第16章:キューって何?どこで効く?📨🤔
この章は「キュー(Queue)」を “使う理由” が腹落ちする回です🙂 次の章(第17章)で Redis ベースのキューを実際に導入していくので、その前に 考え方の土台 を作ります🧱✨
この章のゴール🎯
- 「キューって結局なに?」を 一言で言える 🗣️
- 「どんな処理をキューに逃がすと気持ちいいか」を 判断できる ✅
- “APIが投げる / Workerが処理する”の 構図が頭に描ける 🧠🖼️
1) まず結論:キューは「あとでやる箱」📦⏰

キューは超ざっくり言うと、
- 今すぐやらなくていい処理 を
- “やることリスト”として貯めておいて
- 別の人(Worker)が順番に片付ける仕組み
です📨➡️👷♂️➡️✅
メッセージキューは「非同期のサービス間通信」で、メッセージは処理されるまでキューに保存され、処理されたら削除される…みたいな説明が定番です。(Amazon Web Services, Inc.)
2) たとえ話で理解する🍜🧾
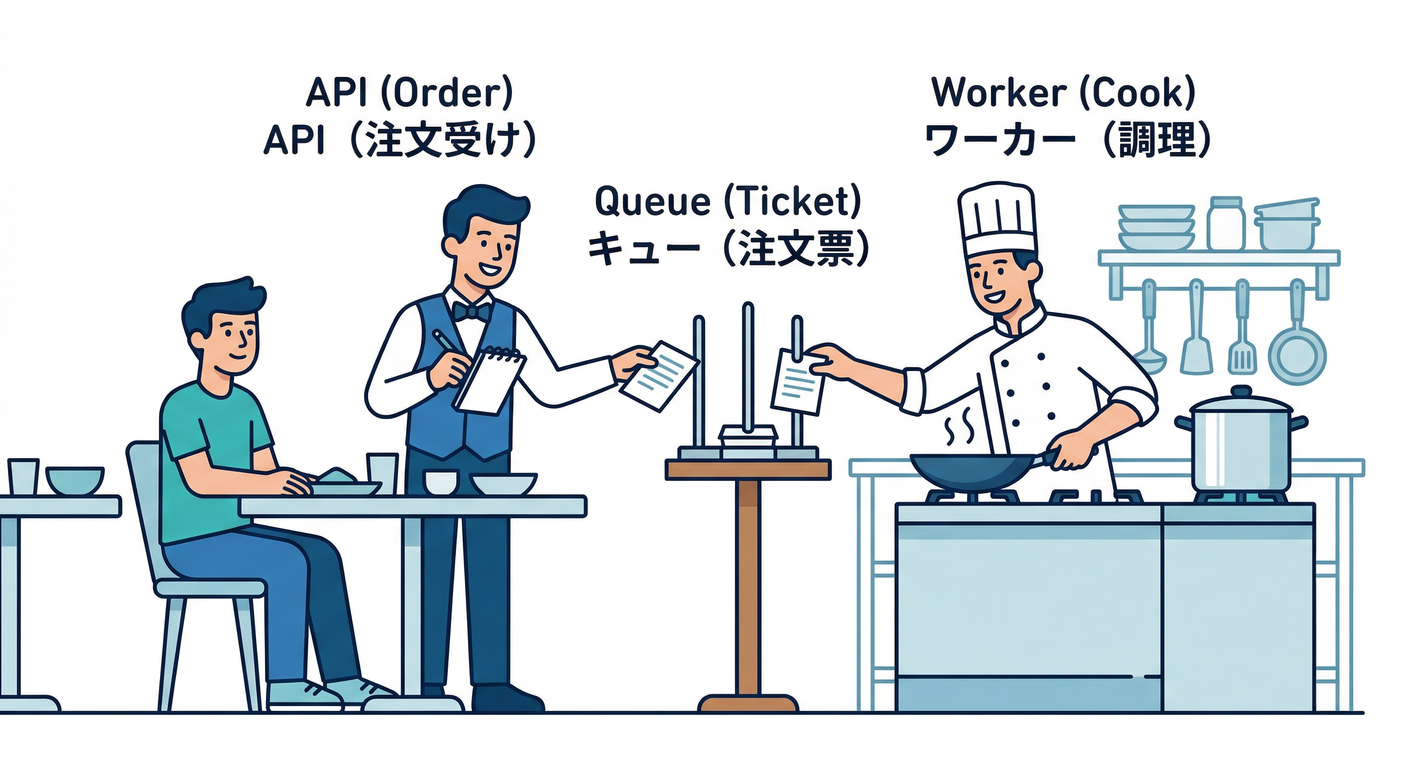
🍽️ 飲食店モデル
- お客さん:API を呼ぶユーザー
- 店員:API サーバー(注文を受ける)
- 伝票:キュー(注文=ジョブ)
- 厨房:Worker(重い処理をやる)
店員が 注文を受けた瞬間に料理まで作り始めたら、レジ前が大渋滞しますよね😇 だから「伝票を厨房に投げて、店員は次の注文へ」って分業する。これがキューの気持ちよさです✨
3) “同期”と“非同期”の違いを体感する⚡
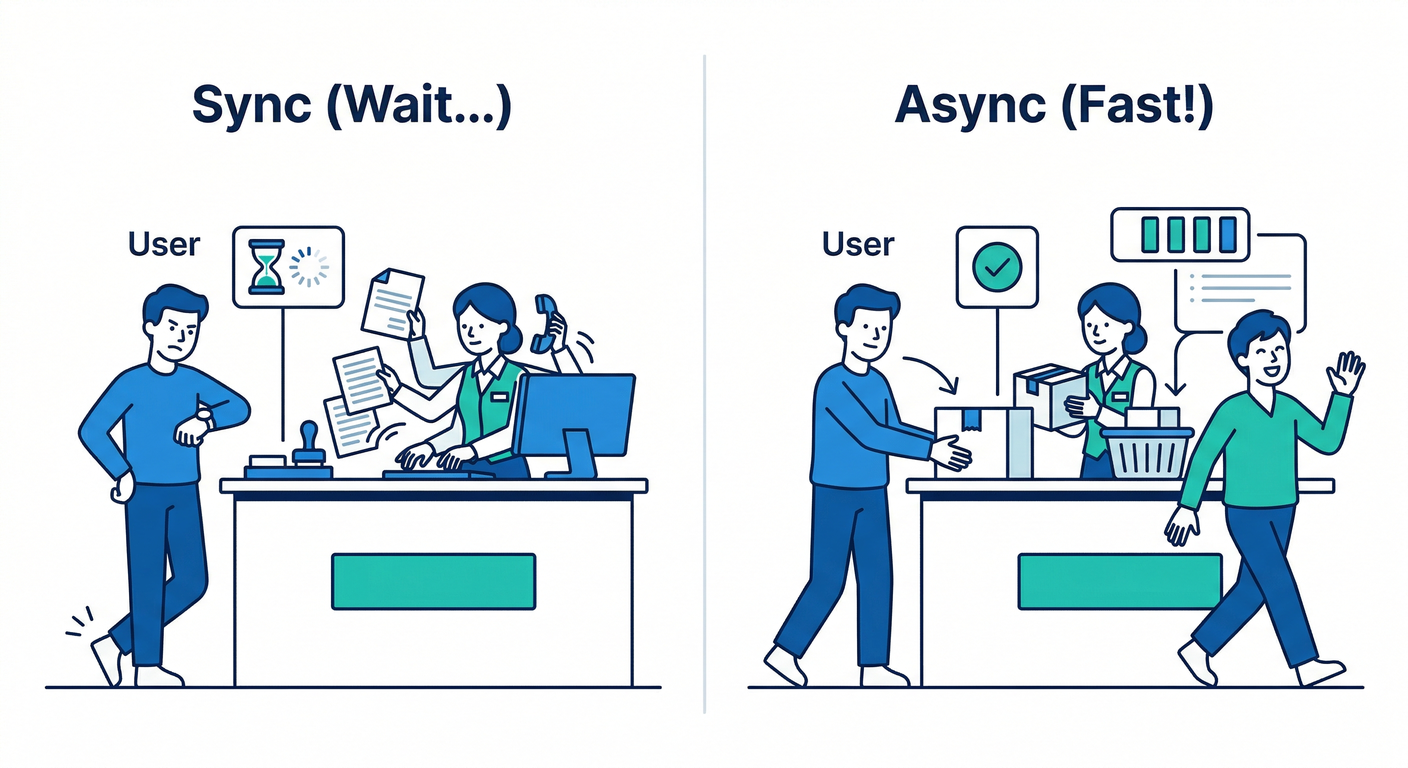
❌ 同期(キューなし)
ユーザー操作 → API → 重い処理(数秒〜数十秒) → やっとレスポンス 😵💫
- 体感が遅い
- タイムアウトしがち
- 途中で落ちたら最初からやり直し…になりがち
✅ 非同期(キューあり)
ユーザー操作 → API → キューに「ジョブ」を入れる → すぐレスポンス 🏃♂️💨 その後、Worker が裏で処理して、完了したら結果を保存したり通知したり📩✨
