第01章:観測性の全体像をつかむ 🗺️👀
① 今日のゴール 🎯
この章のゴールはこれ!✨
- ログ🧾/メトリクス📈/ヘルスチェック💚の役割を一言ずつ言える
- 「トラブルが起きたとき、何から見ればいいか」を迷わない
- 「原因→影響→復旧判断」の3ステップ脳内マップができる 🧠🧭
② 図(1枚)🖼️
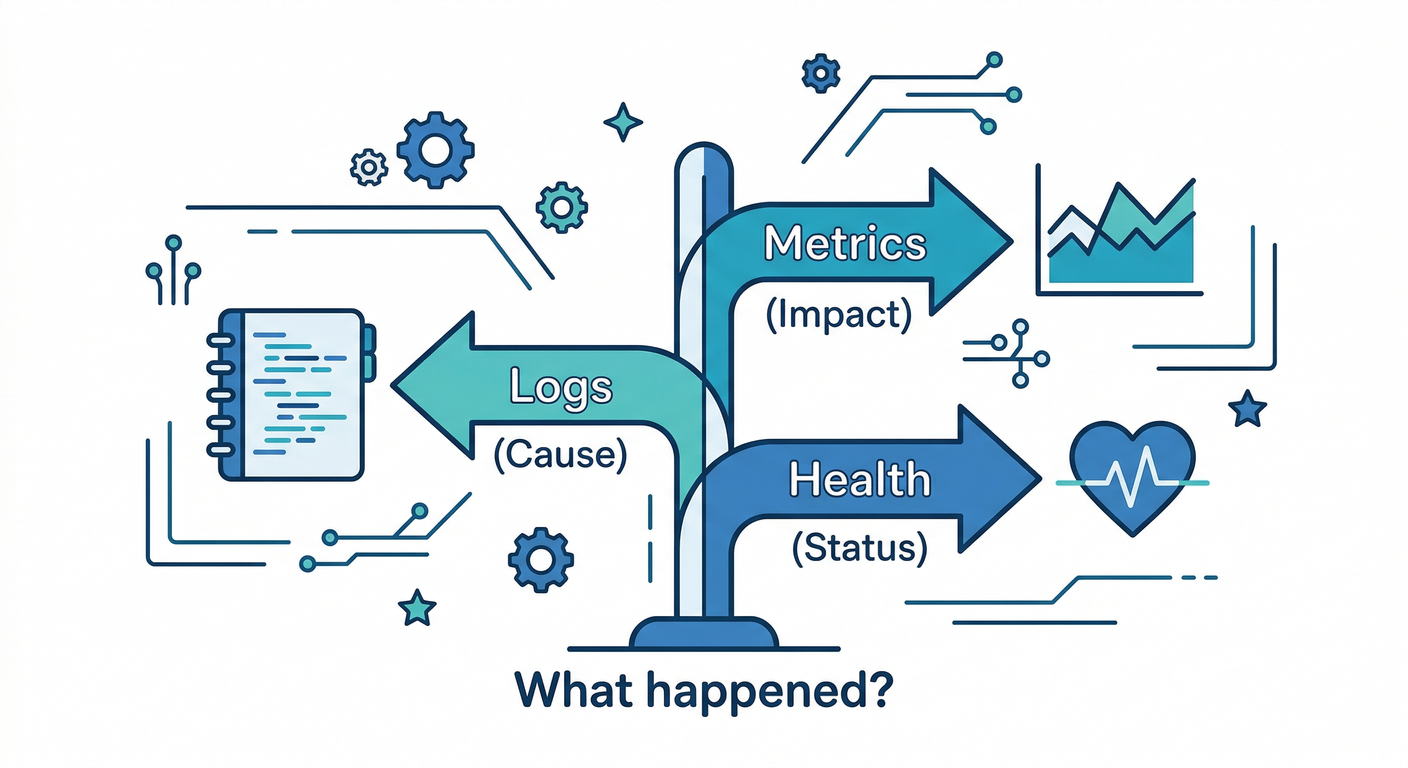
“観測性”は、ざっくりこの流れで覚えるのが最強です👇
【症状】 【観測データ】 【やること】
遅い🐢 → メトリクス📈(p95上がった?) → 影響範囲を把握→原因探し
落ちる💥 → ログ🧾(どこで例外?) → 原因を特定→修正
繋がらない🔌 → ヘルス💚(ready?live?) → 復旧判断→再起動/切り離し
キーワードはこれ👇
- ログ🧾=原因(どこで・何が起きた)
- メトリクス📈=影響(どれくらい悪い)
- ヘルス💚=復旧判断(使っていい?戻った?)
