第29章:三点セットの連携:原因→影響→復旧判断の流れ 🔁🧭
① 今日のゴール 🎯✨
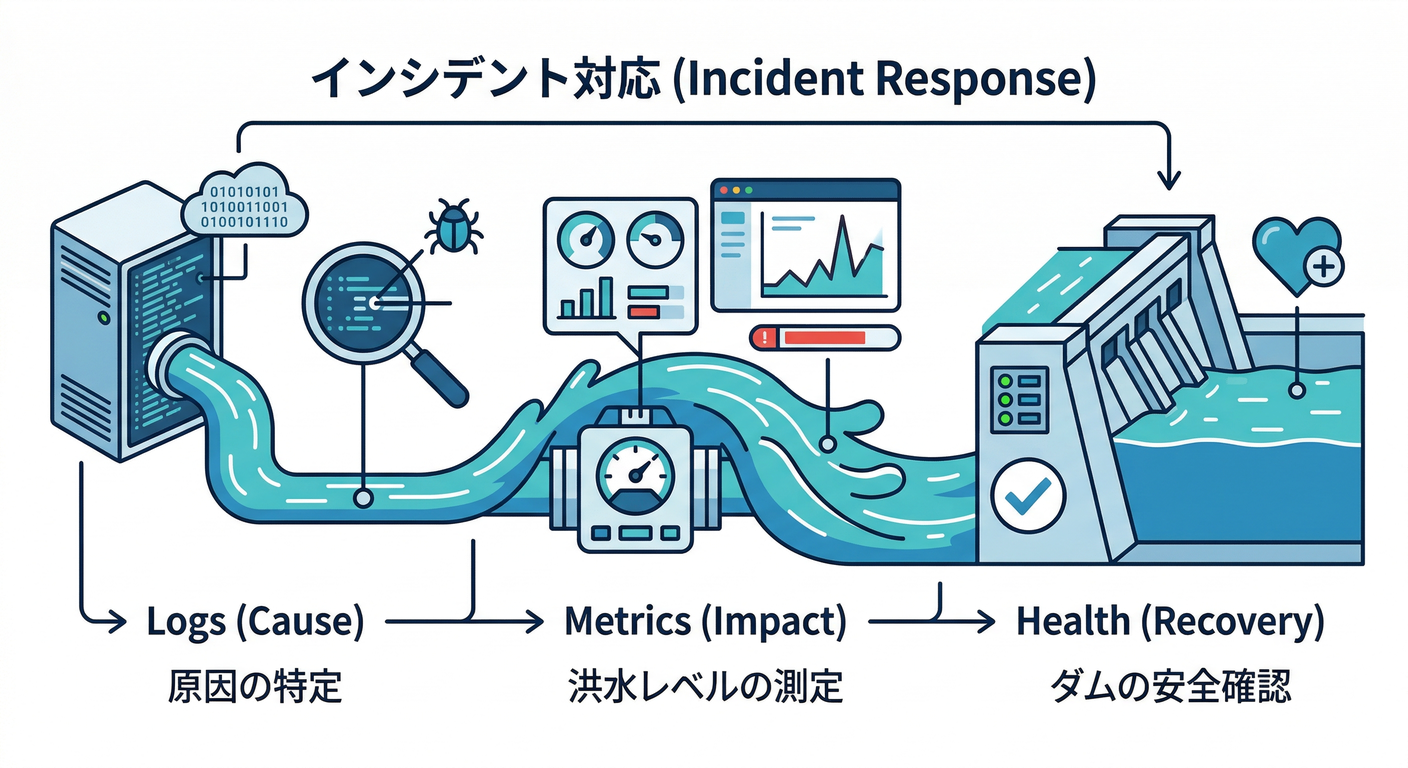
- 障害が起きた時に、迷わず “この順番” で見れるようになる ログ=原因 🧾 → メトリクス=影響 📈 → ヘルス=復旧判断 💚
- そして、3分 / 10分 / 30分で動ける テンプレ手順書(Runbook) を完成させる 📝🔥
② まず頭に入れる「観測の必勝ワード」🧠⚡
観測性って、最近は「集める」より “つなげる” が大事になってます。 ログ・メトリクス・(トレース)を 同じ文脈(ID)で相関 させると、原因特定が爆速になります 🧵🚀 OpenTelemetry でも “コンテキスト伝播でシグナルを相関できる” って明言されています。(OpenTelemetry) また、「別々に集めるだけじゃ足りない、共有コンテキストで結びつけて初めて意味が出る」系の話が、2026年の主流です。(Dash0)
