第30章:卒業制作:わざと壊して直す “観測性デバッグRPG”🎮🧨🩹
① 今日のゴール 🎯🏁
この章を終えたら、「ログ🧾・メトリクス📈・ヘルスチェック💚」だけを頼りに、原因特定→復旧確認までやり切る体験ができます💪✨ 最終的な成果物(= 卒業証書)はこちら👇
- 自分専用の障害対応テンプレ(Runbook)📝
- Grafanaダッシュボード(最小でOK)🖼️
- /health と /ready の設計メモ(HTTPコード方針)📗
- 「壊し方」と「直し方」の記録(RPGの冒険ログ)📓🗡️
② 先に“地図”を見よう 🗺️👀
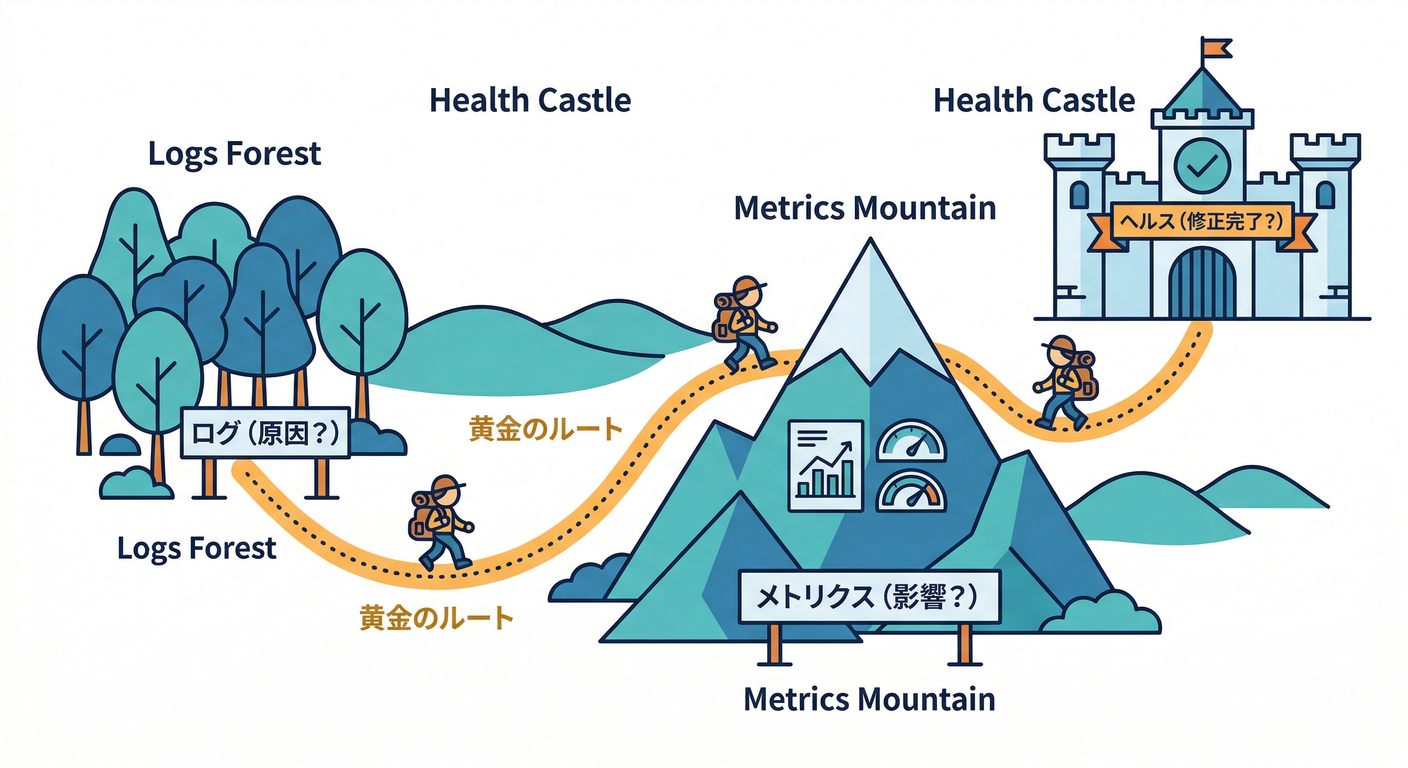
観測の流れはこの形に固定します(迷ったらここに戻る)👇
- ログ🧾:どこで何が起きた?(原因の匂い)