③ そもそも「観測性」って何?🤔👀
観測性(Observability)って、むずかしく言うと「外から見える情報だけで、中で何が起きてるか推理できる力」みたいなものです🕵️♂️✨
でもこの教材では、もっとシンプルにこう覚えます👇
観測性=トラブルのときに迷子にならないための“三点セット”🧾📈💚
④ ログ・メトリクス・ヘルスを一言で言う 🧾📈💚
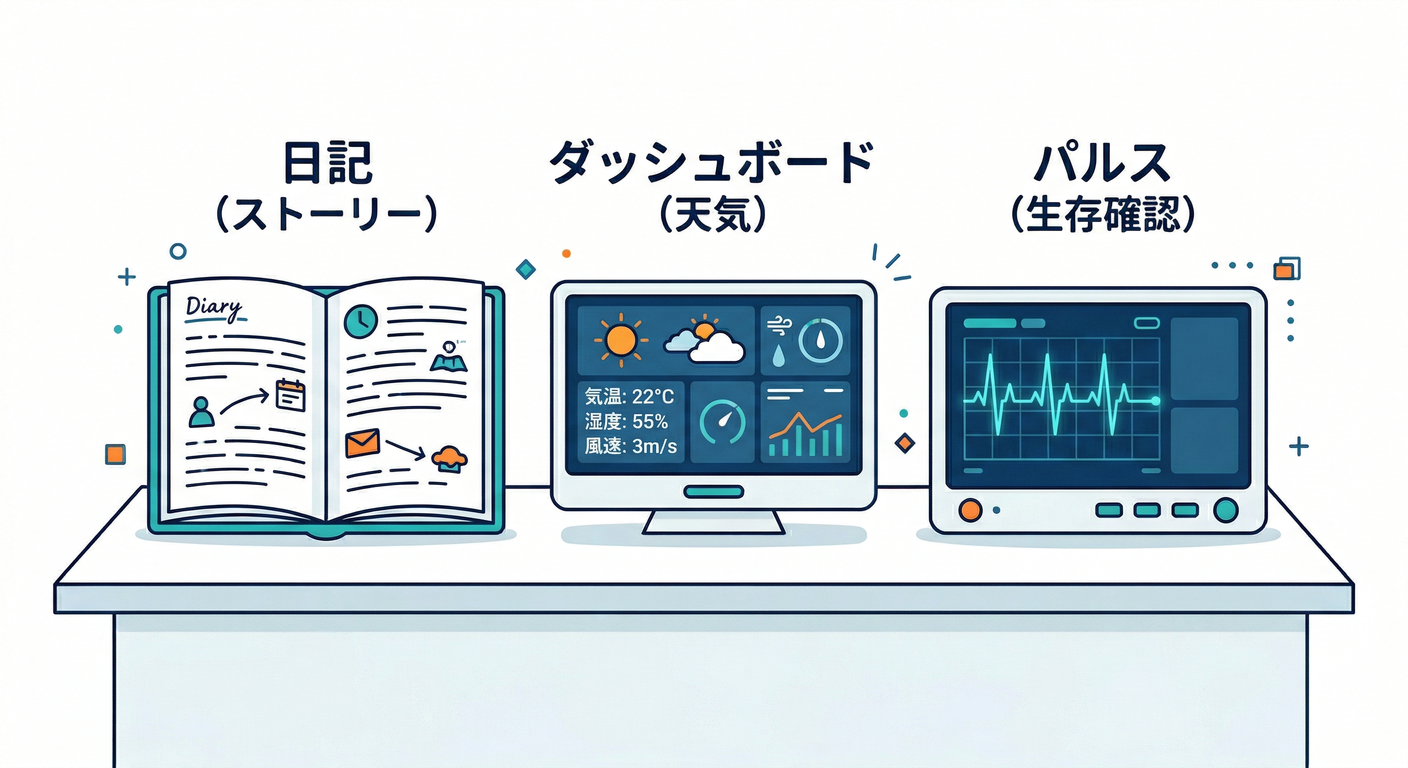
ここ、暗記じゃなくて“納得”でいきましょう😊✨
ログ🧾:出来事の記録(ストーリー)
- 例:
/loginでDB接続エラーが出た、例外がここで投げられた、など - 強いところ💪:「どこで何が起きた?」が分かる
- 弱いところ🥲:量が多いと読むのが大変(ログ地獄😇)
メトリクス📈:数字の推移(天気予報)
- 例:リクエスト数、エラー率、レスポンス時間、CPU、メモリ
- 強いところ💪:「どれくらい悪い?いつから?」が分かる
- 弱いところ🥲:数字だけだと原因の決定打が足りないことがある
ヘルスチェック💚:今使ってOK?の合図(信号機🚦)
- 例:起動できてる?(生存)/依存先に繋がる?(準備)
- 強いところ💪:「復旧したと言っていい?」が分かる
- 弱いところ🥲:重い処理を入れると逆に壊れる(あとでやる⚠️)
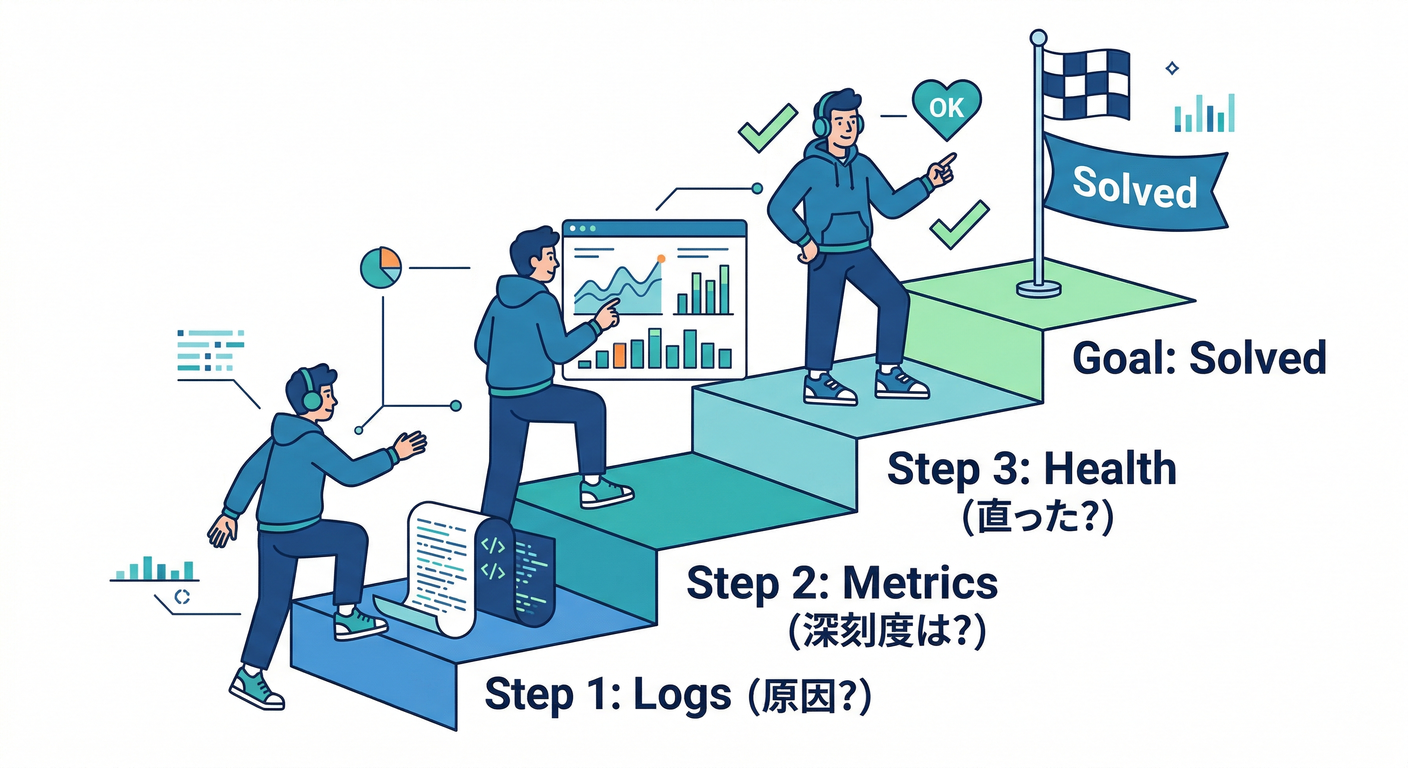
⑤ 3つが「原因」「影響」「復旧判断」に効くイメージ 🔁🧭
トラブル対応で一番ありがちな失敗はこれ👇
- いきなりコードを眺める👀💦
- いきなり再起動する🔁💦
- いきなり「わからん…」ってなる😵💫💦
そこで、型を作ります🧩✨
- ログ🧾で「どこで何が起きた?」(原因の入口🚪)
- メトリクス📈で「どれくらい影響ある?」(被害の広さ🌋)
- ヘルス💚で「戻った?使っていい?」(復旧判定✅)