この章では、すでに作ってきた reqId(相関ID) を主役にします 🪪✨ (将来トレースを入れても、同じ考え方で traceId に置き換わるだけ👍)
③ この章で作る成果物 🧰📦
docs/runbooks/incident-triage.md(3分/10分/30分の手順書)scripts/triage.ps1(状況収集のワンコマンド化)※任意だけど超おすすめ🪄- Grafana 側の “見る順番” が固定されたダッシュボード運用(手順書にリンク🔗)
1) “原因→影響→復旧判断” の見取り図 🗺️👀
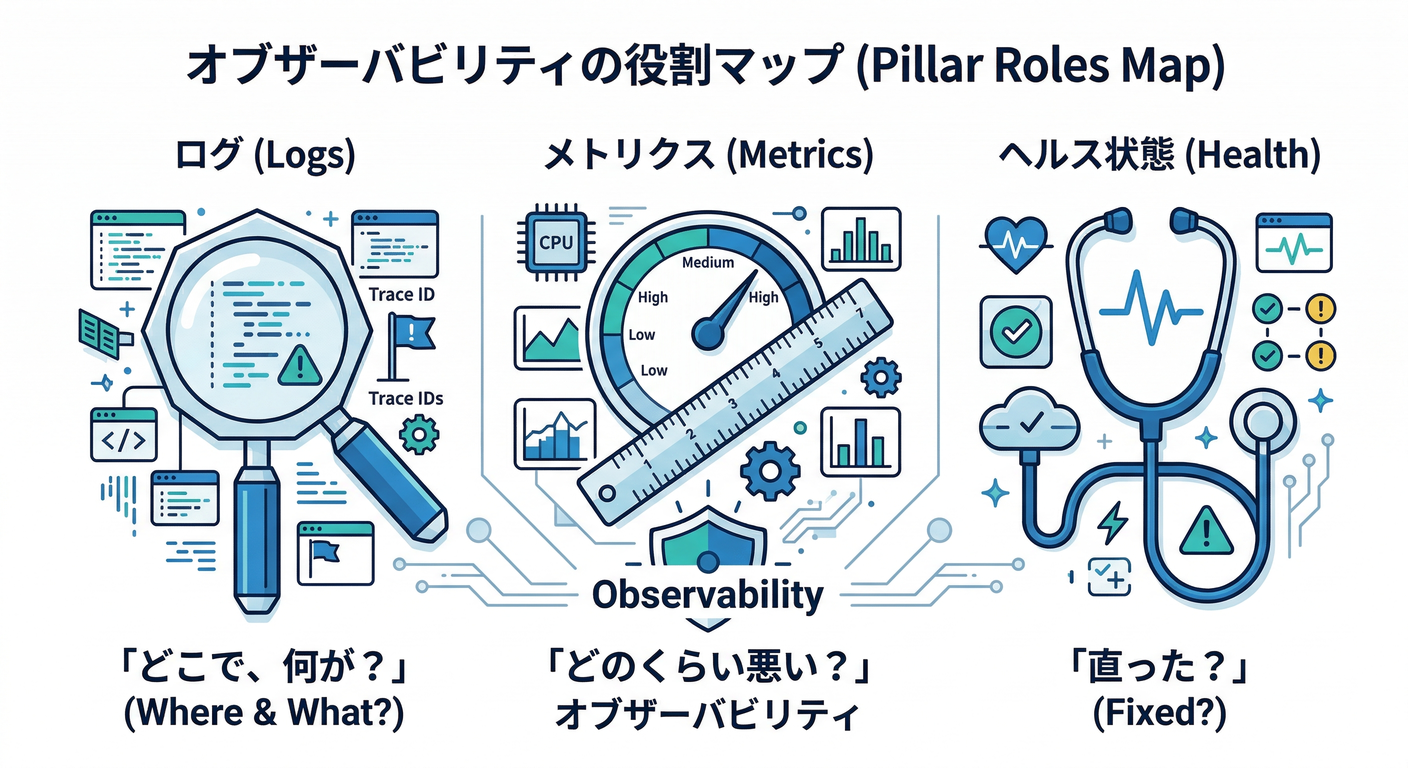
ログ 🧾=「どこで何が起きた?」
- 例:
status=500がどのルートで起きた? - 例:同じ
reqIdの中で、どこで時間が溶けた?🐢
メトリクス 📈=「どれくらい影響が出た?」
- 例:p95 が悪化したのは “全体” か “/slow だけ” か?