4) キューが効く “あるある用途” ベスト8🏆
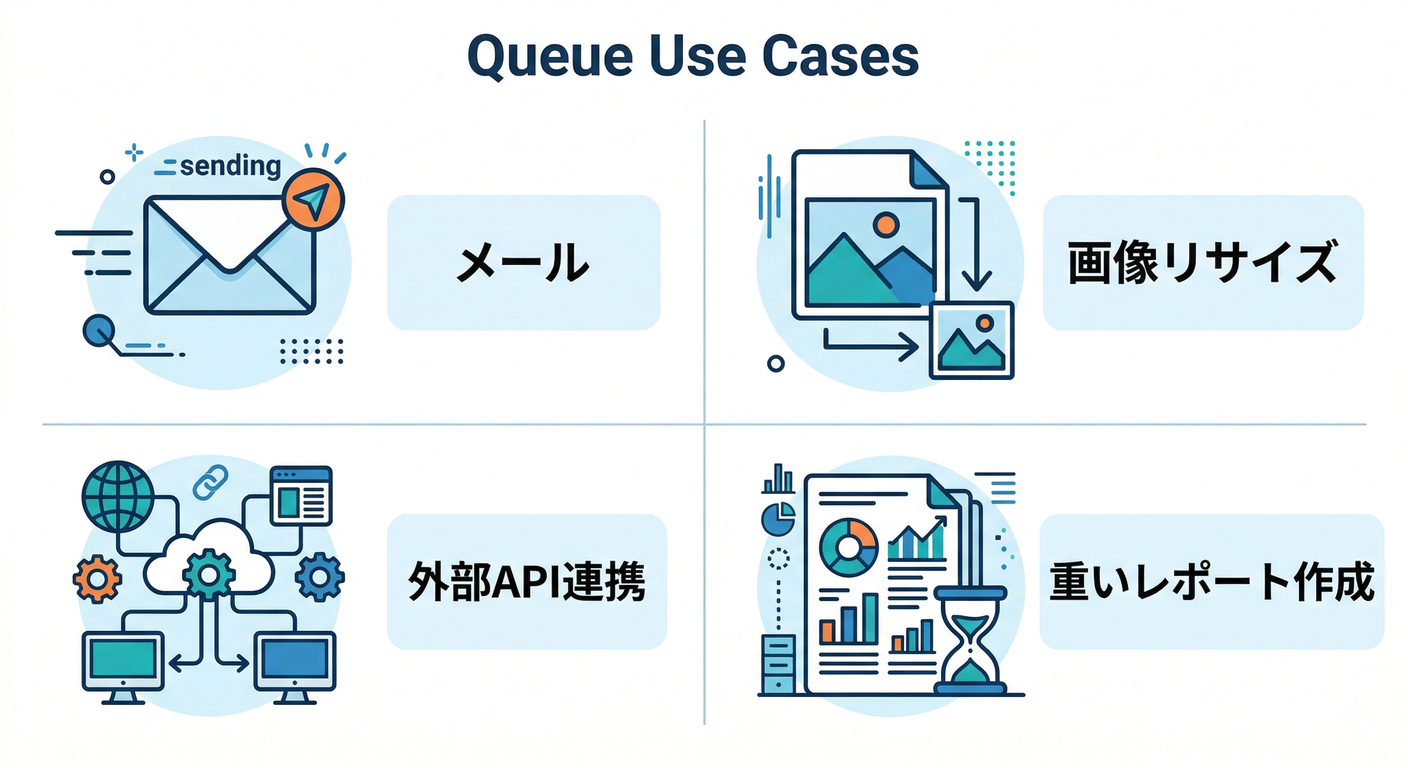
「重い」「待たせたくない」「失敗しやすい」「混む」系は、だいたいキューが刺さります🎯
- メール送信(登録確認メール / パスワード再発行)📧
- 画像変換・サムネ生成 🖼️
- 動画変換 🎞️(激重)
- 外部API連携(レート制限があるやつ)🔌⛔
- 集計・レポート作成 📊
- CSV/ZIPの取り込み 📥
- 通知(Push/Slack/LINE等) 🔔
- 定期処理の実行(スケジュール)🗓️
AWS も「重い処理を切り離す」「スパイク(急なアクセス増)をならす」用途を明確に挙げています。(Amazon Web Services, Inc.)
5) 逆に、キューに向かないもの🙅♂️
全部をキューにすると逆に辛くなります😂
- “今すぐ結果が必要”(0.2秒の体験が大事な検索など)⚡
