第27章:観測性の入口(イベント・ログ・メトリクス)🔍📊✨
この章は「落ちた!動かない!」ってなった時に、最短で原因へ近づくための“観測3点セット”を身につけます💪😺 (ここでいう観測=Events / Logs / Metrics の3つだよ〜)
0) 今日のゴール🎯🌈
- **Events(イベント)**で「何が起きたか」を読む👀
- **Logs(ログ)**で「中で何が起きたか」を読む🗣️🔥
- **Metrics(メトリクス)**で「どれくらい苦しいか」を見る📈😵💫
- そして最後に、**“切り分けの型”**を手に入れる🧠✨
1) まずは超ざっくり理解🧠💡(3点セットの役割)
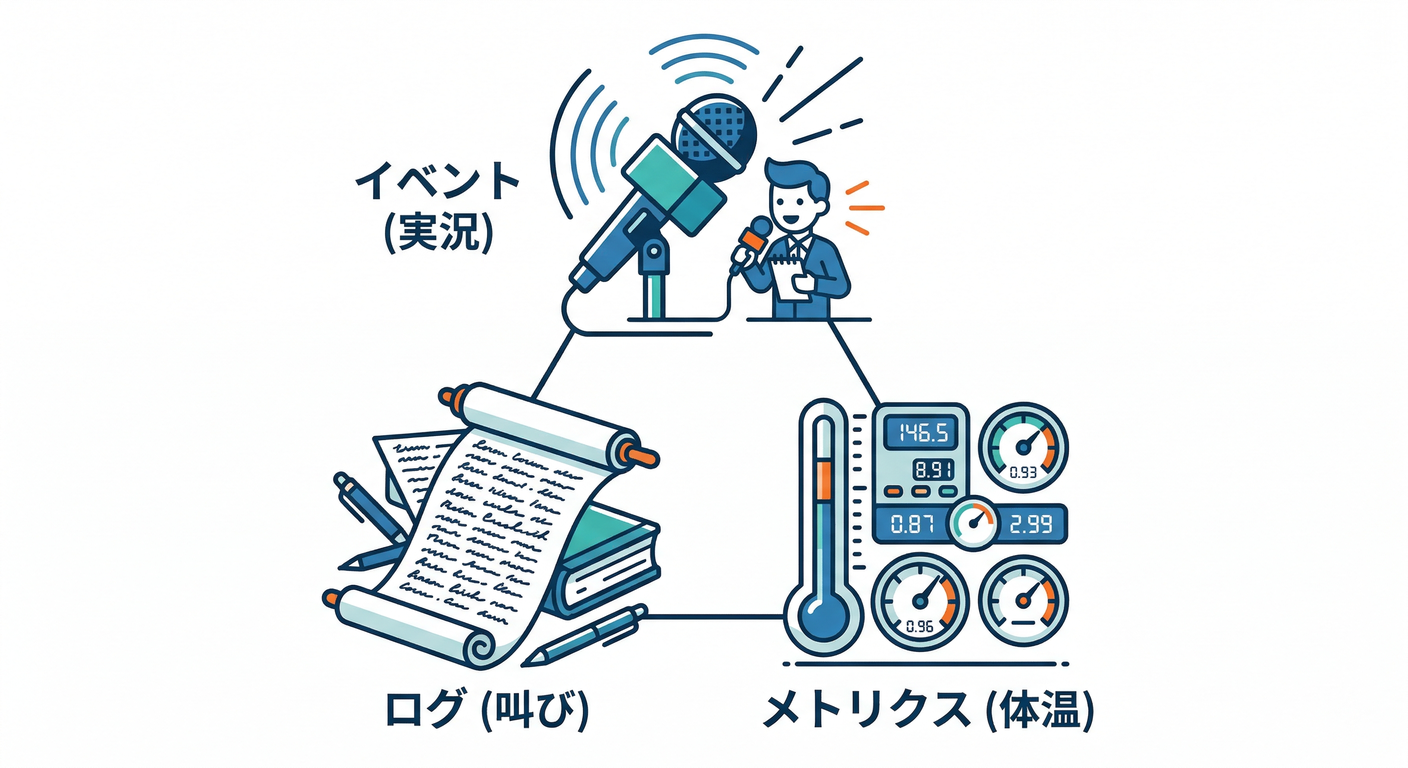
✅ Events(イベント)=「外側の実況」🎙️
- スケジューラやkubeletが「Pullできない」「置けない」みたいな“出来事”を残すよ📝
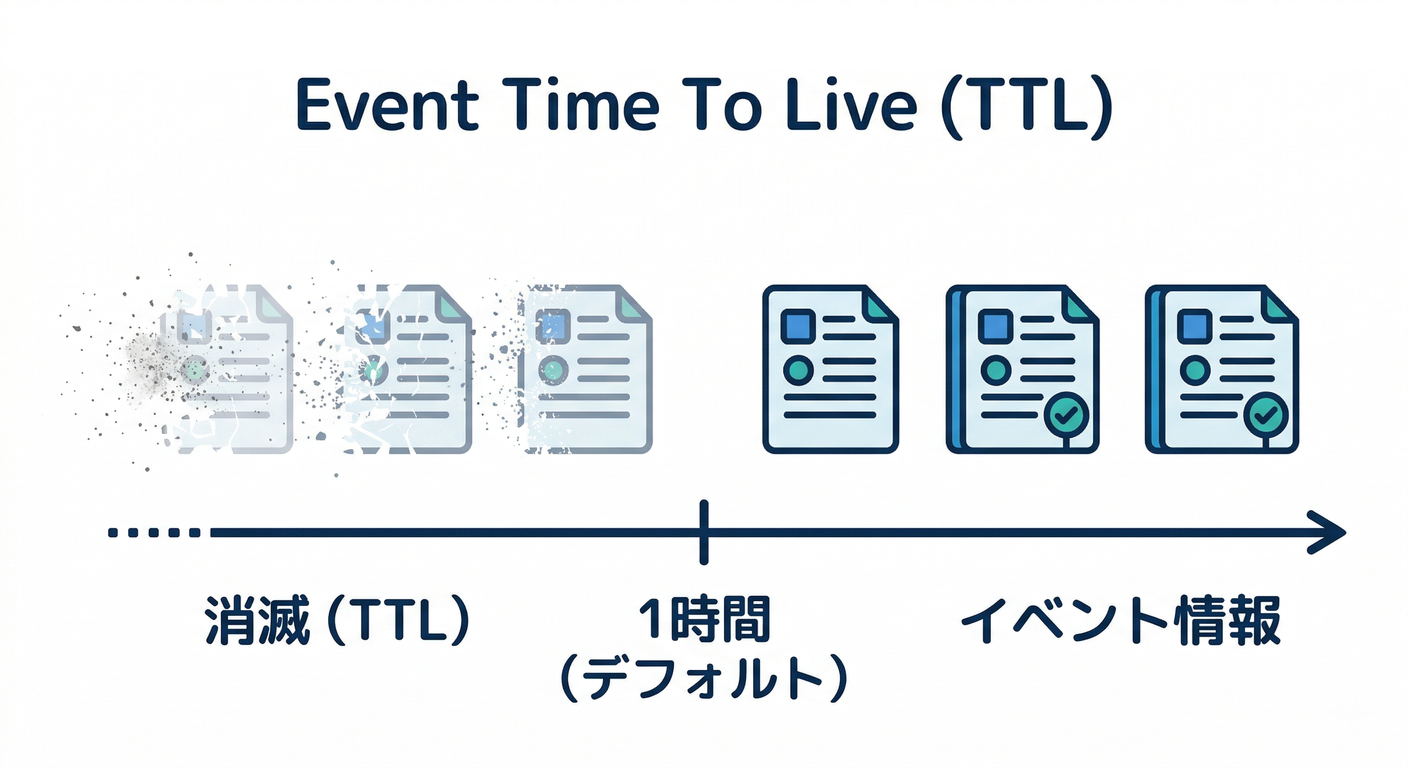
- ただし 長期保存じゃないのが重要ポイント!
