第15章:Requests/Limits(CPU/メモリ)入門📏🍰☸️
この章は「みんなで1つのクラスタを使う」世界の必修科目! Requests/Limits がないと、**席取りゲーム(リソース奪い合い)**が始まって、誰かのアプリが突然死します😇💥
まず超ざっくり理解しよう🧠✨
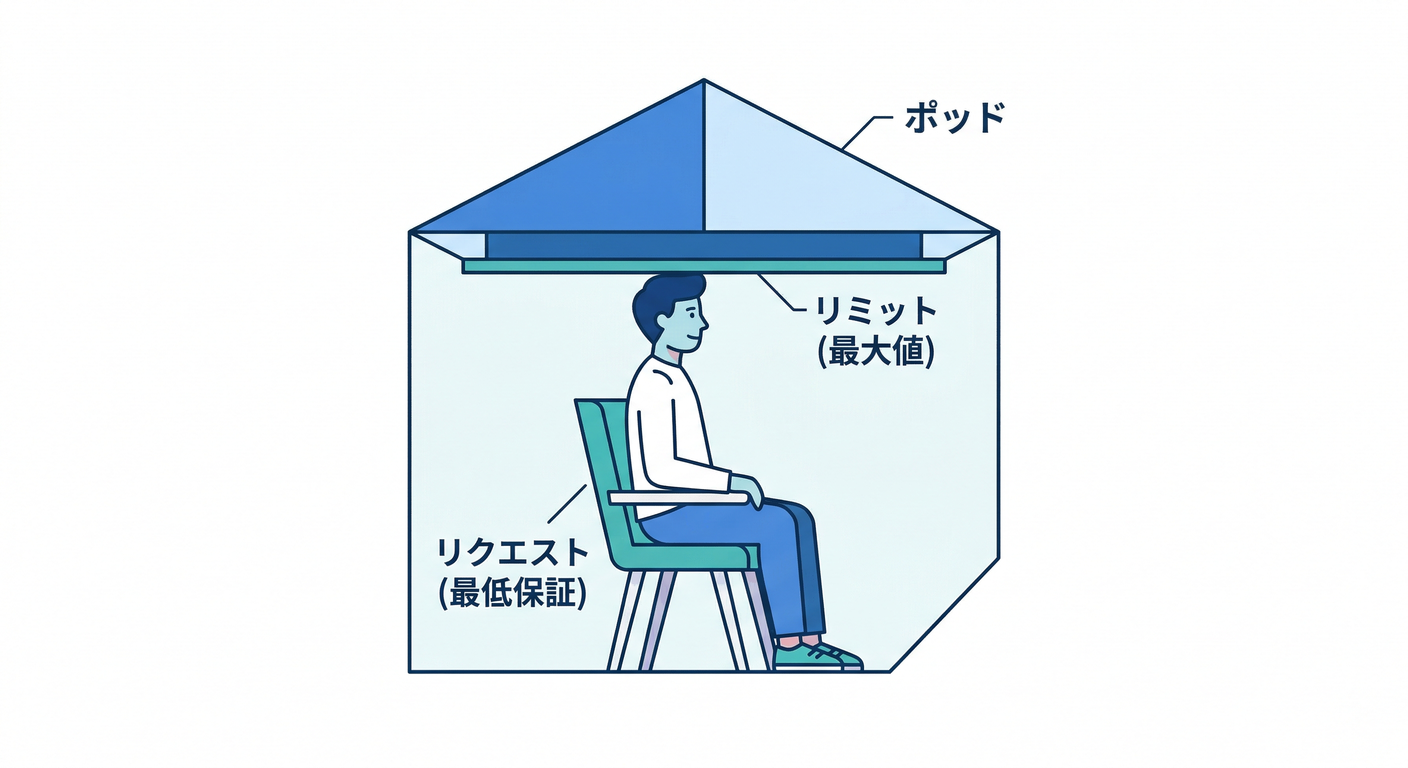
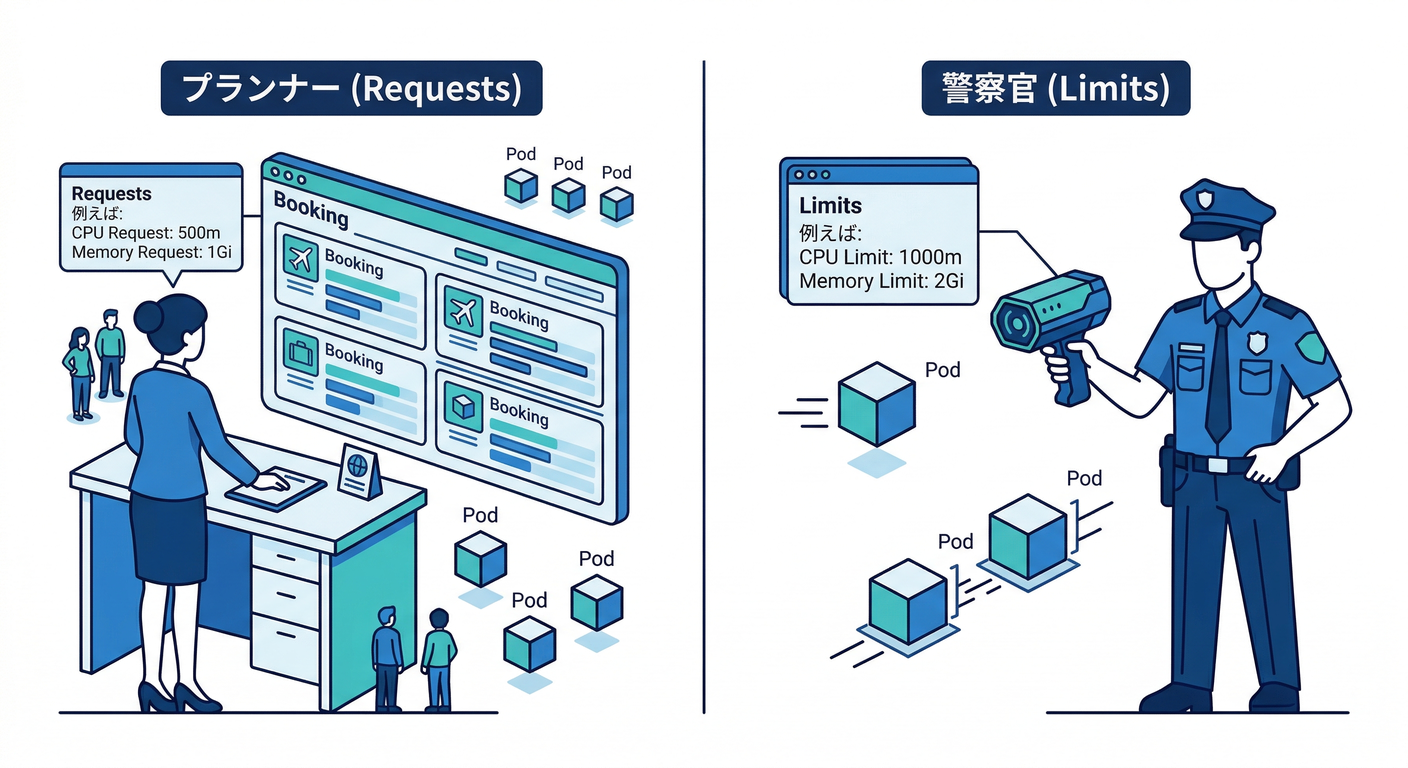
- requests(要求)=「最低これだけ使わせてね」🪑(席の予約)
- limits(上限)=「これ以上は使いすぎ禁止ね」🚧(天井)
Kubernetesはこの情報をこう使います👇
- スケジューラは requests を見て「置き場所(どのノードに載せるか)」を決める
- kubeletは limits を見て「使いすぎたら止める」を実行する …という役割分担です。(Kubernetes)
CPU とメモリは“止まり方”が違う⚠️(ここ超重要)
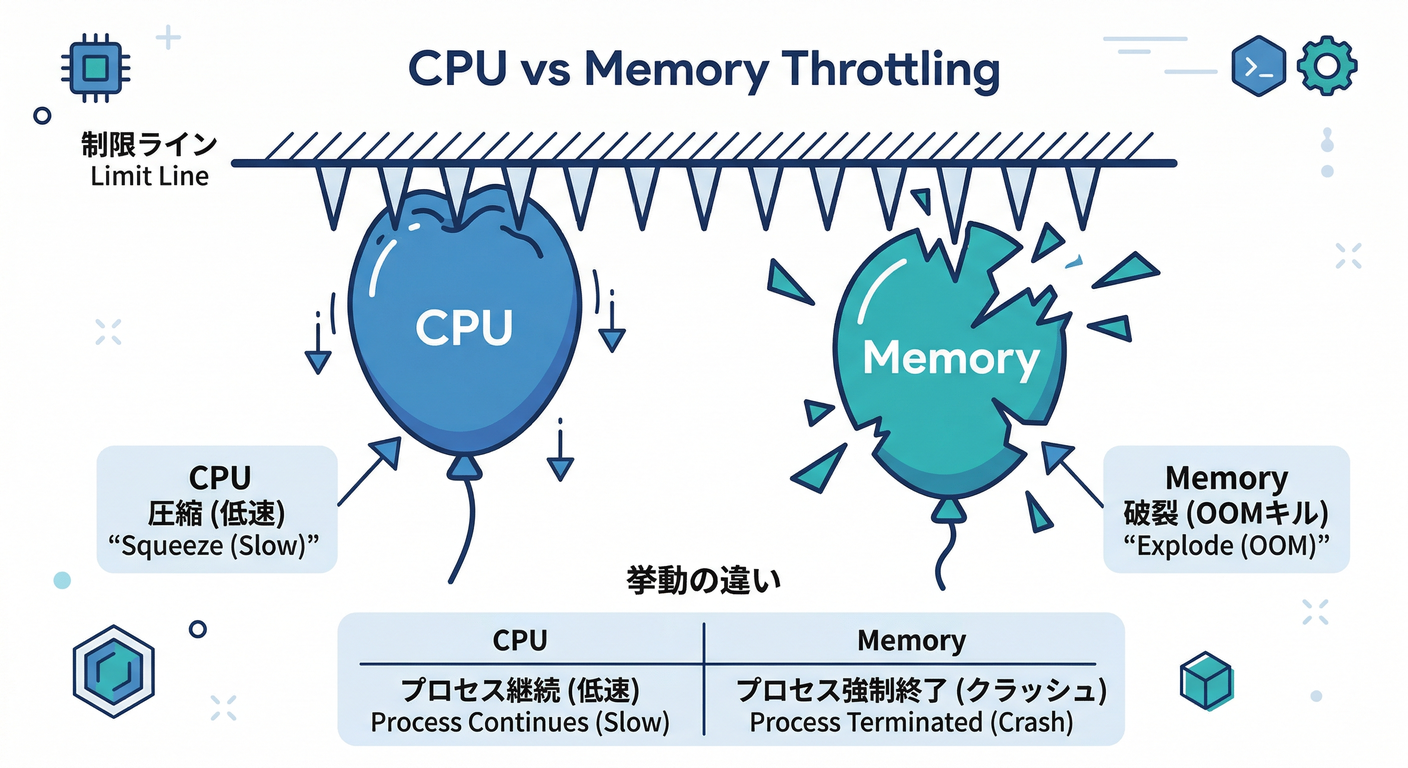
CPU limit:遅くなる(スロットリング)🐢
CPU の limit は 上限を超えないように絞られるので、アプリは生きてるけど レスポンスが急に遅くなることがあります。(Kubernetes)
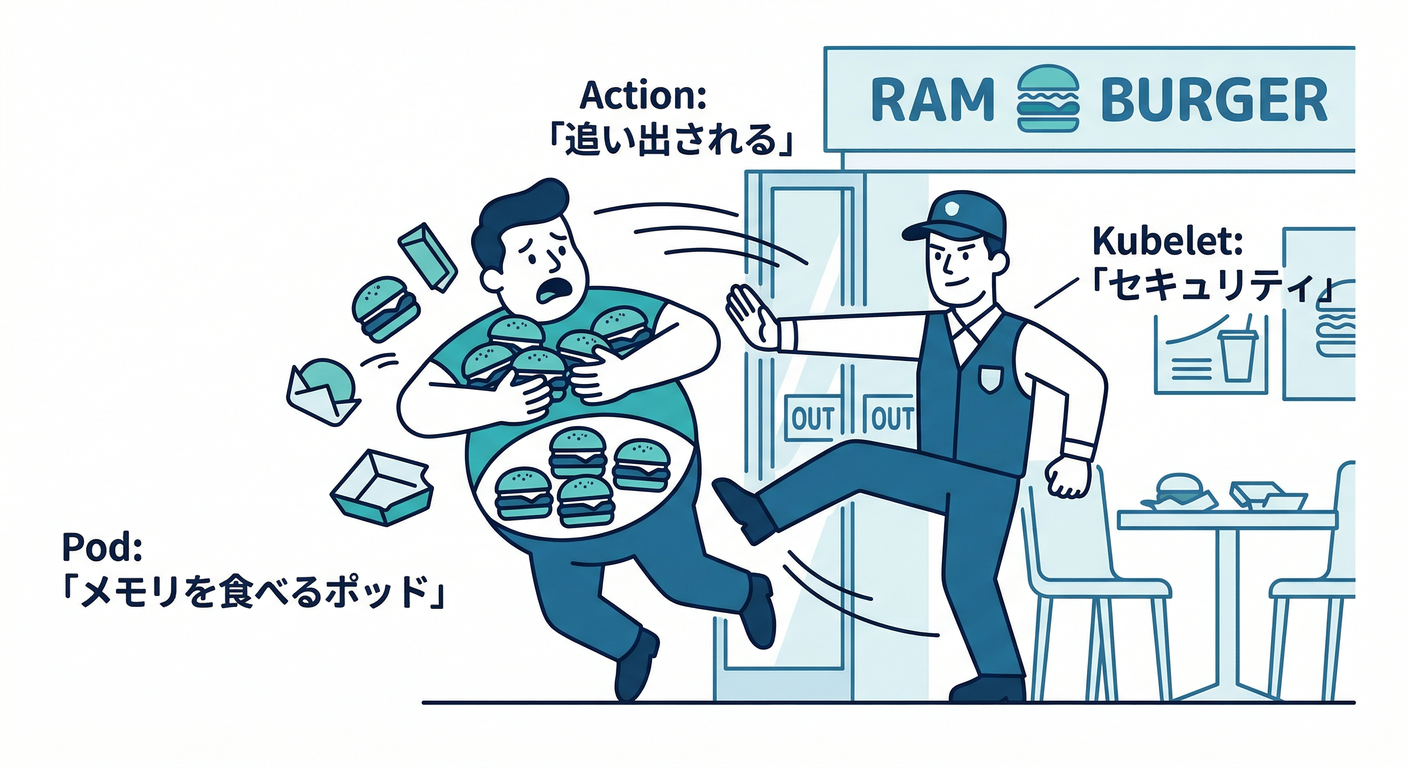
メモリ limit:落ちる(OOMKill)💀
メモリの limit は **超えたら落とされる(OOM kill)**寄り。 しかも「超えた瞬間100%即死」ではなく、メモリ圧がかかったタイミングで落とされるので、挙動がちょっと分かりにくいです。(Kubernetes)