- 強い一貫性が必要(その場で在庫確定しないと困る、など)🧾
- 処理が軽すぎる(ただの文字列整形程度)🪶
- 設計が追いついてない状態での“とりあえずキュー”(デバッグ地獄の入口)🔥
👉 コツは 「ユーザーを待たせたくない」「失敗しても復旧したい」「混雑を吸収したい」 のどれかがある時に使う👍
6) キューの登場人物(最低限だけ)👨👩👧👦
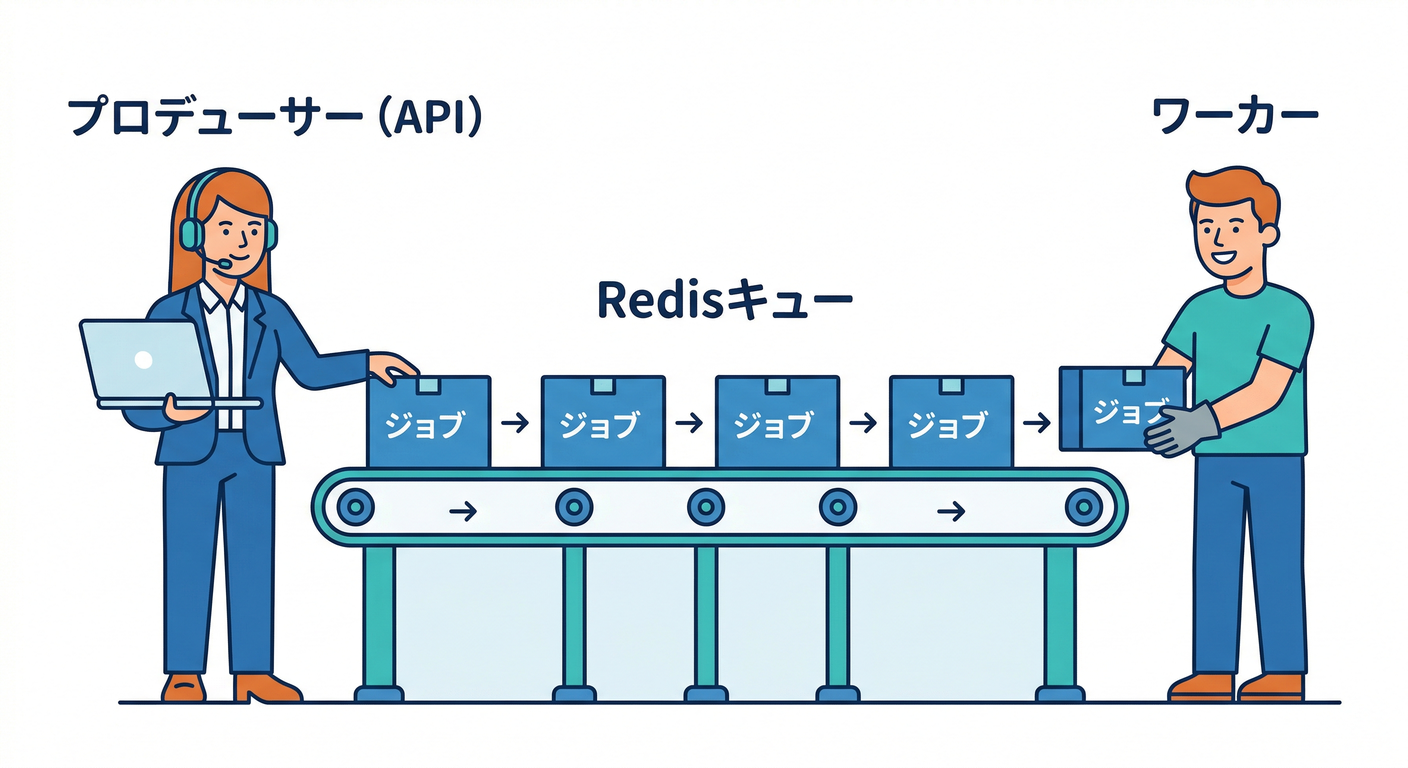
- Producer(プロデューサ):ジョブを作ってキューに入れる人(=API側)📮
- Queue(キュー):ジョブが並ぶ場所(今回の教材では Redis が担当)📦
- Worker / Consumer:ジョブを取り出して処理する人(=別プロセス/別コンテナ)👷♂️
- Job(ジョブ):実行したい作業そのもの(データ付き)🧾
AWS の説明でも「送る側(producer)と受け取る側(consumer)を分離するバッファ」だと整理されています。(AWS ドキュメント)