- 例:5xx率が上がってるのは今も継続?それとも瞬間風速?
ヘルス 💚=「復旧したと言っていい?」
- 例:
/readyは依存(DB/Redis)が戻ったと判断できる? - 例:Compose/Docker の health が
healthyに戻った?✅
2) 3分 / 10分 / 30分 テンプレ(これが本体)⏱️🔥
✅ 3分テンプレ:まず “今どうなってる?” を言語化する(一次対応)🧯
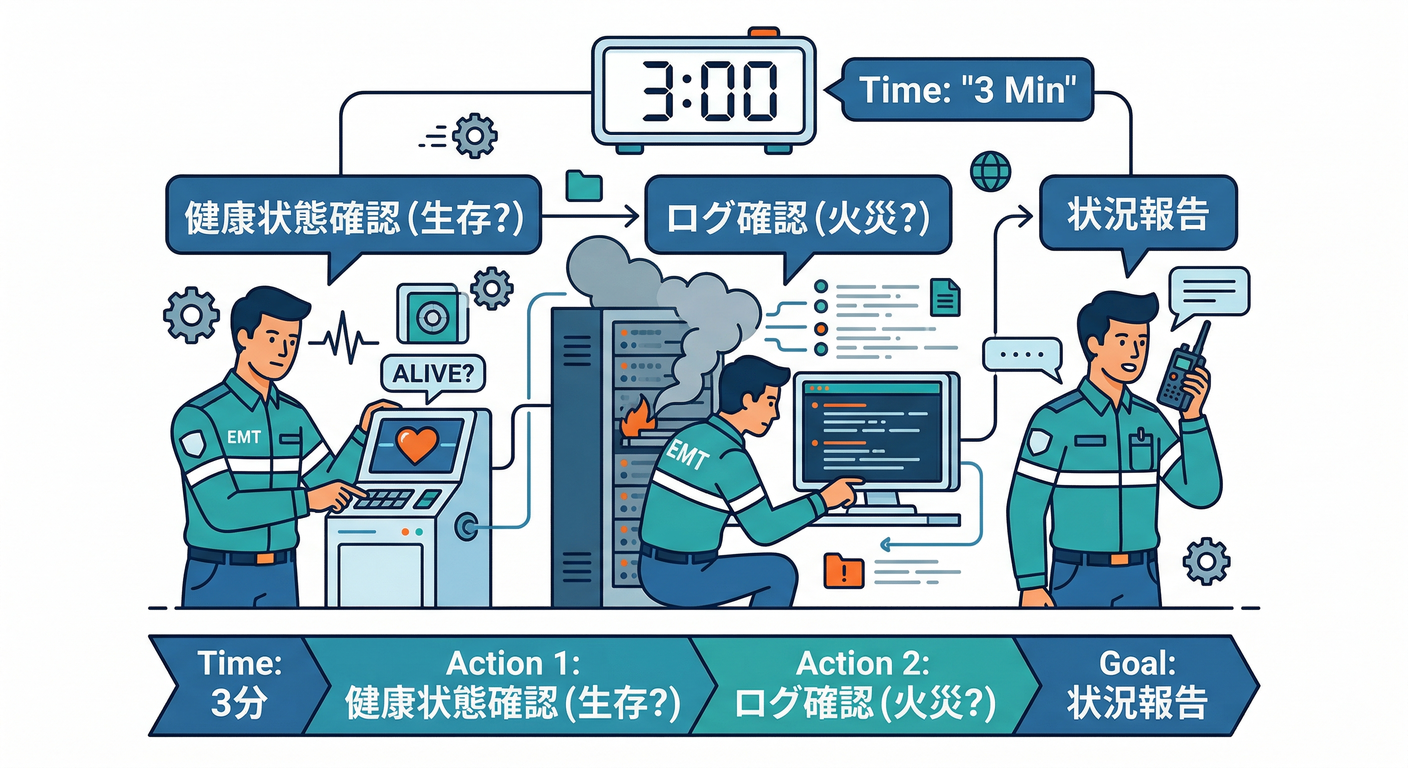
やることは 「現状の一言」+「切り分け方向」 を作るだけ!
(A) まずヘルスで “生きてる?” を見る 💚
- Compose の状態確認(Health 列が出る環境なら最高✨)
docker compose ps
- エンドポイント直叩き(PowerShell)
## ※curl は PowerShell だと別物になりがちなので irm 推奨
irm http://localhost:3000/health
irm http://localhost:3000/ready
(B) 次にログで “今、燃えてる?” を見る 🧾🔥
docker compose logs api --since 10m --tail 200
-
ここで言いたいこと(例)👇
- 「/ready が落ちてる。DB依存っぽい」🔌
- 「5xx が増えてる。特定ルートで例外っぽい」💥
- 「遅い。タイムアウト気味」🐢
3分で作る報告テンプレ(コピペ用)📋
- 症状:何がどう悪い?(例:5xx増、p95悪化、ready落ち)
- 範囲:全体?特定ルート?特定時間だけ?
- 仮説:依存?アプリ?環境?