- メトリクス📈:どれくらい影響が出た?(被害の広さ)
- ヘルス💚:復旧したって言っていい?(復旧判断)
③ “RPGの舞台”を起動する 🛠️🚀
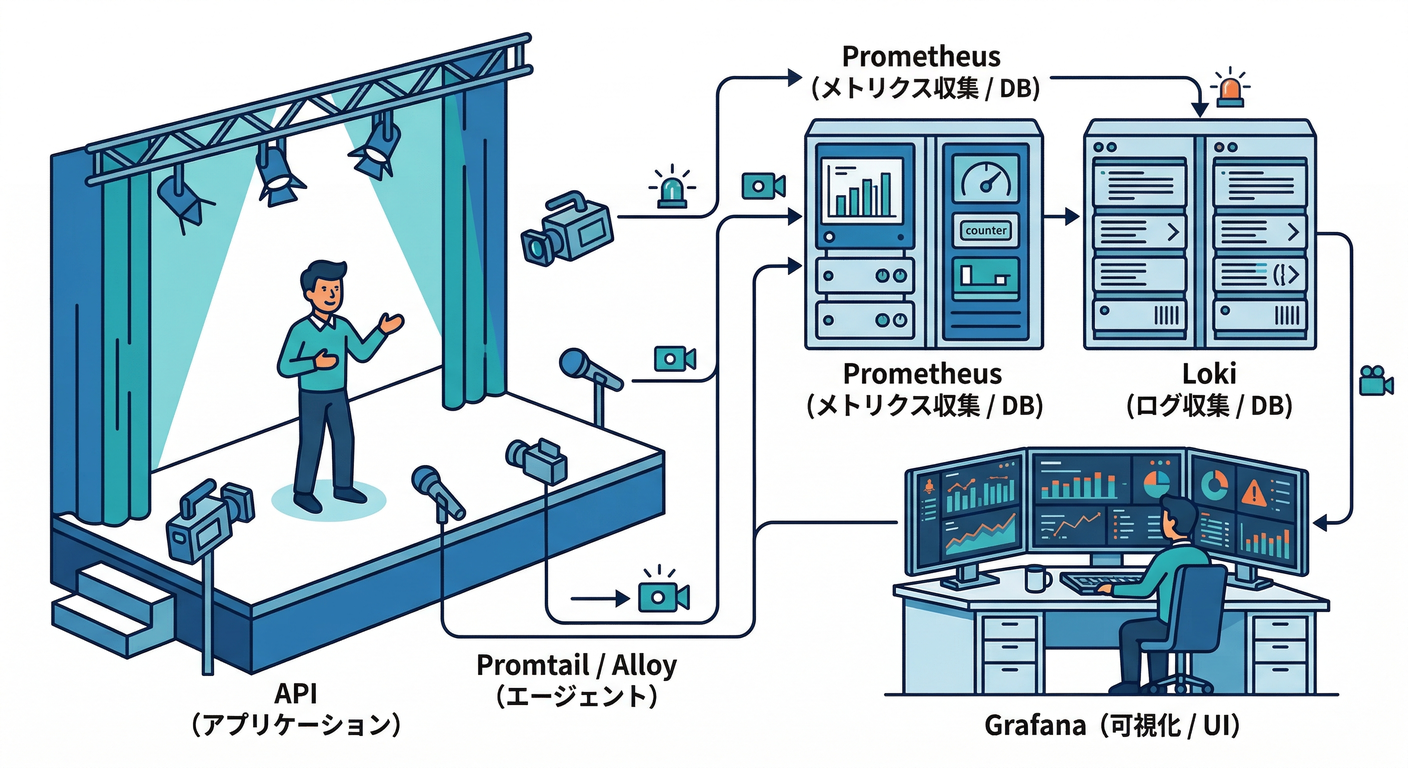
ここでは API + Prometheus + Grafana + Loki(+Promtail) が立ってる前提で進めます。 (Loki/Promtailは Docker/Compose で評価・開発用途として動かせます📦)(Grafana Labs)
起動チェック ✅
まずは「動いてる」じゃなくて「観測できる」を確認します😎
- APIが応答する
/ping→ 200/health→ 200/ready→ 200(依存が生きてる時)
- Prometheusが scrape できてる