“3つの事故パターン”を先に覚える🥋💥
-
request が高すぎて Pending 🧊 → 置き場所がなくて起動できない(スケジューリング失敗)
-
CPU limit が低すぎて激遅 🐢 → 落ちないけど遅い、ログも静かで気づきにくい
-
メモリ limit が低すぎて OOMKilled 💀 → 再起動ループ(CrashLoopBackOff)に突入しがち
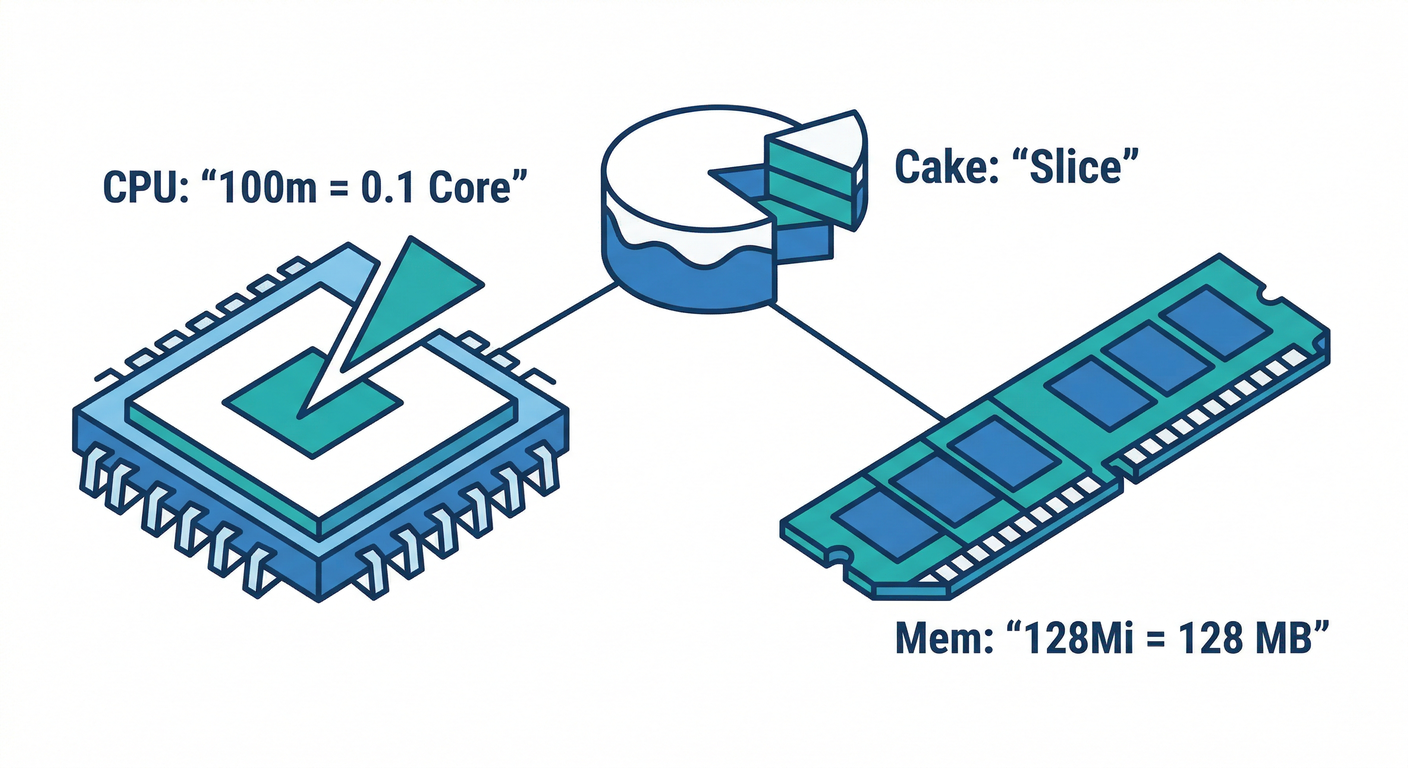
単位チートシート📌(これだけ覚えればOK)
-
CPU
100m= 0.1 core(ミリコア)⚙️500m= 0.5 core
-
メモリ
128Mi(メビバイト)🧠1Gi(ギビバイト)
※ もし limit だけ書いて request を書かないと、Kubernetes が「request = limit」とみなす動きになります(自動コピー)。(Kubernetes) (初心者ほど「limitだけ書いたつもりが、スケジューリングが重くなる」事故が起きます😇)
QoS(優先度クラス)もセットで理解しよう🎚️
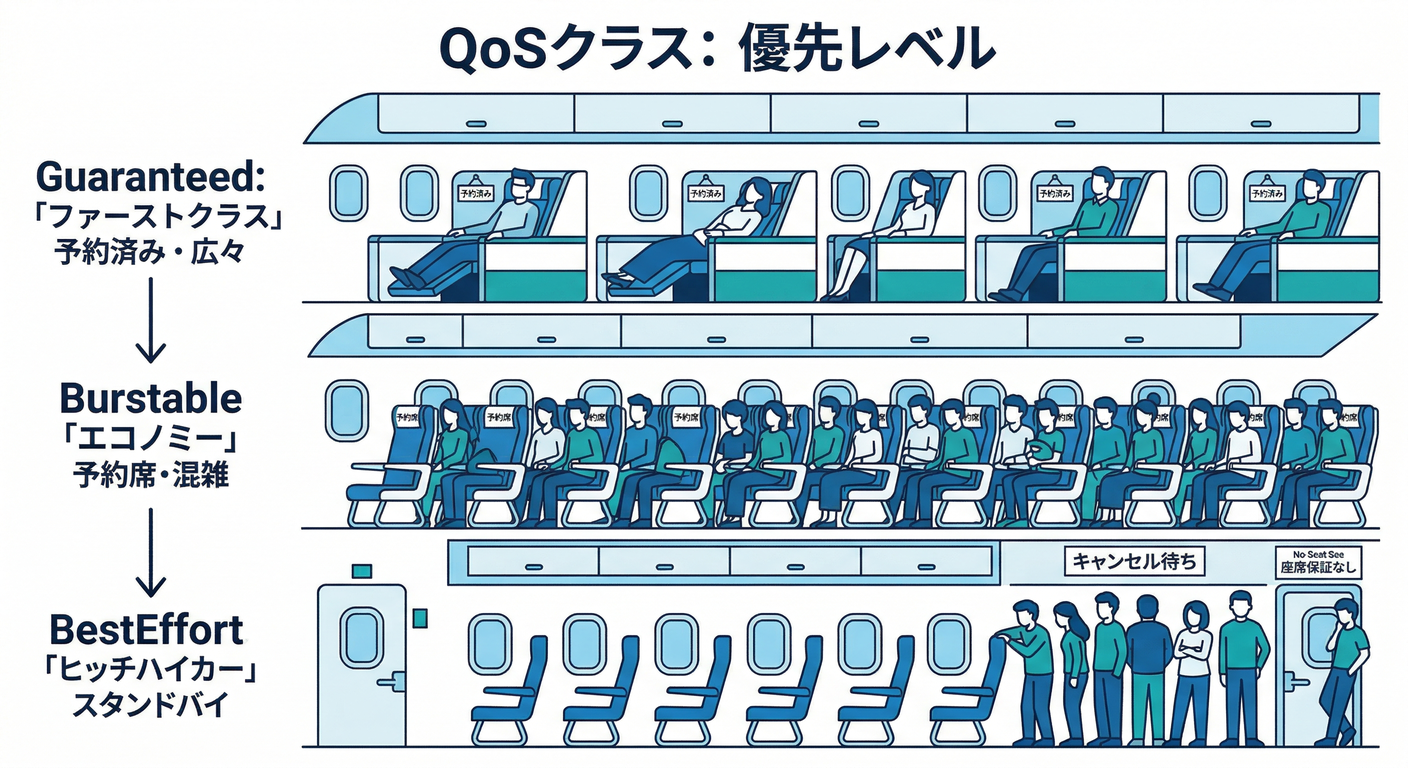
requests/limits の書き方で、Podは QoSクラスに分類されます:
- BestEffort:何も指定しない(超弱い)🫥
- Burstable:request と limit を入れる(一般的)💪
- Guaranteed:CPU/メモリともに「request = limit」(最強)🛡️
このQoSは、ノードが苦しくなったとき(メモリ不足など)に、どれが先に追い出されやすいかにも関係します。(Kubernetes)