✅ 10分テンプレ:原因候補を “2〜3個” に絞る(切り分け)🔎🧠
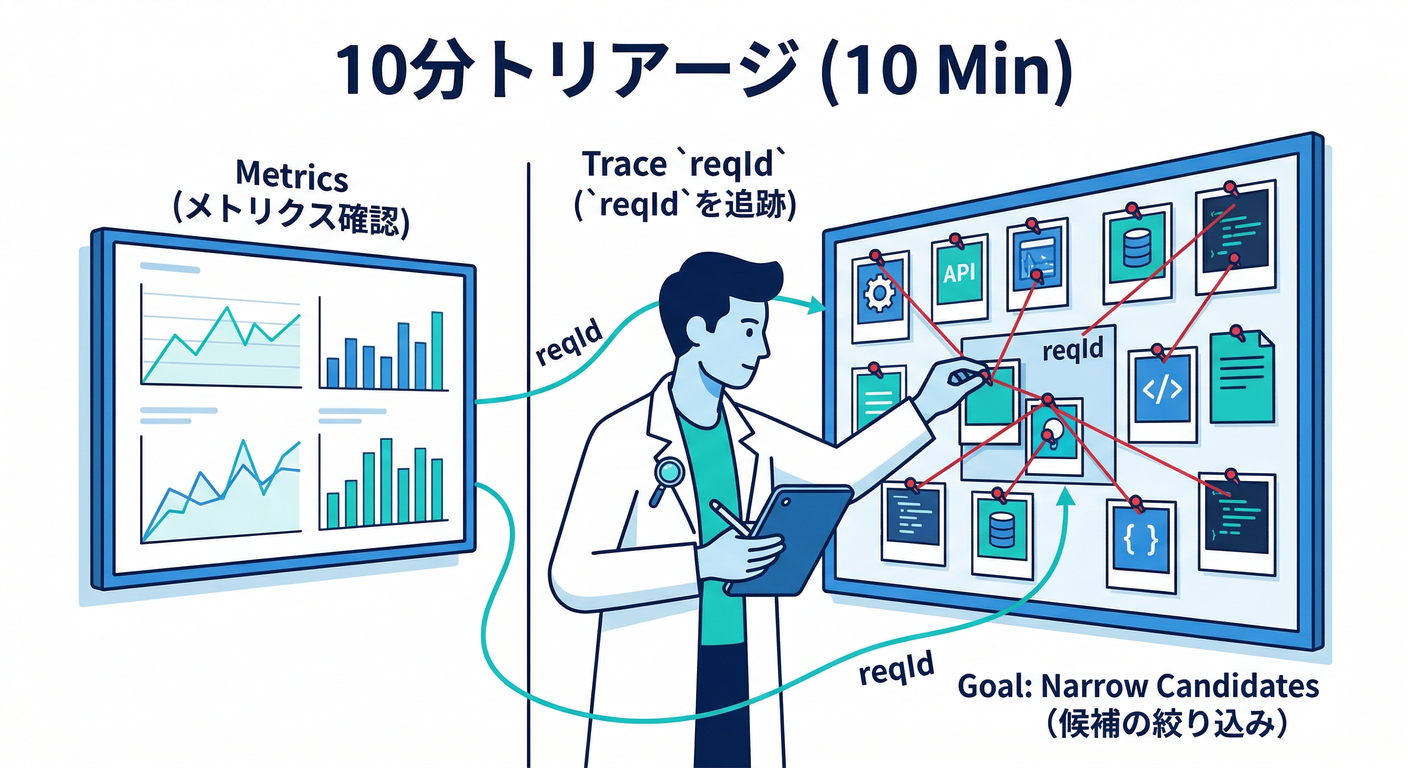
ここからは ログ(原因) と メトリクス(影響) を往復します 🔁
(A) ログ:reqId で 1リクエストを追跡 🧵
- 500 が出た瞬間のログを探す
- その行にある
reqIdを拾う reqIdで検索して、開始〜終了を1本の線で読む
例:ログが JSON なら、こんな形が理想👇
{"level":"error","msg":"handler failed","reqId":"r-8f1c...","path":"/boom","status":500,"ms":12,"err":"..."}
(B) メトリクス:影響を “数字で確定” 📈 Grafana/Prometheus で見る基本4点セット(鉄板)🧱✨
- RPS(流量)
- Error Rate(5xx率)
- p95(遅さ)
- Resource(CPU/メモリ)
PromQL 例(メトリクス名はあなたの実装に合わせて調整してOK)👇
## RPS
sum(rate(http_requests_total[5m]))
## 5xx率
sum(rate(http_requests_total{status=~"5.."}[5m]))
/
sum(rate(http_requests_total[5m]))
## p95
histogram_quantile(
0.95,
sum(rate(http_request_duration_seconds_bucket[5m])) by (le, route)
)
(C) 10分で得る結論(例)
- 「/slow だけ p95 が死んでる → そのルートの処理 or 依存が怪しい」🐢
