第23章:“見る文化”を作る:運用ルーチン化 🧹📅
道具(ログ🧾・メトリクス📈・ヘルス💚)が揃っても、見なければ何も起きません😇 この章は「毎日ちょっと見る」→「異常に気づく」→「説明できる」までを“習慣化”します✨ Prometheus と Grafana Labs を使って「3分で健康診断」できる形にします。
① 今日のゴール 🎯
- 朝の3分で「落ちてない?遅くない?エラー増えてない?」を言える🗣️
- ダッシュボードに 「今日の健康状態」 パネル(Row)を作る🧩
- 何か変だったら、次に何を見るか(深掘り順)を決める🧭
② 図(1枚)🖼️
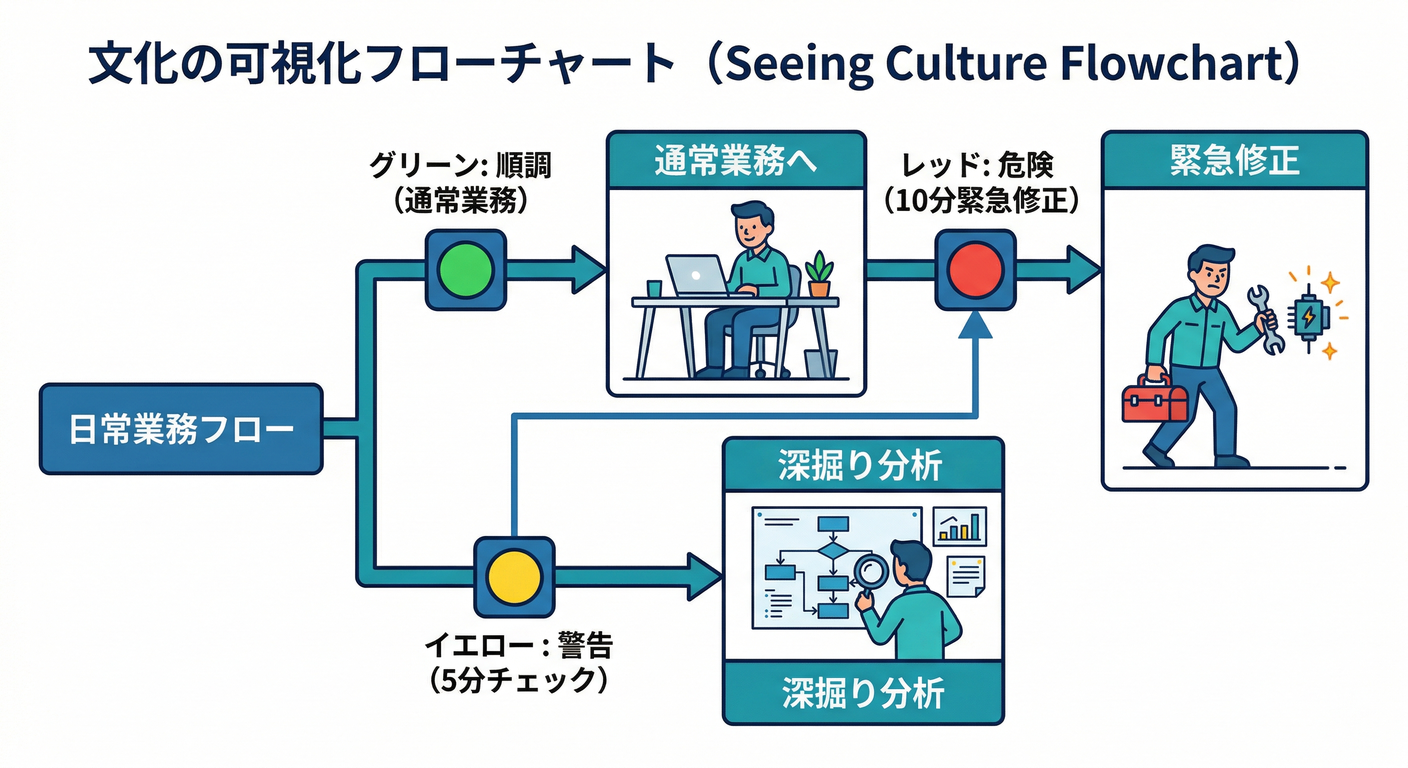
「見る文化」ってつまりこれ👇
- 🟢 健康:いつも通り → そのまま作業へ
- 🟡 注意:数字が黄信号 → 5分だけ深掘り
- 🔴 危険:赤 → 10分で状況説明+応急処置へ
③ 手を動かす(手順)🛠️✨