KubernetesのAPIサーバには
--event-ttlがあり、デフォルトが 1時間 になってる(=イベントは消える前提)⏳💨 (Kubernetes)
✅ Logs(ログ)=「アプリの叫び」📣
- Kubernetesはログを勝手に保存してくれる仕組みではない(基本はコンテナの標準出力/標準エラーに出すだけ)📺
- クラスタ全体で貯めるなら、別のログ基盤が必要になる(=外部の仕組みで集める)🪣 (Kubernetes)
- でも安心して!学習段階は kubectl logs でかなり戦える🔥
✅ Metrics(メトリクス)=「体温計」🌡️
- CPU/メモリなどの“使用量”を見て、リソース不足系の事故を見抜く👀
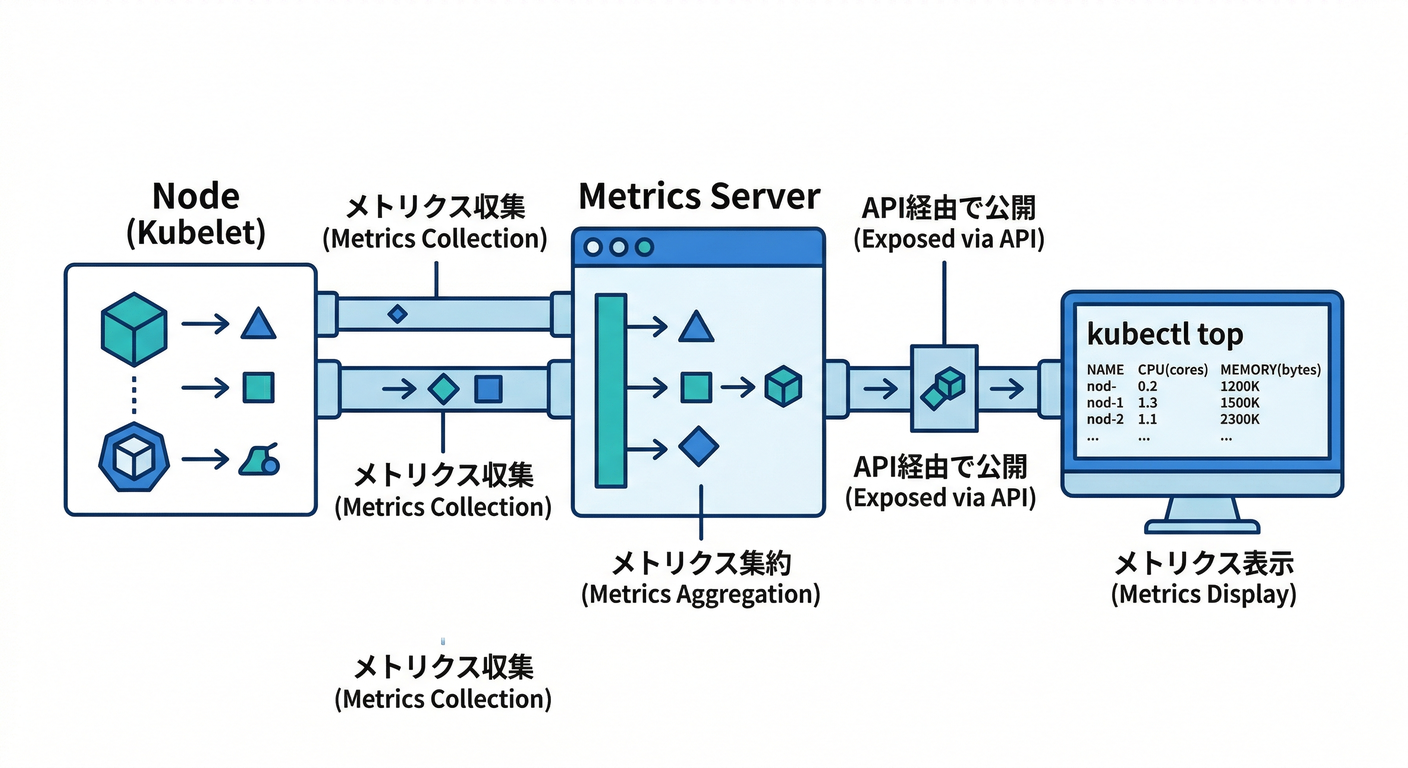
- ここでの基本は Metrics API と metrics-server 🧩
metrics-serverは kubelet から集めたリソース使用量を Metrics API として提供して、
kubectl topから見られるようにするよ📊 (kubernetes-sigs.github.io)
2) 困ったらこの順番!「切り分けの型」🧭🧯
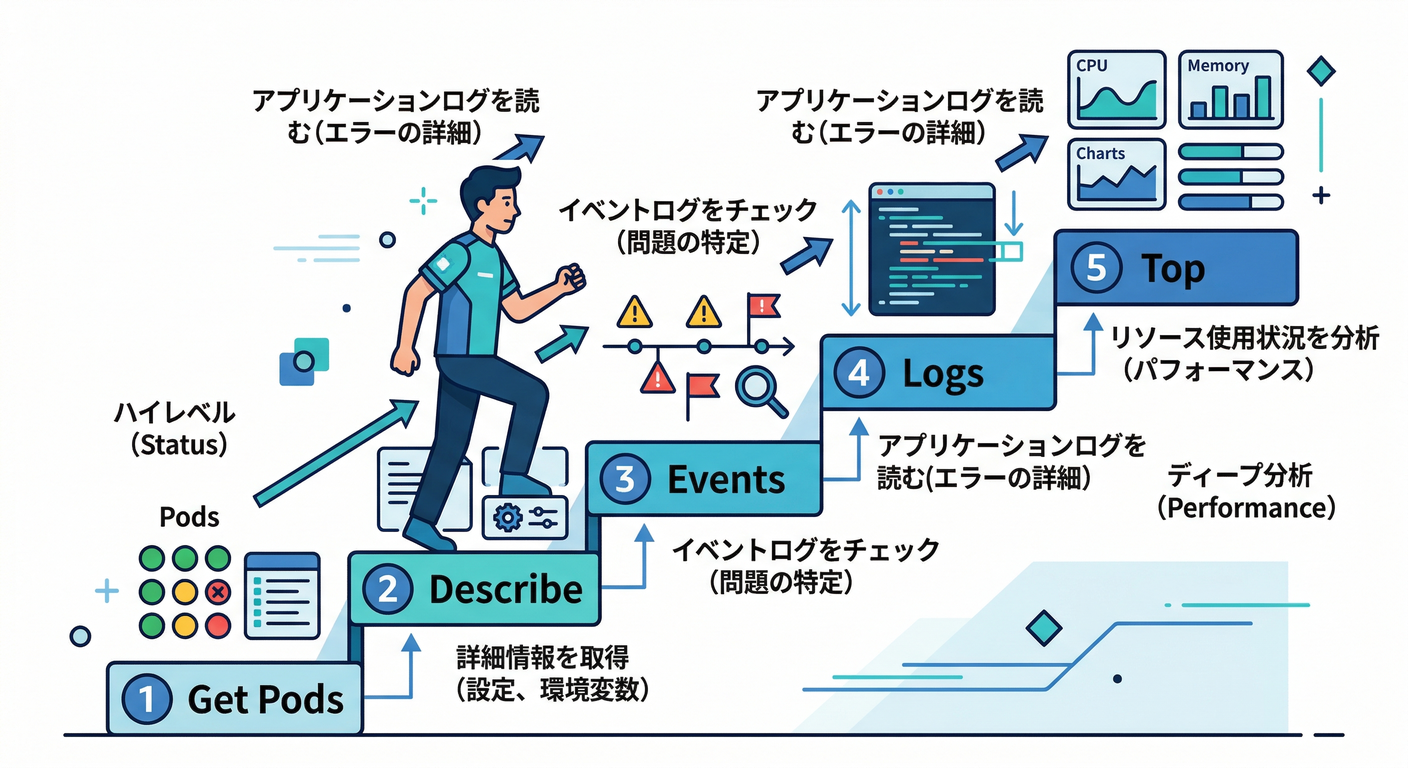
まずはこの“型”を丸暗記でOK!😺👍
kubectl get podsで状態を見る👀kubectl describe pod ...で 状態と最近のイベントを見る📝 (Kubernetes)kubectl events(またはkubectl get events)でイベントを追いかける🏃♂️💨 (Kubernetes)kubectl logsで中身を見る📣(落ちた直後は--previousが超重要)🧨 (Kubernetes)kubectl topで苦しさを見る📈(メトリクスが取れる環境なら) (Kubernetes)
3) Events編:イベントを“狙って見る”🕵️♂️🔎
イベントを見るコマンド(よく使うやつ)🧰✨