- 「5xx が全体で増えてる → 共通ミドルウェア/依存/環境」💥
- 「ready が落ちてる → 依存(DB/Redis)復旧が先」🔌
✅ 30分テンプレ:復旧まで持っていく(暫定対応+再発防止の種)🛠️🌱
30分は 復旧判断(ヘルス) を明確にして、次に活かす材料も残します。
(A) 復旧判断の “合格条件” を固定 💚✅
/readyが 安定して OK(一瞬戻った、は信用しない🙅♂️)- エラーレートが 通常域に戻る
- p95 が 通常域に戻る
- (可能なら)ダッシュボードに “復旧時刻” をメモ(アノテーション)📝
(B) Compose の起動順・依存待ちが絡む場合
Compose は depends_on で起動順を制御できます。(Docker Documentation)
さらに condition: service_healthy で “healthy になってから次へ” もできます(環境差はあるので自分の構成で要確認)。(Docker ドキュメント)
(C) 30分でやる “再発防止の種まき” 🌱
- ログに 判断に必要なキーが足りない → 追加(route/status/ms/reqId/errorCode など)
- メトリクスが 粒度不足 → route 別の分解、status 別の分解
- ヘルスが 軽くない / 重すぎる → ready を「軽い疎通」に寄せる
3) ハンズオン:Runbook(手順書)を実際に書く 📝✨
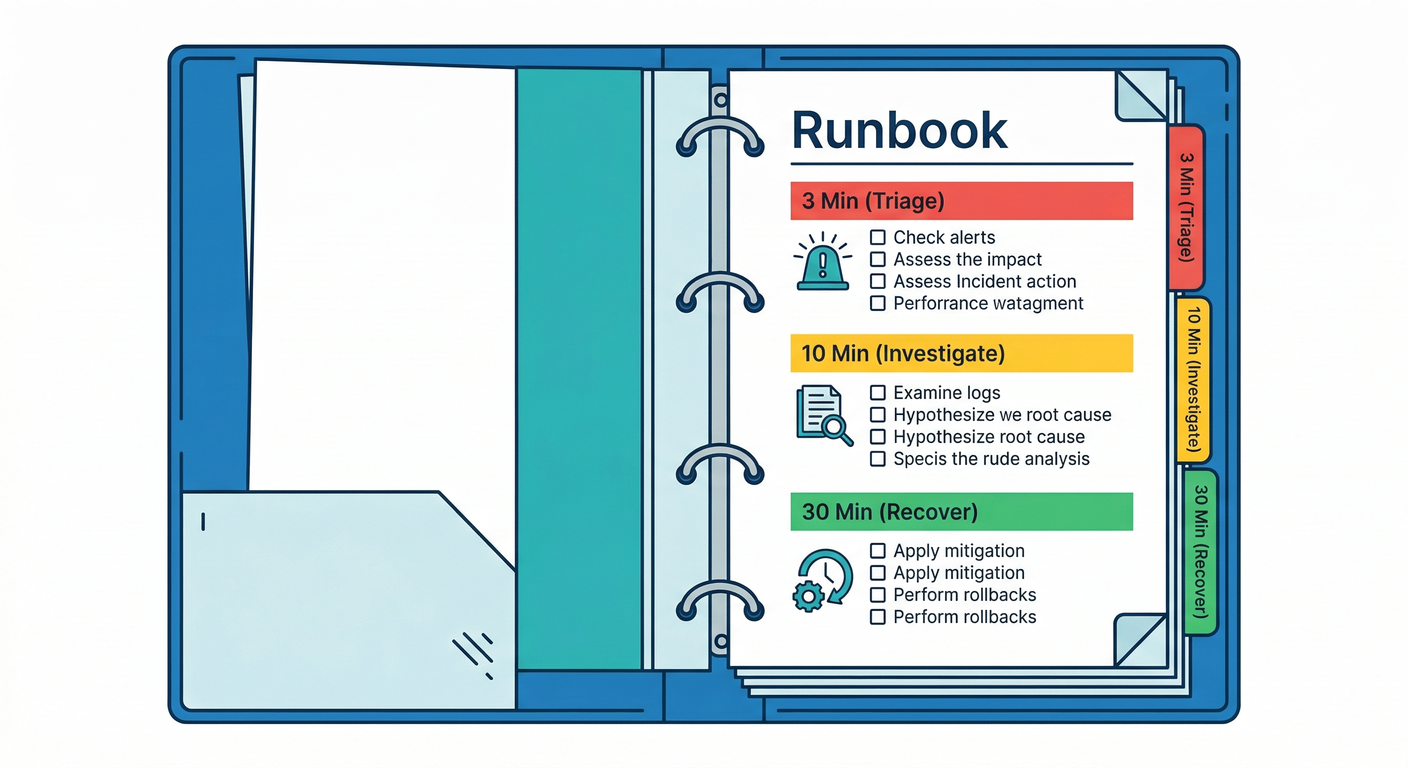
docs/runbooks/incident-triage.md(テンプレ)