STEP 0:まず“固定”する(バージョンをピン留め)📌
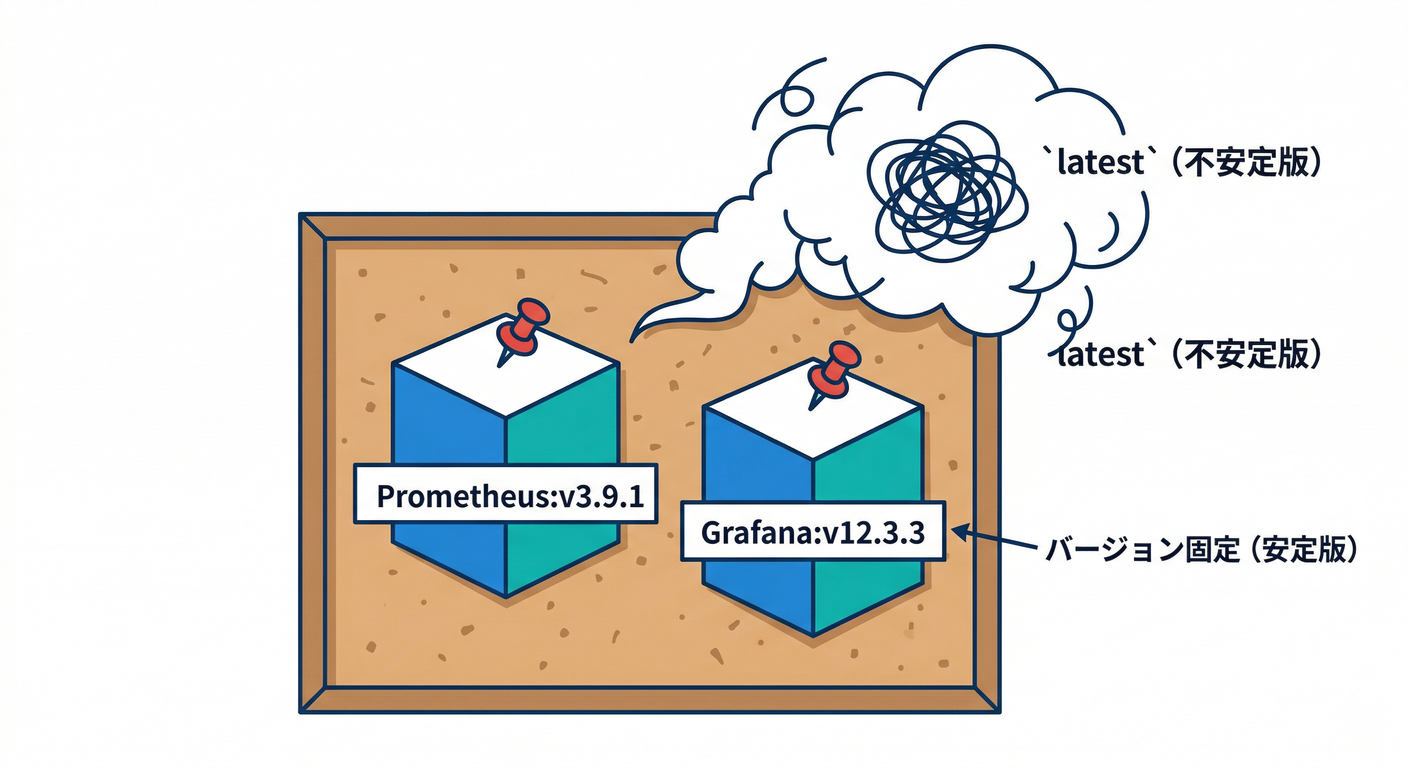
運用ルーチンって、道具が毎回違うと崩壊します😂
なので Compose では latest を避けて、バージョンを固定しておくのが強いです💪
- Grafana は 12.3.3 が 2026-02-12 時点で公開(ダウンロードページ上)されています。(Grafana Labs)
- Prometheus は 3.9.1 が 2026-01-07 の “Latest” として公開されています。(prometheus.io)
(例:compose のイメージ固定イメージ)
services:
prometheus:
image: prom/prometheus:v3.9.1
grafana:
image: grafana/grafana:12.3.3