kubectl describe pod <pod>(まずこれ!)📝 (Kubernetes)kubectl events -n <ns>(イベント専用に見やすい)👀 (Kubernetes)- 1つの対象に絞るなら
--forが便利🎯 (Kubernetes)
4) Logs編:kubectl logsの“使える技”🔥📜
「まず見る」ログの取り方🧪
- フォロー(流し見)したい →
-f🏄♀️ - 直近だけ見たい →
--tail✂️ - 直近N分だけ見たい →
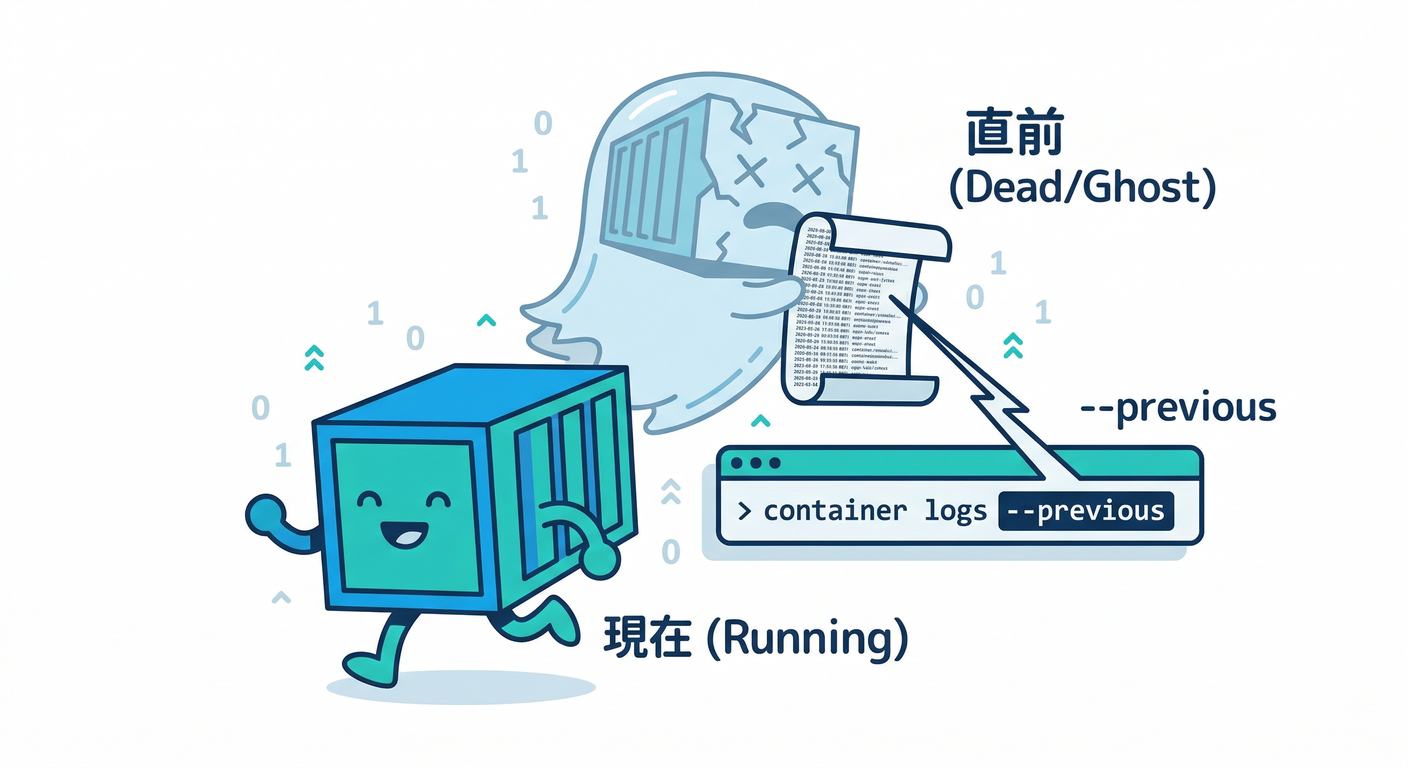
--since⏱️ - 落ちて再起動してる時 →
--previous(これ最強)💪
kubectl logs の代表オプション(--previous, --since, --all-containers など)は公式リファレンスにまとまってるよ🧭 (Kubernetes)
また、--previous で「直前のコンテナ実行のログ」を取れる前提も公式に説明があるよ📌 (Kubernetes)
5) Metrics編:kubectl topで“リソース不足”を疑う📈😵
まず大事な前提👀
kubectl top は Metrics Server が必要だよ(入ってないと取れない)🚧 (Kubernetes)
metrics-server を入れる(学習用の定番)🧩
手早く入れるならこの方式がよく使われるよ👇(公式系の手順として広く案内されてる) (AWS Documentation)
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
kubectl -n kube-system rollout status deploy/metrics-server
入ったら確認👇
kubectl top nodes
kubectl top pods -A
