第19章:失敗時のリトライ・DLQっぽい考え方🧯🔁
この章はひとことで言うと、**「落ちても、ちゃんと立ち直れる開発スタック」**を作る回です💪✨ Queueって、導入した瞬間から「失敗」が日常になるので、失敗を“仕様”として設計しちゃいましょう😎🧠
1) 今日のゴール🎯✨
- 失敗を 「リトライすべき失敗」 と 「リトライしない失敗」 に分けられる🧠✅
- リトライの基本(回数・間隔・増え方)を設定できる🔁⏱️
- DLQっぽい避難場所を用意して、「毒ジョブ」で全体が詰まるのを防ぐ🧪🚫
- 「無限リトライ地獄」になりがちな落とし穴を回避できる🕳️😱➡️🛟
2) まず“失敗”を2種類に分けよう🧠🔍
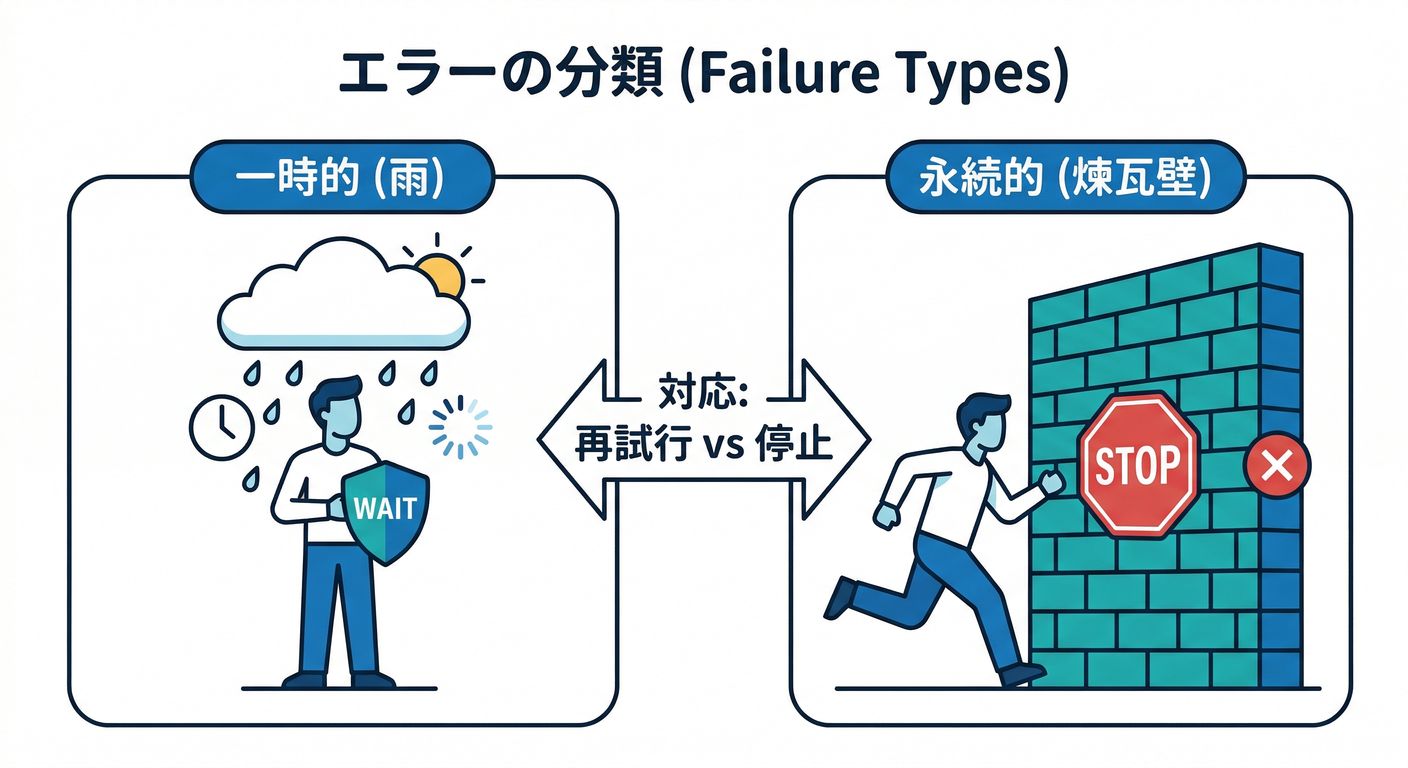
A. リトライすべき失敗(だいたい一時的)🌧️➡️☀️
例:
- 外部APIが一時的に落ちてる / タイムアウトした🌐💥
- 一時的なネットワーク不調📡😵
- レート制限(429)で「少し待て」が来た⏳🚦
✅ 時間が解決する可能性が高い → リトライ向き
B. リトライしない失敗(だいたい恒久的)🧱💀
例:
- 入力データが壊れてる / 必須項目が欠けてる🧾❌
- 仕様的に絶対成功しない(宛先メールが無効など)📭😵
- 認証情報が間違ってる(直すまで永遠に失敗)🔑🙅♂️
✅ 時間では解決しない → すぐ避難(DLQっぽい場所)へ
3) リトライ設計の基本セット🔁⏱️📈
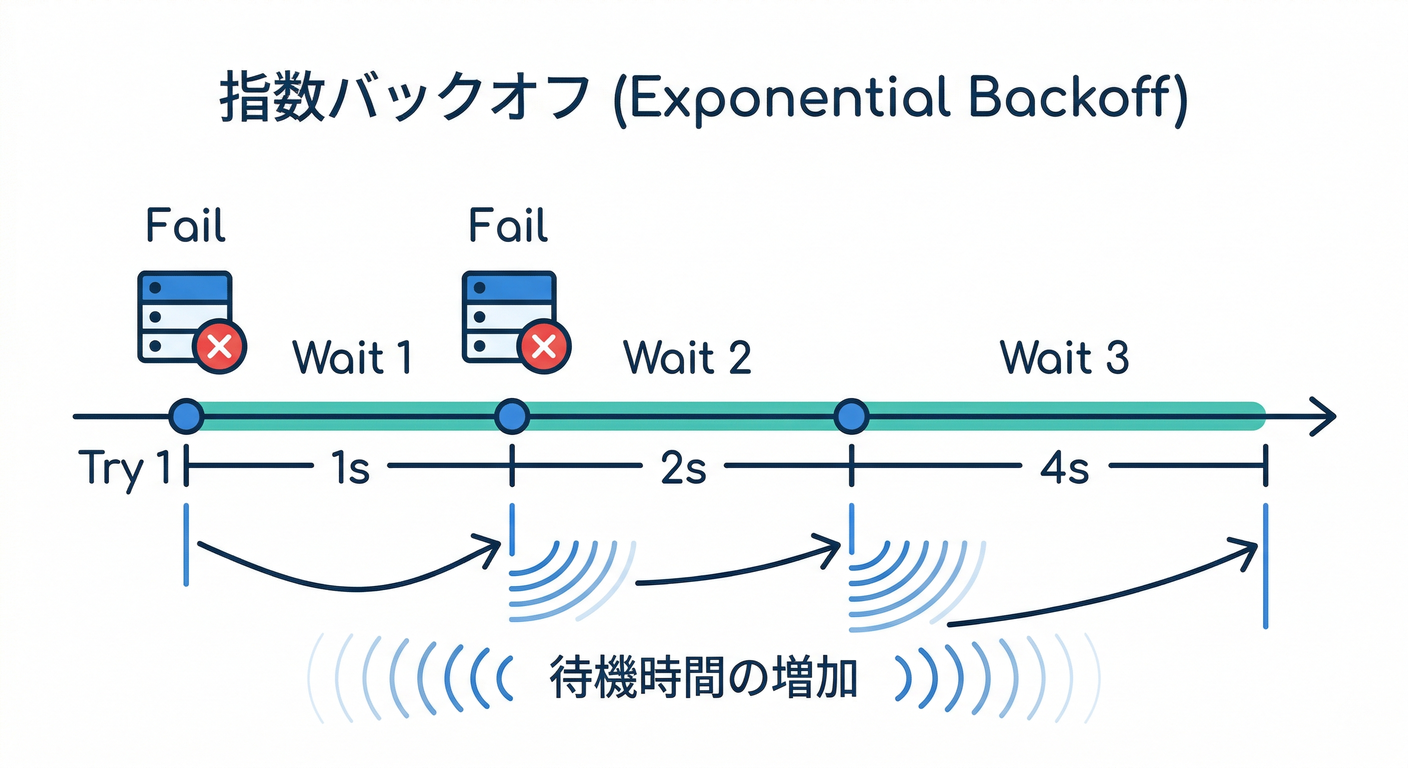
BullMQでは「attempts(試行回数)」を2以上にすると自動リトライが有効になります🔁✨ (docs.bullmq.io)