/metricsに数字が出る(prom-client は Counter/Gauge/Histogram/Summary を扱えます📈)(NPM)- Prometheusのメトリクスタイプ自体の考え方はこの4種が基本です(prometheus.io)
- Grafanaで見える
- RPS / 5xx率 / p95 / メモリ が最低1枚でも表示されてる
- ログが探せる
- Loki(Explore)で
service="api"とかreqId="..."で絞れる
④ “敵(障害)”を仕込む:Chaosスイッチ 🧨🎚️
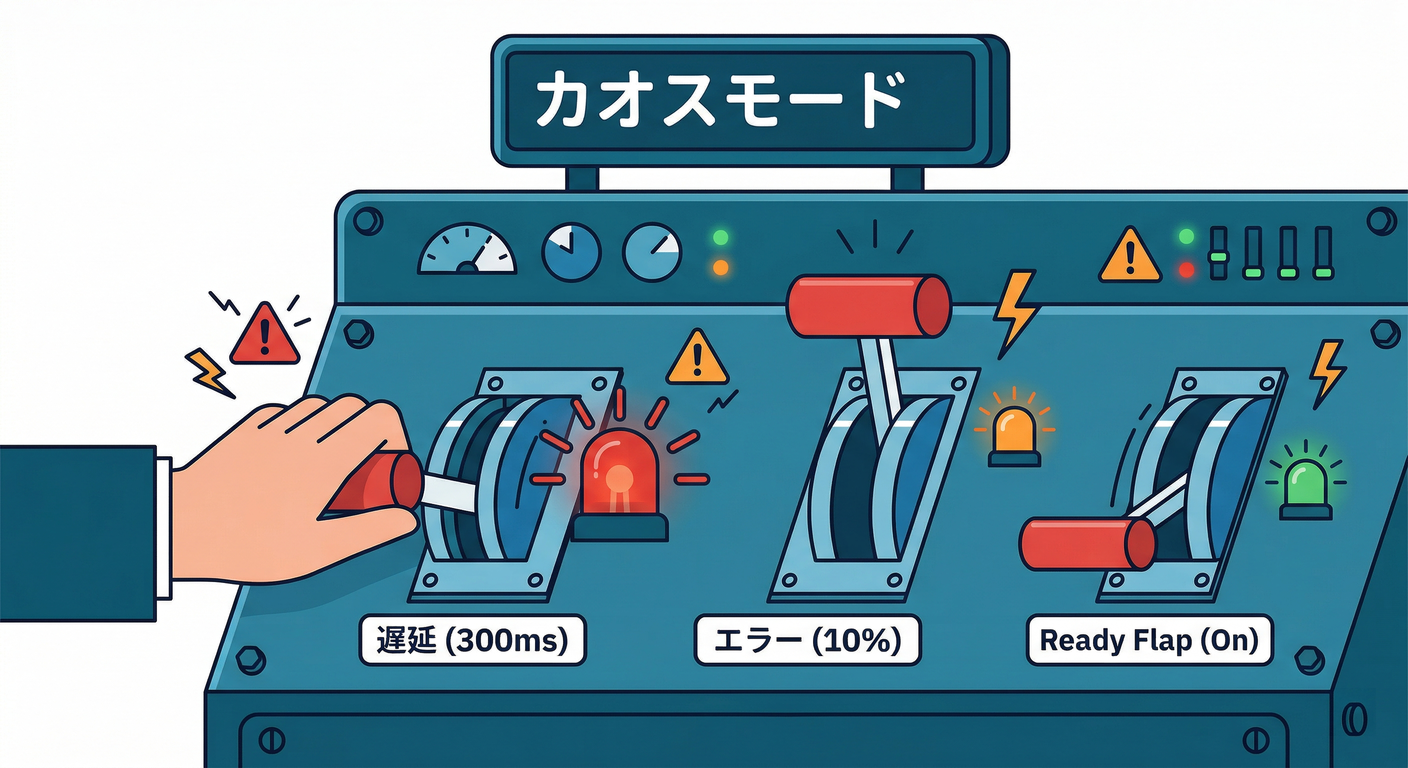
卒業制作なので、壊すためのスイッチを入れます😈 (本番に入れないでね! ローカル学習用だよ!)