7) “最低限こう考える” 3つの性格🧠✨
(A) キューは「分業」の道具🧩
API は 受付 に集中 Worker は 作業 に集中 → 役割が分かれて設計がラクになります🙂
(B) キューは「混雑吸収」の道具🧯
アクセスが急増しても、いったんキューが受け止めてくれる Worker は落ち着いて順番に処理できる🏗️
(C) キューは「失敗に強くする」道具🔁
処理が失敗したらリトライできる 落ちても再開しやすい (第19章で “リトライ設計” をやります🧯)
8) 超重要:キューは “重複” が起こりうる😈(だから対策が必要)
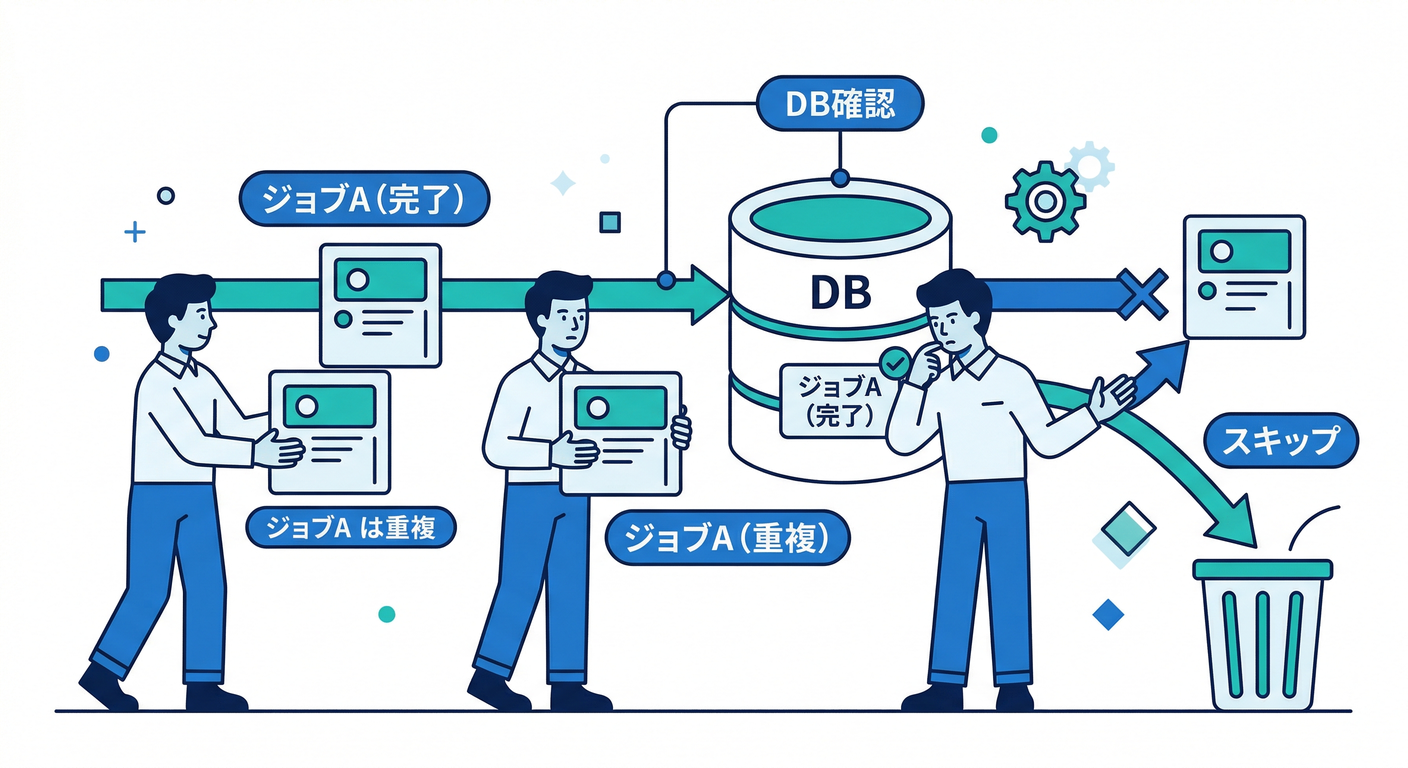
現実のキュー運用は、だいたい 「同じジョブが2回実行されてもおかしくない」 方向に寄ります(ネットワーク、再試行、Worker落ちなど)💥
なので、初心者ほどここだけ覚えておくと強いです💪
✅ 対策の基本は「冪等(べきとう)」🧼