metrics-server が何をしてるか(kubelet→Metrics API→kubectl top)も、公式で説明されてるよ🧠✨ (kubernetes-sigs.github.io)
6) ハンズオン道場🥋😈➡️😇(Events/Logs/Metricsを全部触る)
ここからは「わざと壊して」「観測で倒す」やつ😺🔥 (安全に戻せるので安心してね)
ハンズオンA:ImagePullBackOffをEventsで倒す🧨📦
1) わざと存在しないイメージでPodを作る😈
apiVersion: v1
kind: Pod
metadata:
name: bad-image
spec:
containers:
- name: app
image: nginx:never-exists-2026-02-14
kubectl apply -f bad-image.yaml
kubectl get pod bad-image
2) イベントを追う🏃♂️💨
kubectl describe pod bad-image
“最近のイベントも見てね”が公式のデバッグ手順としてもまず推奨されてるよ📝 (Kubernetes)
イベント専用に見るなら👇
kubectl events --for pod/bad-image --watch
kubectl events は公式リファレンスがあるので、使い方はそこを基準にすると迷いにくいよ📌 (Kubernetes)
3) 片付け🧹
kubectl delete pod bad-image
ハンズオンB:CrashLoopBackOffをLogsで倒す💥📣
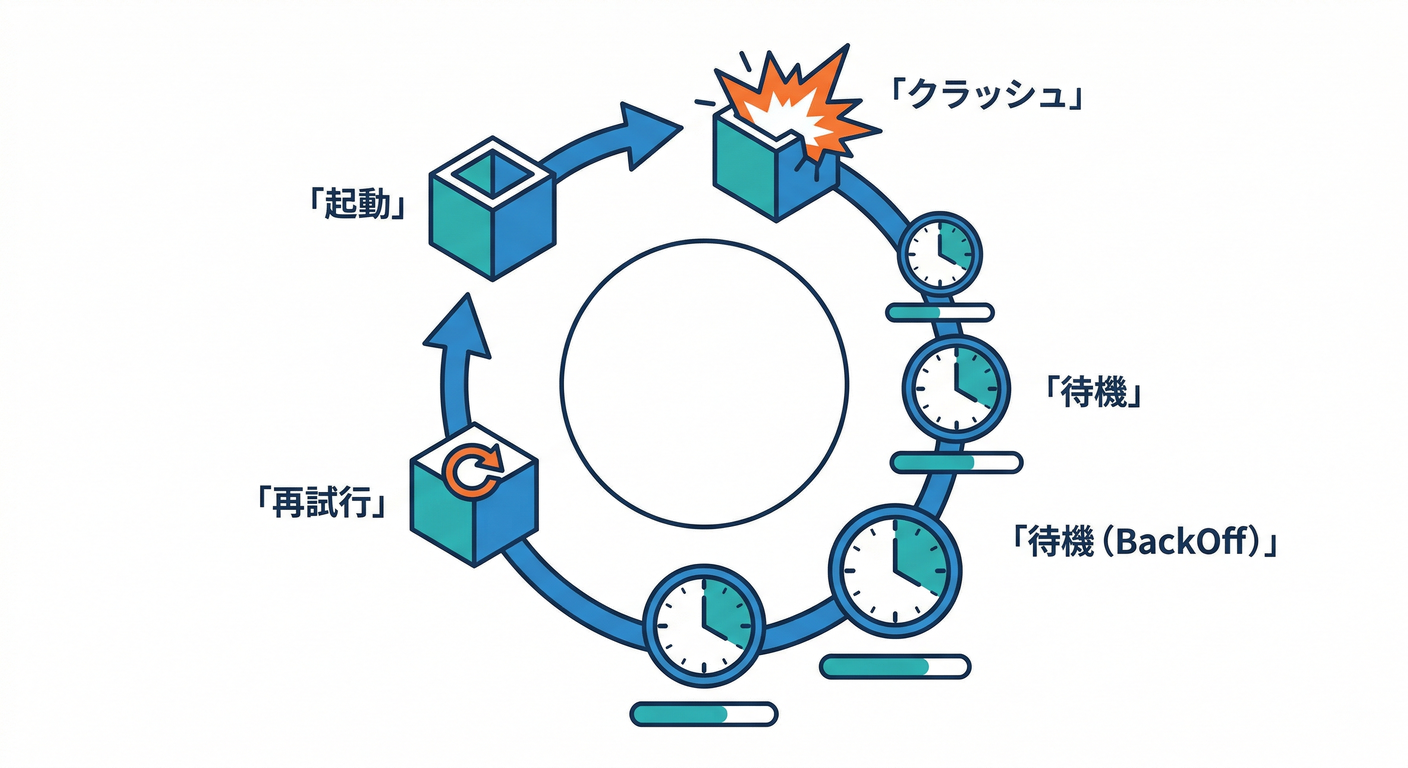
1) すぐ落ちるPodを作る😈
apiVersion: v1
kind: Pod
metadata:
name: crash-me
spec:
restartPolicy: Always
containers:
- name: app
image: busybox:1.36
command: ["sh", "-c", "echo hello; sleep 1; exit 1"]