仕込み方(例)🧩
環境変数で挙動を変えられるようにします👇
CHAOS_LATENCY_MS=300(遅延を足す🐢)CHAOS_ERROR_RATE=0.1(10%で500💥)CHAOS_READY_FLAP=1(/readyが時々落ちる🔌⚡)
TypeScriptの例(超ミニ)👇
// src/chaos.ts
export const chaos = {
latencyMs: Number(process.env.CHAOS_LATENCY_MS ?? 0),
errorRate: Number(process.env.CHAOS_ERROR_RATE ?? 0),
readyFlap: process.env.CHAOS_READY_FLAP === "1",
};
export async function maybeDelay() {
if (chaos.latencyMs <= 0) return;
await new Promise((r) => setTimeout(r, chaos.latencyMs));
}
export function maybeThrow() {
if (chaos.errorRate <= 0) return;
if (Math.random() < chaos.errorRate) {
const err = new Error("CHAOS: random failure");
(err as any).code = "CHAOS_FAIL";
throw err;
}
}
export function readyShouldFailSometimes() {
if (!chaos.readyFlap) return false;
// 20%くらいでready落とす(雑でOK)
return Math.random() < 0.2;
}
⑤ クエスト1:p95ドラゴン退治 🐉🐢📉

症状:突然「遅い」💦(p95が悪化) 勝ち筋:ログで場所を当てて、メトリクスで被害を測って、改善を確認する✨
手順(RPGの攻略チャート)🗡️
-
メトリクスで“被害”を見る📈
- Grafanaで p95(または latency histogram) が跳ねてるか確認
- p95/p99の考え方は PrometheusのHistogram/quantileの話が超参考になります(prometheus.io)
-
ログで“場所”を絞る🧾
- 遅いリクエストのログに
ms(処理時間)とrouteを入れておく ms > 500的な検索(JSONログならフィールド検索しやすい👍)
- 遅いリクエストのログに
-
原因を1個に仮説化🧠 例:
- 同期的に重い処理をしてる(CPU張り付き)🧱
- 依存(DB/Redis)が遅い🕳️
- そもそもCHAOS遅延を入れた😈
-
直す(最小の一手)🩹
- まずは「遅延の注入をやめる」or「重い処理を軽くする」
- 直したら p95が戻るまで確認(ここ重要!)
期待するログ例(遅いのが見える)👀
{"time":"2026-02-13T10:12:34.567Z","level":"INFO","msg":"access","reqId":"a1b2","method":"GET","path":"/slow","status":200,"ms":842}
⑥ クエスト2:5xxゴブリン討伐 👾💥🧾

症状:5xxが増える(エラー率が上がる) 勝ち筋:reqId(相関ID)で“1リクエストの物語”を追う🧵
手順 🧭
-
メトリクスで5xx率を確認📈
- 5xxカウンタが増えてる
- 2xx/4xx/5xx を分けて数えるのが王道🧮
-
ログでreqId検索🔎
reqId="..."で関連ログを全部見る- 最後に
stack(スタックトレース)が残ってるか確認
-
“500にしなくていいもの”を減らす🧹
- 入力ミス → 400
- 認証失敗 → 401/403
- 本当に落ちた → 500(ここだけ🔥)
-
未処理Promise/例外の取りこぼしを潰す🧯
- エラーハンドラで必ずログに残す
⑦ クエスト3:依存フラップ地獄 🔌⚡💚
症状:たまに /ready が落ちる、再起動後につながらない 勝ち筋:readiness と Compose の起動順(service_healthy)で“安定化”⏳✨
ここが超大事ポイント 🧠
Compose は「起動順」はやってくれるけど、“readyになるまで待つ”には healthcheck が必要です。
depends_on の condition: service_healthy を使うと、依存サービスが healthcheck で healthy になるまで待てます✅(Docker Documentation)
Compose例(依存がhealthyになるまで待つ)⏳
services:
api:
depends_on:
db:
condition: service_healthy
healthcheck の調整(start_period が効く)🧪
HEALTHCHECK は interval/timeout/start-period/retries などがあり、最初は starting → 成功で healthy、失敗が続くと unhealthy になります(Docker Documentation)
さらに --start-interval は Docker Engine 25.0+ が必要です(古いと効かない系の罠!)(Docker Documentation)
⑧ ラストボス:複合障害の城 🏰🧟♂️📈🧾💚
最後は 3つ同時に来ます😇(でも手順は同じ!)