Prometheus は公式に Docker イメージ提供があり、Docker Hub / Quay などで使えます。(prometheus.io)
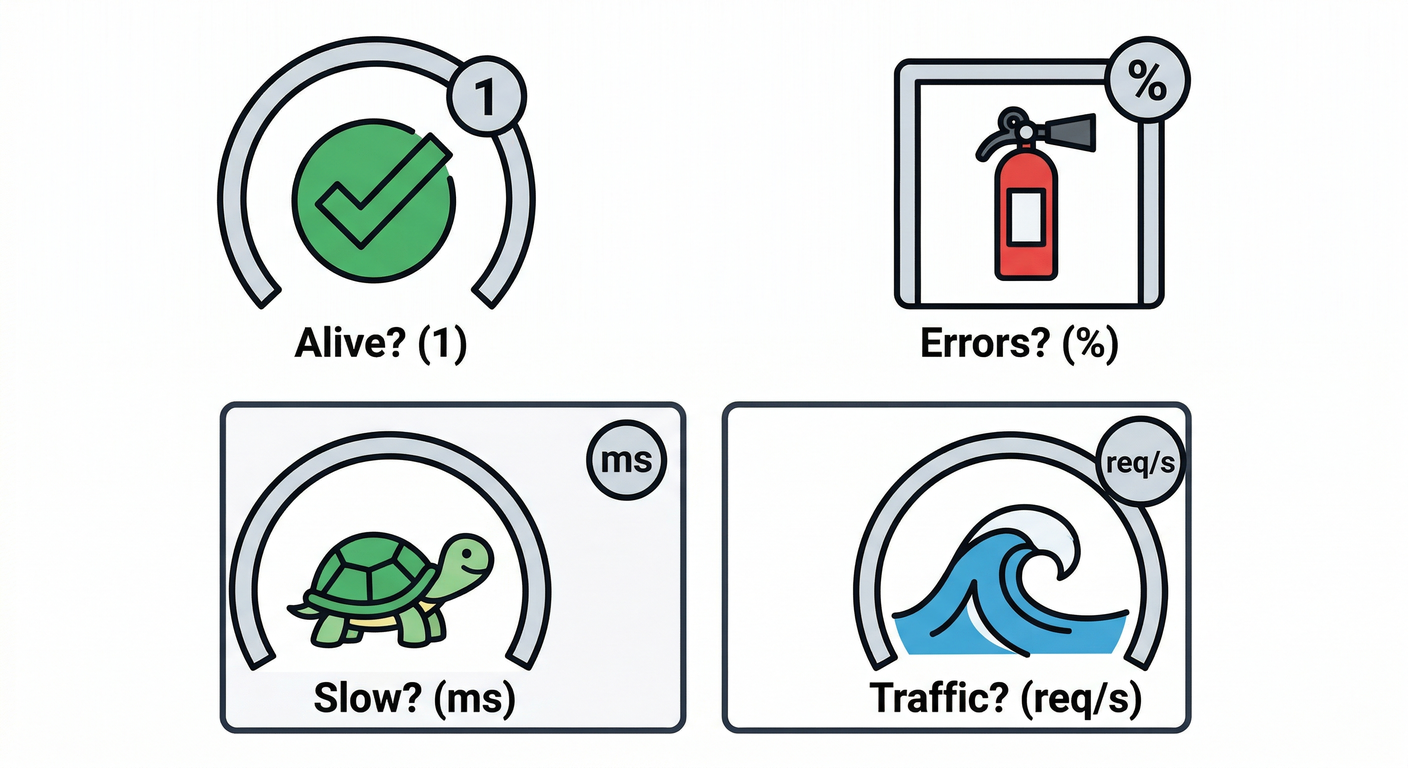
STEP 1:「朝イチ 3分チェック」の項目を決める ☀️⏱️
“毎日見るもの”は、少ないほど続きます🧠✨ この4つでOKです👇
- Up(生きてる?) ✅
- エラー率(増えてない?) 🧯
- 遅延(p95が悪化してない?) 🐢
- トラフィック(急増/急減してない?) 🌊
STEP 2:「今日の健康状態」Row を作る 🧩🩺
2-1. Row を作る(見出し枠)🧱

- Grafana を開く → Dashboards → New dashboard
- Add → Row
- Row のタイトルを
今日の健康状態にする 🏷️
2-2. Stat パネルを4つ置く 📊✨
それぞれ Stat(数値をドン!と見せるやつ)で作るのが分かりやすいです😆
パネルA:Up ✅(落ちてない?)