同じジョブが2回走っても 結果が壊れない ようにする考え方です。
例:メール送信
- ❌ 2回送られると困る
- ✅ 「送信済みフラグ」をDBに持って、2回目はスキップ など
このあたりは後の章で「実装の型」に落とし込みます🧱✨
9) この教材で採用する“キュー役者”の雰囲気(予告)🎬
次章からは、Redis 上にジョブキューを作れるライブラリの代表として BullMQ を例に進めます🐂💨 BullMQ は「Redis の上に作る Node.js 向けキュー」だと公式が明言しています。(docs.bullmq.io)
また、Redis 側には Streams という「追記型ログ」っぽいデータ構造もあって、メッセージング的な用途で使われます。(Redis) (※教材では難しい話は必要になるまで出しません🙆♂️)
10) ミニ演習(紙と頭でOK)📝🧠
あなたの作りたいアプリを想像して、次を分類してみてください👇✨
「今すぐ返したい」処理⚡
- 例:ログイン結果を返す、一覧を返す、バリデーション結果を返す
「あとで良い」処理📦⏰
- 例:メール送信、サムネ生成、通知、集計、外部API連携、重い変換
👉 “あとで良い” に入ったものが、第17章のキュー導入で一気に気持ちよくなります😆🎉
11) まとめ(覚えるのはこれだけでOK)✅✨
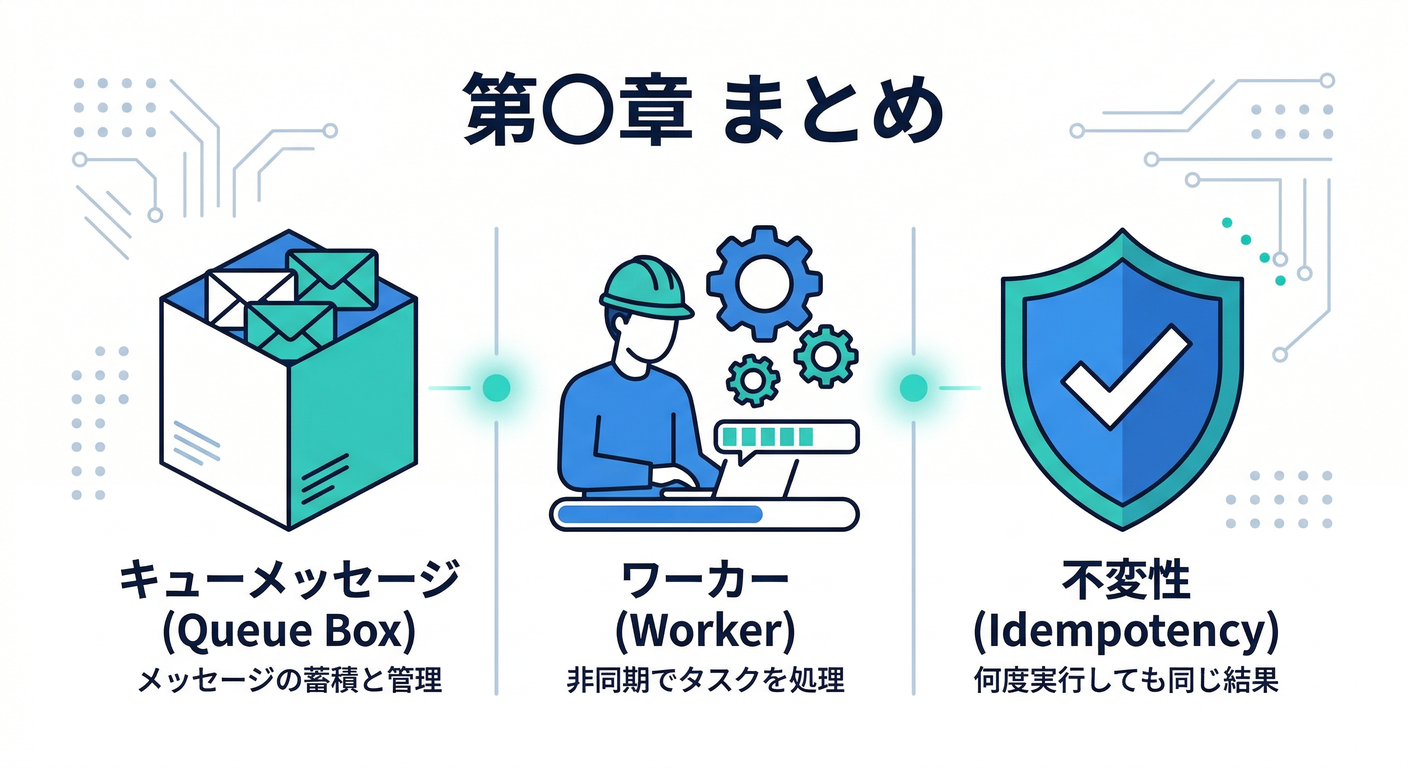
- キューは 「あとでやる箱」 📦⏰
- 効く場面は 「重い・待たせたくない・混む・失敗しやすい」 🧯
- 構図は 「APIが投げる / Workerが処理する」 📨➡️👷♂️
- 実運用は 重複がありうる ので、設計で受け止める🧼
次章へのつなぎ🚀
次の第17章では、Redis ベースのキューを Compose に追加して、 API からジョブを投げて、Worker が受け取って処理するところまで作ります🟥📦👷♂️✨
(ちなみに Node.js は v24 が Active LTS で、教材的にも安心して基準にできます🙂)(nodejs.org)