第01章:データって何?まず「守る/捨てる」を仕分けよう🧹🗂️
この章のゴールはシンプルです👇 「このプロジェクトのデータは、どれが消えたら困る?どれが消しても復活できる?」を言語化して、迷いを消します✨ (この仕分けができると、次章以降の volume / bind / tmpfs が一気にラクになります👍)
まず結論:データは2種類しかない🧠✨
- 守るべきデータ(State)
- 消えたら困る / すぐ復元できない / 事業・動作に影響が大きい
- 例:DBの中身、ユーザーがアップした画像、決済・注文の記録、手で作った設定ファイル など
- 捨てていいデータ(Derived / Disposable)
- 消しても作り直せる(再生成できる)
- 例:ビルド成果物、キャッシュ、インストールし直せる依存物、再取得できるログ など
そして超重要ポイント👇 コンテナは「作って壊す」前提の道具なので、コンテナの中にしか無いデータは、基本いつか消えます。永続化したいなら “外に逃がす” 仕組みが必要です(volume など)📦 Docker公式でも、volume はコンテナのライフサイクルを超えてデータを保持する仕組みとして説明されています。(Docker Documentation)
この章で作る成果物:データ分類メモ📝✅
「設定・ソース・DB・キャッシュ・ログ」をぜんぶ棚卸しして、各データにラベルを貼ります🏷️
- ✅ 守る(永続化・バックアップ対象)
- 🧨 捨てる(消してOK・再生成)
- ⚠️ 要注意(守るけど“扱い注意”):秘密情報、個人情報、巨大ログ…など
5カテゴリで仕分けする(まずはこれだけ!)🗂️✨
ここからは、あなたのPJに当てはめていきます💪😄 (TypeScriptのWeb/API開発を想定した“ありがち例”つき)
1) 設定(Config)⚙️
-
例:
compose.yaml/Dockerfile/tsconfig.json/.env(※値は秘密!)/ アプリ設定ファイル -
判断:
- ✅ 守る:設定ファイルそのもの(Git管理できるなら最高🎉)
- ⚠️ 要注意:
.envの中身(秘密はバックアップやAI貼り付けで事故りやすい🔒💥)
2) ソース(Source)🧑💻
-
例:
src//prisma//migrations//README.md -
判断:
- ✅ 守る:基本ぜんぶ(Gitが正義👑)
- 🧨 捨てる:
dist/(ビルドで再生成できるなら)など
3) DB(Database)🐘🗄️
-
例:Postgres/MySQLのデータ、SQLiteファイル、アップロードファイルのメタデータ
-
判断:
- ✅ 守る:基本ぜんぶ(ここ消えると泣きます😭)