PromQL(例)
up{job="api"}
-
期待:
1なら OK、0は「監視できてない or 死んでる」💀 -
Stat の色(Threshold)例:
0→ 🔴1→ 🟢
パネルB:エラー率(5分)🧯(5xxが増えてない?)
PromQL(例:5xx率)
sum(rate(http_requests_total{job="api",status=~"5.."}[5m]))
/
sum(rate(http_requests_total{job="api"}[5m]))
-
Threshold 例(雑でOK!後で調整)
> 0.01(1%)→ 🟡> 0.05(5%)→ 🔴
パネルC:p95(5分)🐢(遅くなってない?)
PromQL(例:p95)
histogram_quantile(
0.95,
sum by (le) (rate(http_request_duration_seconds_bucket{job="api"}[5m]))
)
-
Threshold 例
> 0.5(0.5秒)→ 🟡> 1.0(1秒)→ 🔴
パネルD:RPS(5分)🌊(急に増えた?減った?)
PromQL(例:秒あたりリクエスト数)
sum(rate(http_requests_total{job="api"}[5m]))
- ここは “赤/黄” じゃなくて、変化に気づくのが目的👀
- 例えば「いつも 2〜3 なのに 20 になってる」みたいなのを拾う🎣
STEP 3:3分で“状態説明”できるようにする 🗣️✨
ダッシュボードを見たら、このテンプレで声に出して説明します(マジで効きます)😆
- ✅ Up:
1(生きてる) - 🧯 5xx率:
0.2%(問題なし) - 🐢 p95:
320ms(通常) - 🌊 RPS:
2.4(いつも通り)
これが3分で言えたら勝ち🏆
STEP 4:深掘り順(迷わないための“次の一手”)🧭🛟
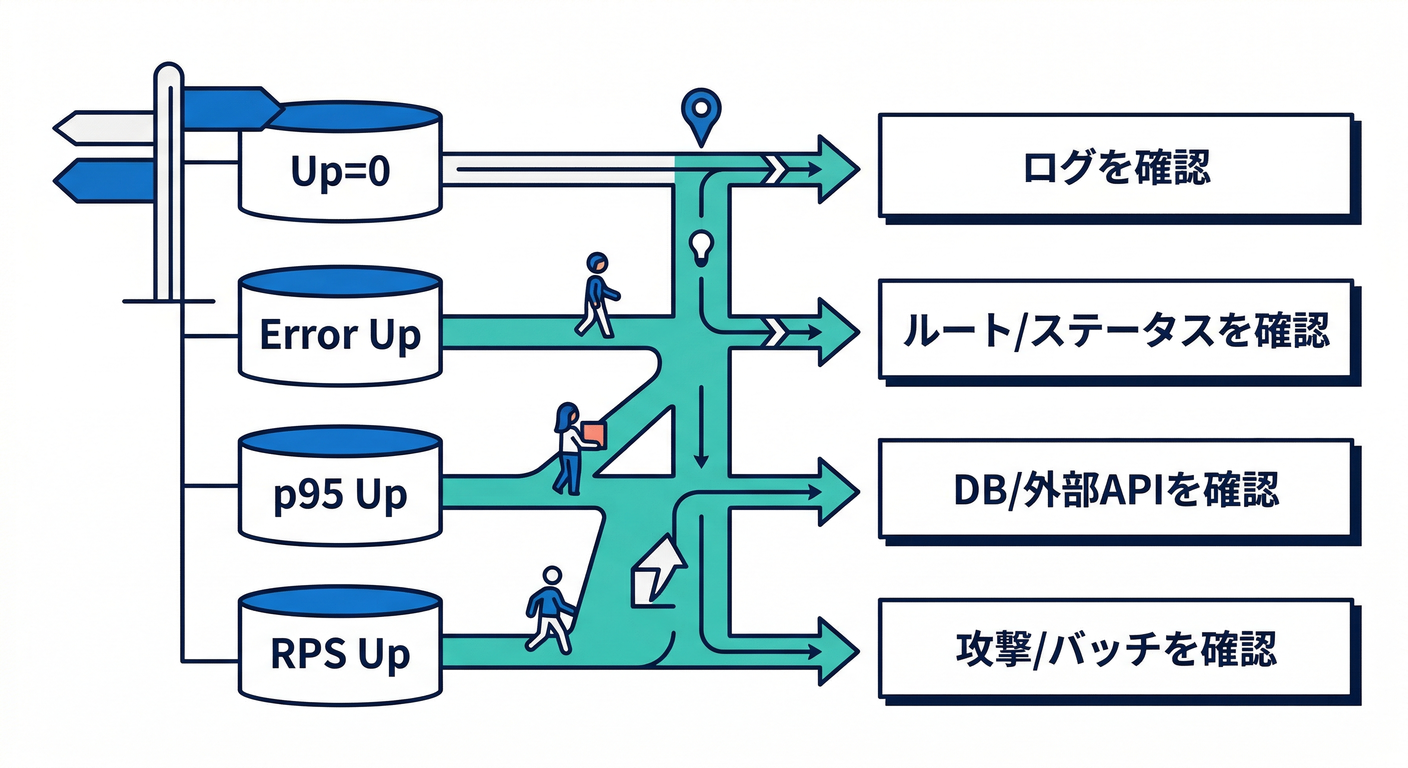
「どれが黄色/赤か」で、次に見る順番を固定しちゃいます👇