kubectl apply -f crash-me.yaml
kubectl get pod crash-me -w
2) ログを見る(ここが本番)🔥
kubectl logs crash-me
そして超重要👇(再起動してるときの“直前ログ”)
kubectl logs crash-me --previous
--previous は「前のコンテナ実行のログを見る」ための公式オプションとして説明されてるよ🧯 (Kubernetes)
3) 片付け🧹
kubectl delete pod crash-me
ハンズオンC:メトリクスで“リソース圧迫”を感じる📈😵💫
1) まず kubectl top が動くか確認✅
kubectl top pods -A
動かなければ「metrics-server 未導入」を疑う(kubectl top は Metrics Server 必須)🚧 (Kubernetes)
導入は前の手順へ戻ってね🧩 (AWS Documentation)
2) CPUを食うPodを作る🔥
apiVersion: v1
kind: Pod
metadata:
name: cpu-burn
spec:
containers:
- name: app
image: busybox:1.36
command: ["sh", "-c", "yes > /dev/null"]
resources:
requests:
cpu: "50m"
memory: "32Mi"
limits:
cpu: "100m"
memory: "64Mi"
kubectl apply -f cpu-burn.yaml
kubectl top pod cpu-burn
kubectl describe pod cpu-burn
メトリクスは「CPU/メモリの使用量」をMetrics APIで取る仕組みで、metrics-serverがそれを提供するよ📊 (Kubernetes)
3) 片付け🧹
kubectl delete pod cpu-burn
