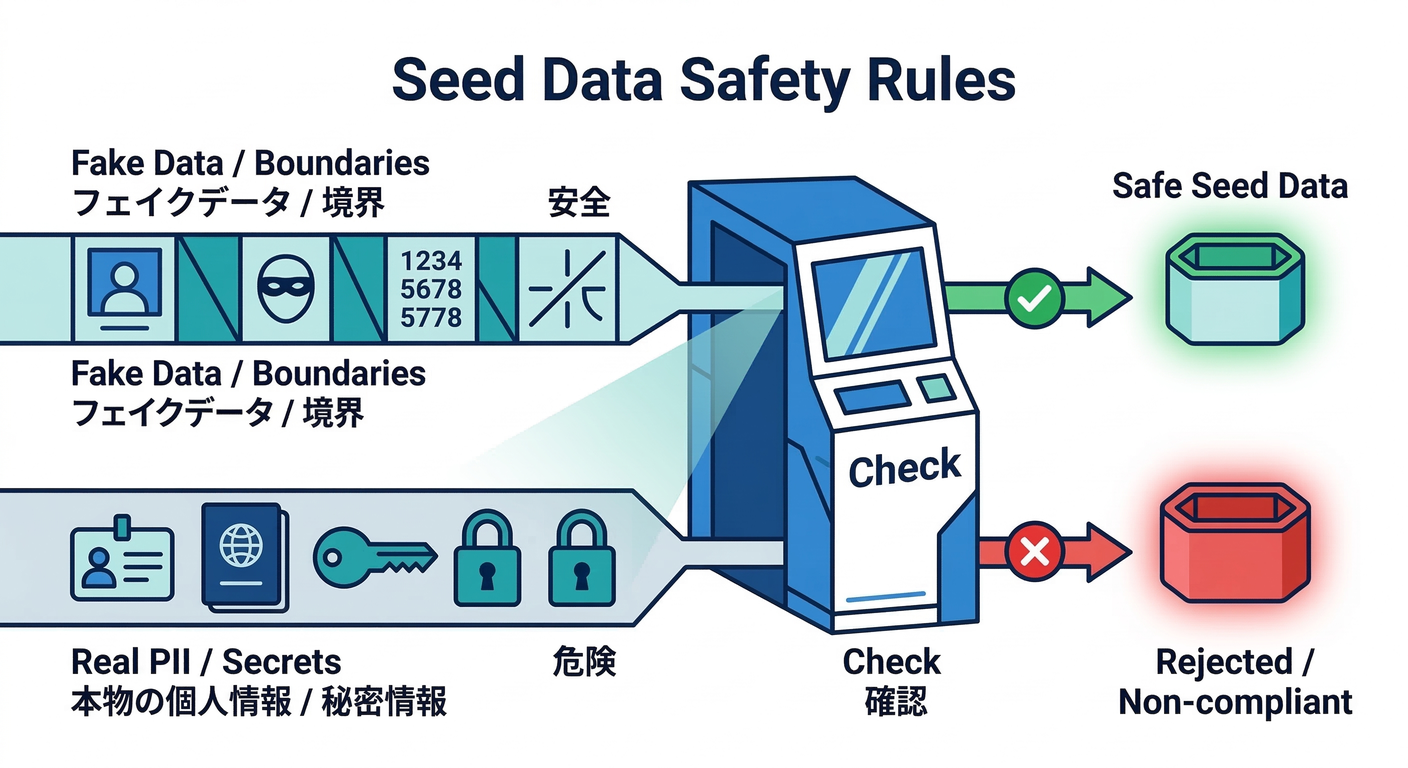
✅ seedに入れていいもの
- 画面表示に必要な最小データ(一覧/詳細が成立する)📄
- 境界値(空、0、最大長、絵文字、改行)🧨
- 状態違い(未購入/購入済み、未読/既読、公開/非公開)🔀
❌ seedに入れないほうがいいもの
- 本物の個人情報(メール、住所、電話、アクセスログの生データ)🚫
- 本番の「全パターン網羅」みたいな重すぎるセット🥵
- “秘密”が混ざるもの(APIキー、トークン、
.env丸ごと)🔒
6) 「S/M/L」方針メモ(成果物)📌📝
このテンプレを seed/README.md に貼って完成でOKです🎉
## Seed 方針
## Small(毎日)
- 目的:UIが一通り触れる
- 量:数十〜数百行
- 手段:seed_small.sql(TRUNCATEして入れ直し)
- 実行:docker compose --profile seed run --rm seed
- 目標時間:10秒以内
## Medium(レビュー/結合)
- 目的:偏り/境界値/検索/ページング確認
- 量:数千〜数万行
- 手段:seed_medium.sql or 生成スクリプト
- 実行:必要時だけ
## Large(負荷/性能)
- 目的:性能/運用の検証
- 量:数十万〜
- 手段:ダンプ/バックアップから復元(Gitに入れない)
7) AIの使いどころ🤖✨(安全運転つき)
使っていいお願い(例)✅
- 「このテーブル構造でS/M/Lのseed方針を作って」📋
- 「境界値データ案を20個出して」🧪
- 「このSQLを“二回実行しても同じ結果になる形”に直して」🔁
使わないお願い(例)❌
- 本番データを貼る(個人情報/顧客情報/ログ)🚫
.envや秘密を貼る🔒
8) よくある罠(先回り)🪤😇
-
「初期化(
docker-entrypoint-initdb.d)に入れたseedが2回目動かない!」 → volumeが残ってると初期化は動かないのが仕様です。だから“何度でも”方式(seed専用コンテナ)が便利です😌 (Docker Hub) -
「seedが重くて起動が遅い!」 → seedは profilesで“普段は起動しない” にすると気持ちよく回ります🚀 (Docker Documentation)
ここまでできたら、第12章(migration)に進むと一気に“本物の運用っぽさ”が出ます📜✨ 次は「手でSQLを書いてもいいから、変更履歴を残す」方向に育てていきましょー😄🔥