- 🔴 Up が 0 → まず コンテナ起動状態 / 直近ログ 🧾
- 🔴 5xx率が上がった → エラーの多い route / status を見る → 該当ログへ 🧾
- 🔴 p95 が悪化 → 遅い route を見る → 外部依存(DB/外部API)疑い
- 🌊 RPS が急増 → まず 正当な増加か(バッチ/クローラ/攻撃?)を判断
STEP 5:“共有できる形”にする(文化ポイント)🤝📌
5-1. スクショ共有をルーチンにする 🖼️📣
Grafana 12.3 では ダッシュボードを PNG でエクスポートできる機能が追加されています。(Grafana Labs) 朝イチで「今日の健康状態」だけ画像で貼れると、チームが一気に“見る人”になります📈✨
5-2. ダッシュボードを「コード管理」できると最強 🧰📦
Grafana は provisioning(YAMLでダッシュボード読み込み)に対応しています。(Grafana Labs) さらに最近は Git Sync が “おすすめ” として案内されています(Grafana 12 の流れ)。(Grafana Labs) → 文化としては「ダッシュボードもGitで管理」が完成形です😎
(ここは“余裕が出たら”でOK!今日はUIで作れれば十分👍)
STEP 6:週次・月次のルーチン(見る文化の完成)📅✨
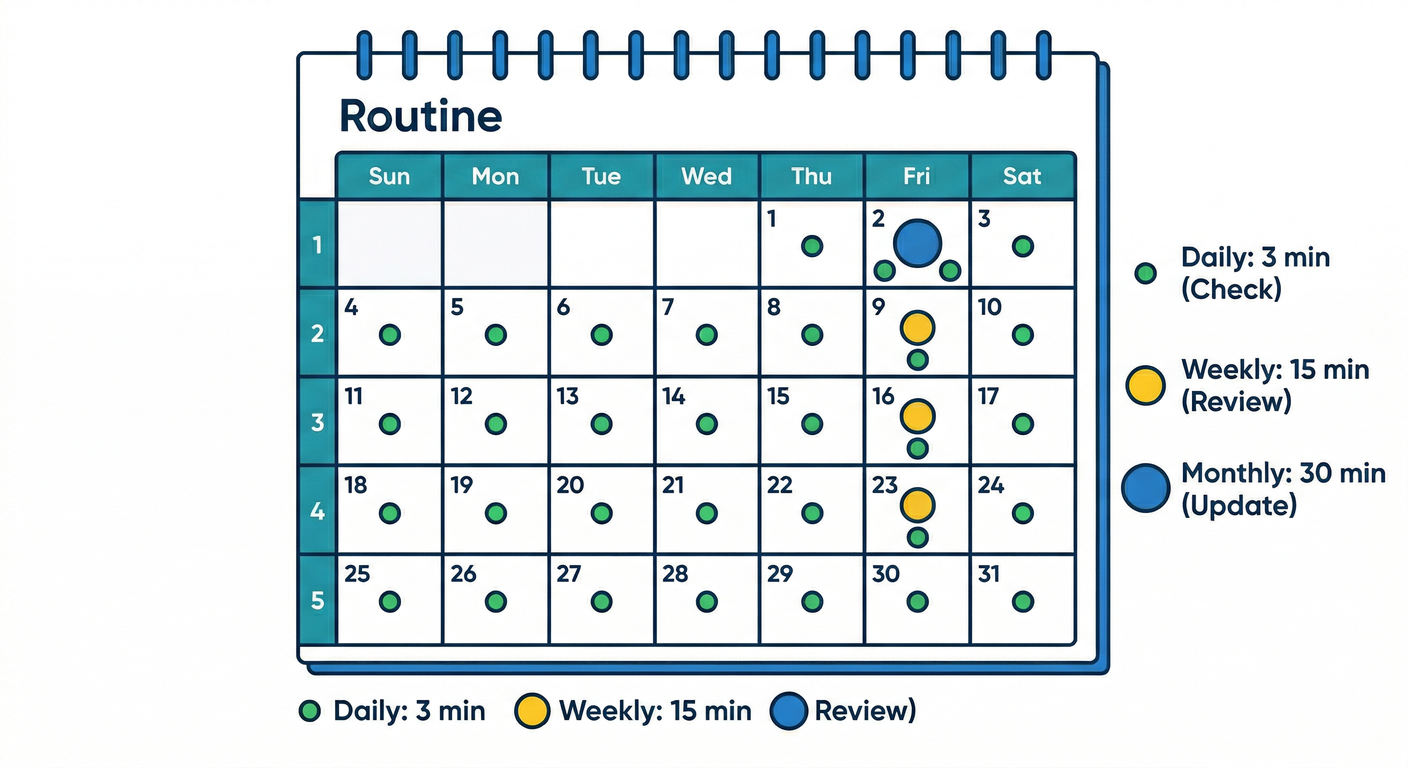
毎日(3分)☀️
- 今日の健康状態(4パネル)を見る
- 変だったら 5分深掘りして「何が起きてるか」だけメモ📝
毎週(15分)📆
- p95 が悪化した日を探す
- 5xx が出たルートTOP3を確認
- 「今週の学び」を1行で残す(例:
/slow は外部API待ちだった)✍️
毎月(30分)🧹
-
アラート(前章)で 鳴りすぎを減らす
-
ツール更新日を決める(“更新の儀式化”)
- Prometheus はリリースサイクルが短く(例:6週ごとの minor 開始)アップグレードが前提になりやすいです。(prometheus.io)