7) “設計”の超入門としての観測性📐✨(ここだけ覚えればOK)
観測性って、実は「設計」でもあるんだよね🧠 難しく考えず、最初はこれだけ決めればOK👇
- ログに 「いつ」「何が」「どれくらい」 を残す(最低3点)🕒🧾📏
- エラーは 握りつぶさず “エラーだと分かる形”で出す🚨
- 秘密情報(トークン/パスワード)はログに出さない🔐🙅♂️
- “あとで探しやすい”ように、メッセージを統一する(例:
action=login result=fail reason=...)🧹✨
8) AI活用コーナー🤖✨(ログ/イベント解析が爆速になる)
そのままコピペで使えるお願い文🪄
- 「この
kubectl describeの Events を日本語で要約して、次に打つべきコマンドを3つ出して」🧠🔎 - 「この
kubectl logsのエラー原因候補を3つ、切り分け手順つきで」🧯🧭 - 「
kubectl topの値を見て、CPU/メモリどっちが詰まりそうか判定して」📈⚖️
⚠️ ただしSecretsやトークンは貼らないでね🔐🙈(ここだけはガチで大事)
9) まとめ:この章のチートシート🧾✨
困ったらこの順でOK😺🧯
kubectl get pods -A(どれが死んでる?)👀kubectl describe pod <pod>(状態+最近のイベント)📝 (Kubernetes)kubectl events --for pod/<pod>(イベント実況)🎙️ (Kubernetes)kubectl logs <pod> --previous(CrashLoopならまずこれ)🔥 (Kubernetes)kubectl top pod/node(苦しさチェック。Metrics Server必須)📈 (Kubernetes)
次の第28章は、この章で触ったやつを“型として完全に体に入れる” トラブルシュート道場だよ🥋🔥 (CrashLoop / Pending / NotReady を「見た瞬間に手が動く」状態にするやつ💪😺)