ハンズオン:Requests/Limits を“体で覚える”🧪🔥
以下は **「手元クラスタ」**で安全に壊せる実験です😈➡️😇
(kubectl top を使うので、メトリクスが必要です)
0) kubectl top を使えるようにする📊
kubectl top は Metrics Server が必要です。(Kubernetes)
minikube の場合(いちばん楽)👇
minikube addons enable metrics-server
この手順は公式チュートリアルにも載っています。(Kubernetes)
kind の場合(まずは素直に最新マニフェスト)👇
kubectl apply -f https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/components.yaml
(Metrics Server 側の案内に沿った形です)(GitHub)
動作確認👇
kubectl top nodes
kubectl top pods
1) まず “Burstable の基本形” を作る🧩
名前空間を作って、実験用に隔離します🧼
kubectl create namespace res-lab
次の Deployment を res-cpu.yaml として保存して apply👇
(Nodeは Active LTS の v24 を例にします)(Node.js)
apiVersion: apps/v1
kind: Deployment
metadata:
name: cpu-demo
namespace: res-lab
spec:
replicas: 1
selector:
matchLabels:
app: cpu-demo
template:
metadata:
labels:
app: cpu-demo
spec:
containers:
- name: app
image: node:24-alpine
command: ["sh", "-lc"]
args:
- |
node -e '
// CPUを使い続ける(わざと)
function burn(ms){
const end = Date.now() + ms;
while (Date.now() < end) {}
}
setInterval(()=>burn(200), 0);
console.log("cpu burn started");
setInterval(()=>console.log("alive", new Date().toISOString()), 2000);
'
resources:
requests:
cpu: "100m"
memory: "64Mi"
limits:
cpu: "200m"
memory: "128Mi"
適用👇
kubectl apply -f res-cpu.yaml
kubectl get pods -n res-lab -w
観察👇
kubectl top pods -n res-lab
kubectl describe pod -n res-lab -l app=cpu-demo
kubectl logs -n res-lab -l app=cpu-demo --tail=50
✅ ここで見たいこと