- → 「月1回アップデート」みたいに固定すると平和🕊️
④ つまづきポイント(あるある)🪤😵💫
- クエリが “No data” 😭
job="api"が違う可能性大! → Explore でupだけ打って、出てきたラベルをコピペしよう📋
- エラー率が NaN 🤔
- 分母(全リクエスト)が 0 の瞬間に割り算すると起きがち → アクセスが少ない環境では「しばらく待つ」でOK😂
- p95 が出ない 🐢
- ヒストグラムのメトリクス名(
*_bucket)が違う可能性 →*bucketを検索して見つけるのが早い🔎
⑤ ミニ課題(15分)⏳🔥
課題A:3分スピーチ🎤
今日の健康状態を開く- さっきのテンプレで 3分説明する
- その内容を1行メモ(Slack/Notion/メモ帳どこでも)📝
課題B:わざと黄色にする😈
/boomで 5xx を増やす → エラー率が上がるのを見る🧯/slowを叩く → p95 が悪化するのを見る🐢- 「何が変わったか」を1行で書く✍️
⑥ AIに投げるプロンプト例(コピペOK)🤖📋
1)しきい値を“現実的に”したい
私のAPI監視ダッシュボードで、Up/5xx率/p95/RPSを毎朝3分で見る運用にしたい。
「小規模個人開発」を前提に、しきい値(黄/赤)と理由を提案して。
2)PromQL が合ってるか不安
このPromQLが何を意味するか、初心者向けに説明して。
(PromQLを貼る)
3)“深掘り順”をもっと具体化したい
朝の健康チェックで「Up=OKだが、5xx率が増加、p95も悪化」という状況になった。
次に見るべき順番を、ログ→メトリクスの観点で10分手順にして。
次章(第24章)はヘルスチェックの「生存/準備/起動」の違いに入るので、この章で作った“見る習慣”がそのまま効いてきます💚🩺
必要なら、あなたのダッシュボードのメトリクス名(http_requests_total とか)に合わせて、PromQLを“実名版”に書き換えたテンプレも作るよ〜😆✨