## Incident Triage(ログ→メトリクス→ヘルス)
## 0. 3分:一次対応
- [ ] docker compose ps(health確認)
- [ ] /health, /ready を叩く
- [ ] logs を10分だけ見る(500/timeout/connection)
## 現状まとめ(コピペ用)
- 症状:
- 範囲:
- 仮説(依存/アプリ/環境):
## 1. 10分:切り分け
## ログ(原因)
- [ ] 500行を発見
- [ ] reqId を拾う
- [ ] reqId で一連のログを読む
- メモ:怪しい箇所(ファイル/関数/依存)
## メトリクス(影響)
- [ ] RPS
- [ ] 5xx率
- [ ] p95(route別)
- [ ] CPU/メモリ
## 2. 30分:復旧判断
- [ ] /ready が安定OK
- [ ] 5xx率が通常域
- [ ] p95が通常域
- [ ] 復旧時刻をメモ(ダッシュボードにも残す)
## 3. あとでやる(再発防止の種)
- [ ] ログの不足キー
- [ ] メトリクスの不足分解
- [ ] ヘルスの見直し
これがあるだけで、次から脳みそ節約できます 😆🧠✨
4) おまけ:観測スタックの “今どき” 感(2026)🧩🌍
- ログ/メトリクス/(トレース)を 同じ文脈IDでつなぐ のが主流(OpenTelemetry)
- Grafana の “LGTM” みたいに、ログ= Loki / メトリクス= Mimir / トレース= Tempo をまとめて扱う流れも強いです(学習にも相性良い!)(Grafana Labs)
この教材ロードマップは、まさにその入口にピッタリな並びです 👍🔥