topの CPU が 200m 付近で頭打ちになる(=絞られてる)🐢- Pod は生きてる(落ちない)けど、余裕がないと遅くなるタイプの危険を感じる
CPU limit の「上限はカーネルにより絞られる」という性質は公式ドキュメントにも説明があります。(Kubernetes)
2) “request 高すぎ”で Pending を作ってみる🧊

次は「置き場所がない」を体験します。
同じファイルで、requests だけ極端に上げた版を作って apply(例:2000m)👇
resources:
requests:
cpu: "2000m"
memory: "64Mi"
limits:
cpu: "2000m"
memory: "128Mi"
確認👇
kubectl apply -f res-cpu.yaml
kubectl get pods -n res-lab
kubectl describe pod -n res-lab -l app=cpu-demo
✅ ここで見たいこと
- Pod が Pending のまま
describeに Insufficient cpu みたいな理由が出る(=スケジューラが置けない)
3) “メモリ limit 低すぎ”で OOMKilled を起こす💀🧨
res-mem.yaml を作ります👇(増え続けるメモリ確保)
apiVersion: apps/v1
kind: Deployment
metadata:
name: mem-demo
namespace: res-lab
spec:
replicas: 1
selector:
matchLabels:
app: mem-demo
template:
metadata:
labels:
app: mem-demo
spec:
containers:
- name: app
image: node:24-alpine
command: ["sh", "-lc"]
args:
- |
node -e '
const keep = [];
let i = 0;
setInterval(()=>{
keep.push(Buffer.alloc(10 * 1024 * 1024)); // 10MiBずつ増やす
i++;
console.log("allocated", i * 10, "MiB");
}, 500);
'
resources:
requests:
memory: "32Mi"
cpu: "50m"
limits:
memory: "64Mi"
cpu: "200m"
実行👇
kubectl apply -f res-mem.yaml
kubectl get pods -n res-lab -w
落ちた理由を掘る👇
kubectl describe pod -n res-lab -l app=mem-demo
kubectl logs -n res-lab -l app=mem-demo --previous --tail=50
✅ ここで見たいこと
describeに Reason: OOMKilled が出る- 再起動回数(Restart Count)が増える
- 「メモリ limit は OOM kill で守られる」体感💀
この挙動(メモリはOOM killで制限され、即時ではなく“圧”で反応することがある)は公式に説明があります。(Kubernetes)
よくある “おすすめ設定パターン” 3つ🍱
パターンA:まずは Burstable(いちばん普通)🙂
- request = 普段の使用量っぽい値
- limit = その 1.5〜3倍(メモリは“守り”として必須感強め)
パターンB:Guaranteed(安定が最優先)🛡️
- CPU/メモリとも request = limit
- その代わり「席取りが重い」=置けない可能性は増える
パターンC:CPU limit は慎重に(遅さが怖い系)🐢⚠️
- CPU limit が低いと 遅いのに落ちないでハマりがち
- まずは「request を入れて守る」→必要なら limit を入れる、でもOK
ちょい先取り:最近は“動かしたまま調整”も安定版🛠️✨
Kubernetes v1.35 では Podを作り直さずに CPU/メモリの request/limit を変更する仕組みが stable 扱いになっています。(Kubernetes) ただし注意点も多く、例えば QoSクラスは作成時に決まり、後からは変えられません。(Kubernetes)
(しかも Windows の Pod は in-place resize 非対応、など制約もあります)(Kubernetes)
AIで楽するポイント🤖🧠✨
- 「このDeploymentの request/limit 妥当?理由もセットでレビューして」🧑⚖️
- 「OOMKilled が出た。次に見るべきコマンドを3つ、優先順で」🧯
kubectl describeの結果を貼って「原因候補と確認手順」を作らせる🔍
お片付け🧹✨
kubectl delete namespace res-lab
次の章(第16章:スケジューリング基礎)に進むと、ここで出てきた request が **「どのノードに置かれるか」**に直結して、さらに面白くなります🧲🎯