- p95悪化🐢
- 5xx増加💥
- /readyが時々死ぬ🔌⚡
“3分・10分・30分”テンプレ(最終版)⏱️📝
以下を docs/runbook.md として保存して卒業!🏆
## 観測性Runbook(自分用)
## 3分でやる(止血)
- Grafanaで「p95 / 5xx / RPS / メモリ」を見る
- 直近で変えたもの(設定・依存・環境変数)を確認
- /health /ready を叩く(200? 失敗?)
- 重大なら一旦 CHAOS をOFF(環境変数)
## 10分でやる(原因の当たり)
- 影響のある route を特定(どのURLが遅い/落ちる?)
- reqId でログを追う(入口→途中→例外)
- 依存のhealth状態(db/redis等)を確認
## 30分でやる(再発防止)
- ログに足りないフィールド追加(route, ms, status, reqId, errorCode…)
- メトリクス追加(route別histogram、5xx率、依存失敗回数)
- readiness設計見直し(軽い疎通、タイムアウト、戻りコード統一)
- ダッシュボードに「今回の学びパネル」を追加
⑨ “成果物チェックリスト”🏆✅
提出物(自分に提出w)をこれで確認!😆
- Grafana:p95 / 5xx率 / RPS / メモリ のパネルがある
- ログ:
reqId,route,status,ms,errorCodeが最低入ってる - /health:軽くて速い(依存チェックしない)
- /ready:依存疎通が落ちたら落ちる(でも重すぎない)
- Compose:依存に
condition: service_healthyを適用できるところは適用(Docker Documentation) - HEALTHCHECK:interval/timeout/start-period/retries を意図して設定してる(Docker Documentation)
⑩ つまづきポイント(罠)🪤😵💫
- ログはあるのに追えない
→
reqIdが無い / 形式がバラバラ /msが無い(この3つが犯人率高い😇) - p95が戻らない → 「直したつもり」でも traffic が足りない or 観測窓(5mなど)が長い
- service_healthy が効かない
→ 依存側に
healthcheck:が無い、またはチェックが重すぎる - HEALTHCHECKの挙動が期待と違う → start-periodの解釈ミス、timeout短すぎ、retries少なすぎ(調整しよ🛠️)(Docker Documentation)
⑪ ミニ課題(15〜30分)⏳🎯
次の条件を満たすように改造してみてね👇
-
/slowの遅延が起きた時、ログ1行だけで「原因候補」が想像できる- 例:
latencySource="chaos"とかdep="db"とか
- 例:
-
5xxが増えた時、Grafanaの1枚で 「今は危険」 が分かる(赤くなくてOK)
- 例:5xx率パネル + 閾値線
-
/ready が落ちた時、/health は落ちない(役割分担できてる)💚
⑫ AIに投げるプロンプト例 🤖📋✨
そのままコピペOK!
あなたはSRE見習いです。
次の3症状が同時に出たときの「3分・10分・30分」切り分け手順を、
ログ/メトリクス/ヘルスの順番に固定して提案してください。
- p95悪化
- 5xx増加
- readinessが時々失敗
前提:Node.js API、Prometheus、Grafana、Loki。出力はチェックリスト形式。
Node.js(Express/TS)で、JSON構造化ログに
reqId/route/status/ms/errorCode を必ず含める logger ミドルウェアを作ってください。
「秘密情報(Authorizationなど)は絶対に出さない」も守ってください。
PrometheusのHistogramでAPIレイテンシを取りたいです。
route別に p50/p95 を見たいので、メトリクス設計(名前、labels、buckets)案をください。
🎉 卒業!次にやると強いこと(おかわり)🍚✨
- 負荷を自動でかける(k6など)→ “壊れる瞬間”が再現しやすくなる🔥 k6はDockerイメージでも扱えます📦(hub.docker.com)
- 「今回の障害」ごとにダッシュボードにパネルを1個ずつ足す(育てゲー🌱)
必要なら、**この第30章の内容を“そのまま動く”最小リポジトリ構成(compose.yml / Dockerfile / src一式)**として、コピペで完成する形に整理して出しますよ📦✨