5) つまづきポイント(あるある3連発)🪤😵💫
- ログはあるのに追えない → キー不足(reqId/path/status/ms/err が揃ってない)🧩
- メトリクスが “全体” しか分からない → route/status の分解がない📉
- ready が重すぎて逆に落ちる → “軽い疎通” にする(タイムアウト短く)⏱️
6) ミニ課題(15分)⏳🎮
次の3パターンで、Runbook通りに “結論だけ” 書いてみてください👇
- ケースA:
/boomで 5xx 増 💥 - ケースB:
/slowで p95 悪化 🐢 - ケースC:依存(DB/Redis)停止で
/readyNG 🔌
提出物(自分用メモでOK)📝
- 症状 / 範囲 / 仮説(各ケース1行ずつ)
7) AIに投げるプロンプト例(コピペOK)🤖📋
あなたはSREの先輩です。
以下の観測データ(ログ断片/メトリクス変化/ヘルス結果)から、
1) 原因候補を3つに絞って
2) 次に確認すべきログ検索キーとPromQLを提案して
3) 復旧判定のチェック項目を箇条書きで出してください。
制約:
- 3分/10分/30分の順で
- “確度” を 低/中/高 で付ける
- 最後に Runbook へ追記すべき改善点も1つ出す
(ログやメトリクスを貼り付けて使うと、めちゃ効きます💪✨)
✅ この章のチェック(達成判定)🏁🎉
- 「3分で現状説明」が言える 🗣️
- 「10分で原因候補が2〜3個に絞れる」🔎
- 「30分で復旧判断の合格条件が固定されてる」💚✅
- Runbook が
docs/に置かれてる 📝📦
次の第30章は、このRunbookを使って “観測性デバッグRPG” を回して、ほんとに体に覚えさせます 🎮🧨🩹