⑥ ミニ課題(15分)⏳📝
お題:「遅い」「落ちる」「繋がらない」を3つに分類してみる 🎯
次の症状を、まずは直感で分類してみてください👇(正解はあとで✨)
/searchが急に遅くなった 🐢- たまに 500 が返る 💥
- コンテナは動いてるのに、外からアクセスできない 🔌
- 30分前からエラー率が上がってる 📈
- 起動直後だけDB接続に失敗する 🧩
- 「直ったはず」なのに利用者がまだ繋がらないと言う 😵💫
分類先はこの3つ👇
- ログ🧾(原因)
- メトリクス📈(影響)
- ヘルス💚(復旧判断)
⑦ つまづきポイント(3つ)🪤😇
-
ログだけ見て疲れる 🧾🌀 → まずは「エラーの瞬間」や「怪しい時間帯」だけ狙う🎯
-
メトリクスを“全部”取りたくなる 📈🧺 → 最初は少なくてOK!あとで増やす方が強い💪
-
ヘルスに重い処理を入れがち 💚🐘 → ヘルスは“軽く・速く”が基本(詳細はヘルス章でガッツリやるよ😊)
⑧ ミニ課題の答え合わせ ✅✨
「どれを見るのが近道か」って意味での答えです(※最終的には組み合わせることが多いよ!)🔁
/searchが急に遅くなった → メトリクス📈(まず影響の大きさを掴む)- たまに 500 → ログ🧾(どこで落ちたかが命)
- 動いてるのにアクセスできない → ヘルス💚+(必要ならログ🧾)
- 30分前からエラー率が上がってる → メトリクス📈(時間変化が大事)
- 起動直後だけDB接続失敗 → ヘルス💚(準備できてない)+ログ🧾
- 直ったはずなのに繋がらない → ヘルス💚(復旧判断)+メトリクス📈(まだ影響中か?)
⑨ AI活用プロンプト例(コピペOK)🤖📋
例1:症状から「まず見るべき観測データ」を出させる 🧠🔎
あなたはSREの先生です。
症状: 「/search が遅い。たまに500も出る。再起動すると一瞬直る」