- 補足:Dockerでは「永続化したいなら volume を使う」がド定番です📦(Docker Documentation)
4) キャッシュ(Cache)⚡
-
例:Redis、ビルドキャッシュ、一時ファイル
-
判断:
- 🧨 捨てる:基本これ(消しても困らないのがキャッシュの存在意義😎)
- ⚠️ 例外:キャッシュなのに“再生成が高コスト”なら、扱いを検討(でも最初は捨ててOK寄り👍)
5) ログ(Logs)🪵
-
例:アプリログ、アクセスログ、エラーログ
-
判断:
- 開発中:🧨 捨てるでもOK(必要なら閲覧できれば十分)
- 本番:✅ 守ることが多い(障害調査の命綱🧯)
-
ただしログは肥大化しがちなので「保存期間」を決めるのが大事📅(これは後半章でやります👍)
仕分けの“判断基準”3つだけ覚える🧠✅
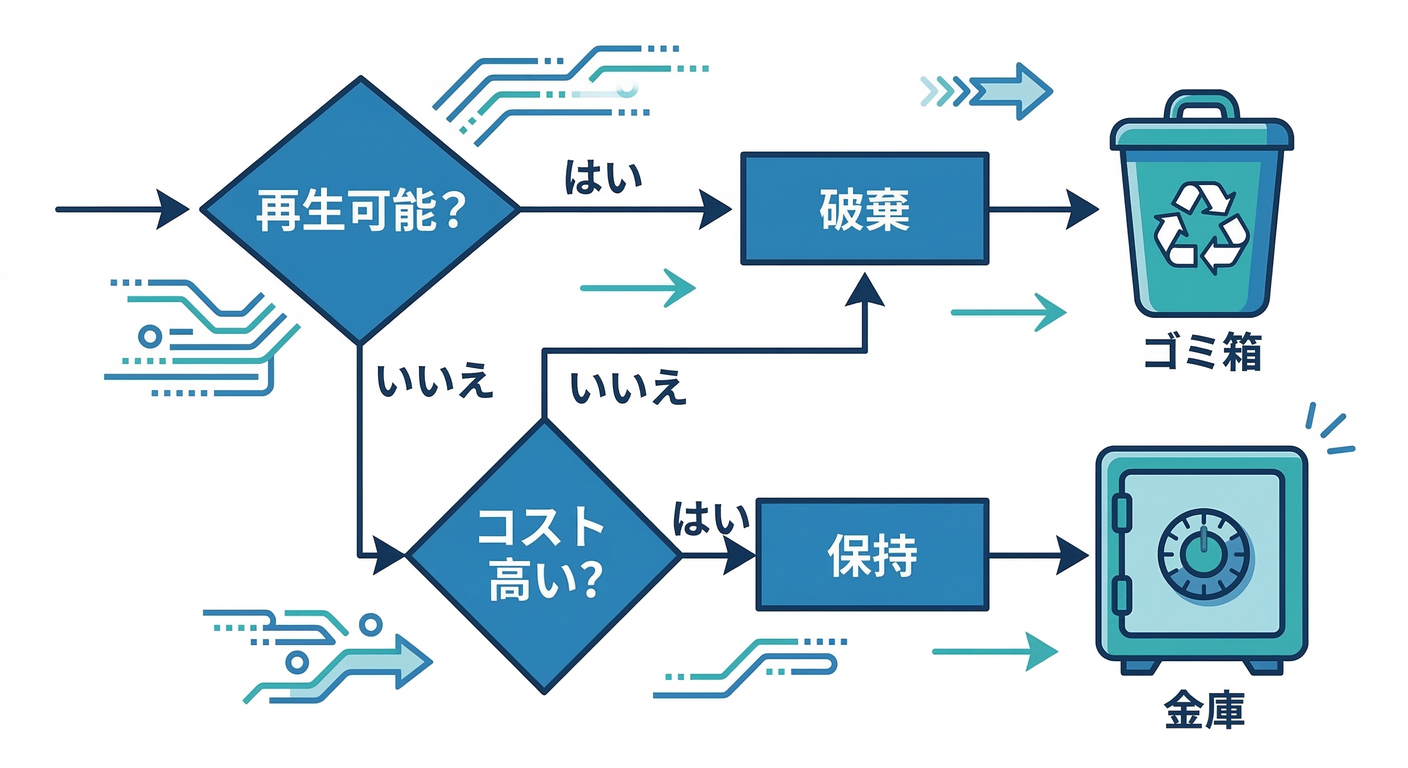
データに迷ったら、この順で考えます👇
-
再生成できる?(コマンド一発 / 手順がある)🔁 → YESなら捨ててOK寄り🧨
-
再生成にかかるコストは?(時間・お金・信用)💸 → 高いなら守る寄り✅
-
秘密や個人情報が混ざる? 🔒 → 混ざるなら要注意⚠️(バックアップやAI投入は“脱色”してから!)
ミニ実験:「コンテナの中だけのデータ」は消える🫠(超短い体験)
“なぜ仕分けが必要か”を体で理解します💪 (コマンドはコピペでOK!)
docker run --rm -it alpine sh
コンテナの中でファイル作る👇
echo "hello" > /tmp/only-in-container.txt
ls -l /tmp
exit
これでコンテナは終了&削除(--rm)されるので、次もう一回起動してもそのファイルはありません😇
「守るべきデータをコンテナに閉じ込めない」が超大事、という感覚を掴めればOKです👍
永続化は次章で volume を触ります(volume はコンテナを消してもデータが残る仕組み)。(Docker Documentation)
実作業:あなたのPJを棚卸しする手順🧹📝
Step 1) “データ一覧”を出す(5分)⏱️
VS Codeでプロジェクトを開いて、ルート直下から眺めます👀✨ 次の「ありがち項目」を見つけたらメモへ追加👇
compose.yaml/Dockerfilesrc/tests/.env(値は書かない!ファイル名だけ📛)db/data/storage/uploads/logs/tmp/node_modules/(※たいてい捨ててOK)
Step 2) “守る/捨てる/要注意”を付ける(10分)🏷️
まずは雑でOKです🙆♂️(あとで直せるので!)