このとき最初に見るべき観測データを、
ログ🧾 / メトリクス📈 / ヘルス💚 に分けて、優先順位つきで箇条書きにしてください。
初心者にも分かる理由も1行ずつ添えてください。
例2:切り分け手順を“型”で作らせる 🧩📝
次の障害について、3分で状況把握→10分で原因候補→30分で復旧判断、の手順書を作ってください。
使っていい情報は ログ🧾/メトリクス📈/ヘルス💚 のみ。
各ステップで「見るもの」「分かったら次に何をするか」を箇条書きで。
症状: 「夜だけ遅い。p95が悪化。エラー率は少し上がる。」
⑩ ちょい最新トピック豆知識 ⚡🆕
- 2026年2月時点だと、Node.js は v24 が Active LTS、v25 が Current という整理になっています。(Node.js)
- コンテナのヘルスチェックには
start-periodなどの概念があり、起動直後の不安定時間を“猶予”にできます。(Docker Documentation) - さらに
start-intervalは「起動直後だけチェック頻度を上げる」ためのオプションで、Docker Engine 25.0 以降が必要です。(Docker Documentation) - そして Docker の
depends_onとservice_healthyを使うと、依存先が“healthy”になるまで待ってから起動する流れが作れます(後の章で体験するよ!)(Docker Documentation)
⑪ まとめ 🌈✅
- ログ🧾=原因、メトリクス📈=影響、ヘルス💚=復旧判断
- トラブル時は 原因→影響→復旧判断 の順で迷子にならない 🧭✨
- 次章からは「よくある障害」をパターン分けして、手を動かしていきます🛠️🚀
次は「第2章」の教材本文も、このテンションで“手順・コマンド・期待出力”まで埋めて作るよ😊✨