Step 3) “理由”を1行で書く(最重要)✍️🔥
例:
- ✅ DB:ユーザーの状態が入ってて再生成できない
- 🧨 キャッシュ:消しても再計算で復活
- ⚠️
.env:秘密が入るので扱い注意
データ分類メモのテンプレ(これをコピペでOK)📌
VS Codeで docs/data-classification.md を作って、これを貼って埋めてください👇
## データ分類メモ
## 1) 設定(Config)⚙️
- [ ] 対象:
- 例: compose.yaml / Dockerfile / tsconfig.json / .env(値は書かない)
- 守る/捨てる/要注意:
- 理由(1行):
- 再現方法(あれば):
## 2) ソース(Source)🧑💻
- [ ] 対象:
- 守る/捨てる/要注意:
- 理由(1行):
- 再現方法:
## 3) DB(Database)🐘
- [ ] 対象:
- 例: postgres のデータ / sqlite ファイル / uploads の実体
- 守る/捨てる/要注意:
- 理由(1行):
- バックアップ方針(今は仮でOK):
## 4) キャッシュ(Cache)⚡
- [ ] 対象:
- 守る/捨てる/要注意:
- 理由(1行):
- 消し方(今は空でOK):
## 5) ログ(Logs)🪵
- [ ] 対象:
- 守る/捨てる/要注意:
- 理由(1行):
- 保存期間(仮でOK):
AI活用(安全に!)🤖🛡️:仕分けの“根拠”を補強する
AIは「判断の理由づけ」めっちゃ得意です✨ ただし、秘密の値や個人情報は貼らないでくださいね🔒🙏
使えるプロンプト例(コピペOK)📋
以下はプロジェクトのデータ候補一覧です。
各項目を「守る / 捨てる / 要注意」に分類し、理由を1行で付けてください。
また、判断が割れそうな項目は「迷う理由」と「決め方」も書いてください。
【データ候補】
- compose.yaml
- Dockerfile
- src/
- migrations/
- .env(値は共有しない)
- postgres のデータ(volume想定)
- uploads/(ユーザー画像など)
- logs/
- node_modules/
- dist/
- tmp/
AI回答をチェックするコツ✅
- 「捨てる」に分類されたものが、本当に再生成できる?(手順ある?)
- 「守る」に分類されたものが、バックアップ対象として妥当?(巨大すぎない?秘密混ざらない?)
.envや鍵系が出たら、要注意に寄せるのが安全🔒
仕上げチェック(この章の合格ライン)🎉✅
次の3つが言えたらOKです👇
- ✅ このPJで「守るべきデータ」は何か(最低3つ)
- ✅ それぞれ「なぜ守るのか」を1行で言える
- ✅ 「捨てていいデータ」を怖がらず消せる理由が説明できる
ちょい豆知識(この先の章への伏線)📦💡
- volume:Dockerが管理する永続領域。コンテナを消しても残る📦(Docker Documentation)
- bind mount:ホストのフォルダをそのままコンテナへ共有(開発でソースを載せるのに便利)📁(Docker Documentation)
- tmpfs:メモリ上に置く一時領域で、停止すると消える(“絶対ディスクに残したくない一時データ”に向く)💨(Docker Documentation)
- WindowsでDocker Desktop+WSL2の場合、LinuxコンテナはWSL2側で動くのが基本、という前提も押さえると後が楽です🐧🪟(Docker Documentation)
次(第2章)では、この第1章で「守る」と決めたデータを、bind / volume / tmpfs のどれに置くかを直感で選べるようにしていきます👪✨