最小のおすすめ(まずはこれでOK)👍
- attempts:5回(多すぎない)
- backoff:**exponential(指数)**で伸ばす📈
- delay:1000msスタート(1秒)
「指数バックオフ」は、失敗が続くほど待ち時間が増えるので、外部APIに優しいです🙏🌐
4) BullMQで“リトライ”を入れる(追加する側)📮🟥
例:ジョブ追加時にリトライ設定を付ける
import { Queue } from "bullmq";
import { connection } from "./redis-connection";
const emailQueue = new Queue("email", { connection });
export async function enqueueSendEmail(payload: { to: string; subject: string; body: string }) {
await emailQueue.add(
"sendEmail",
payload,
{
attempts: 5, // 2以上で自動リトライ有効
backoff: { type: "exponential", delay: 1000 }, // 1s, 2s, 4s...みたいに増える
removeOnComplete: { count: 1000 }, // 完了ジョブは最新1000件だけ残す(デバッグ用)
removeOnFail: { count: 2000 }, // 失敗ジョブも残しすぎない(でも少し多めに)
}
);
}
- 自動リトライの基本は attempts + backoff です🔁⏳ (docs.bullmq.io)
- removeOnComplete / removeOnFail は「ジョブを残しすぎてRedisがパンパン」事故を防ぎます💾🧯 keepの考え方(age / count)も公式に説明があります📚 (docs.bullmq.io)
5) 「無限リトライ地獄😱」を止める3つの方法🛑🔁

① attempts を“有限”にする(最重要)🔢✅
attemptsを入れない・変な値にすると、挙動が読みにくくなります。 「最大何回まで粘るか」を必ず決めるのが大事です✍️
② “恒久的な失敗”は即終了(UnrecoverableError)🧨🚪
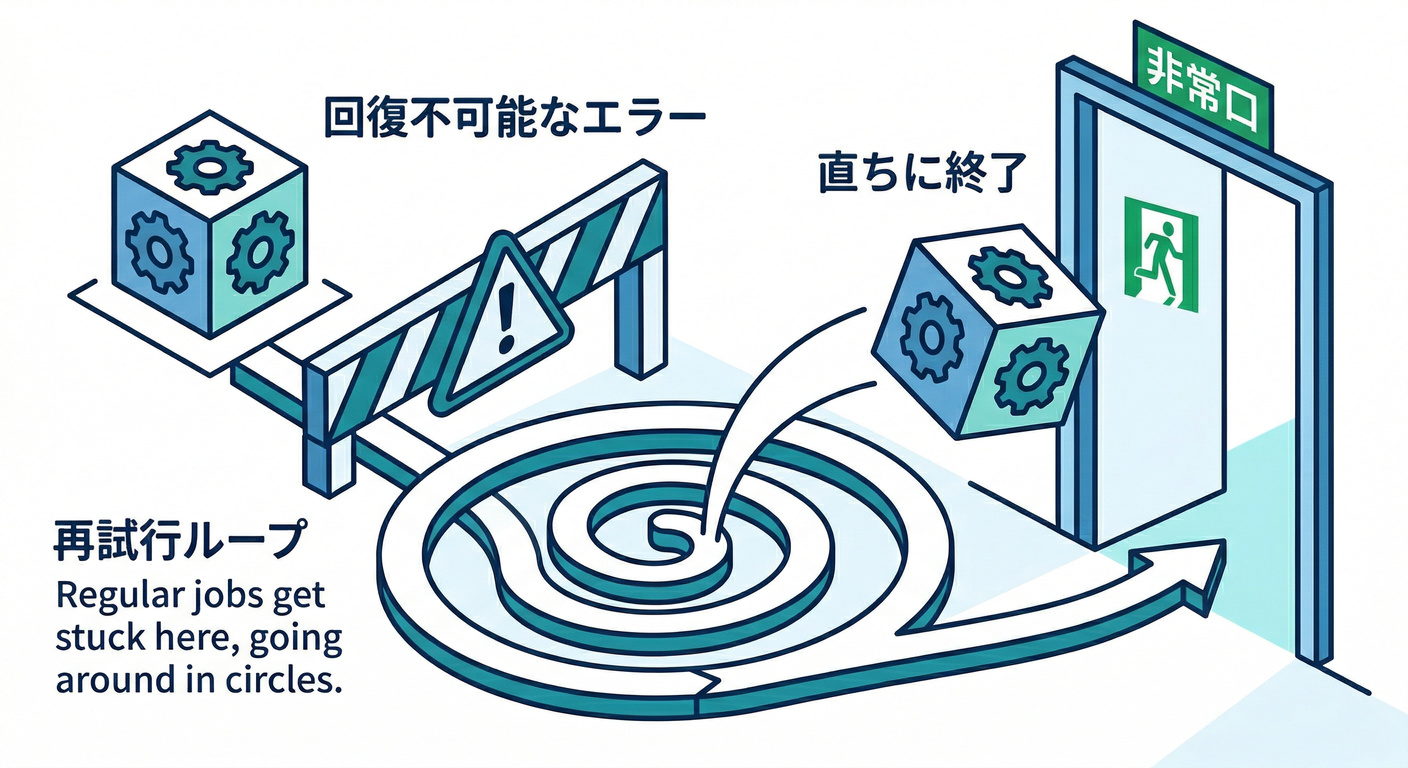
BullMQには「これはもう無理!」を明示できる仕組みがあります。 UnrecoverableError を投げると attempts設定を無視して即Failed になります🧠✨ (docs.bullmq.io)
import { Worker, UnrecoverableError } from "bullmq";
import { connection } from "./redis-connection";
function isPermanentError(err: unknown) {
// 例:入力バリデーション、404/400系など(プロジェクト都合で調整してOK)
return err instanceof Error && /VALIDATION|BAD_REQUEST|NOT_FOUND/.test(err.message);
}
const worker = new Worker(
"email",
async (job) => {
try {
// ここでメール送信など
// await sendEmail(job.data)
return { ok: true };
} catch (err) {
if (isPermanentError(err)) {
// 即Failed(もうリトライしない)
throw new UnrecoverableError(`Permanent failure: ${String((err as any)?.message ?? err)}`);
}
// 一時的失敗は通常の例外 → attempts/backoffに従ってリトライ
throw err;
}
},
{ connection }
);
これがあるだけで「壊れたデータが永遠に回り続ける」問題が激減します🛟✨
③ “Workerが落ちた/固まった”系(stalled)もケアする🧊🧯
たとえば処理中にWorkerがクラッシュすると、ジョブが「処理中のまま」になりがちです。 BullMQはこれを stalled job として検知して復旧しようとします🩺 (docs.bullmq.io)
- maxStalledCount(スタック回数の上限)を小さくすると、変なジョブを早めにFailedへ送れます🧯
- stalledの根本原因は「処理が長すぎる」「外部API待ちで固まる」などが多いです😵💫
6) DLQっぽい考え方:避難所を作る🏥📦
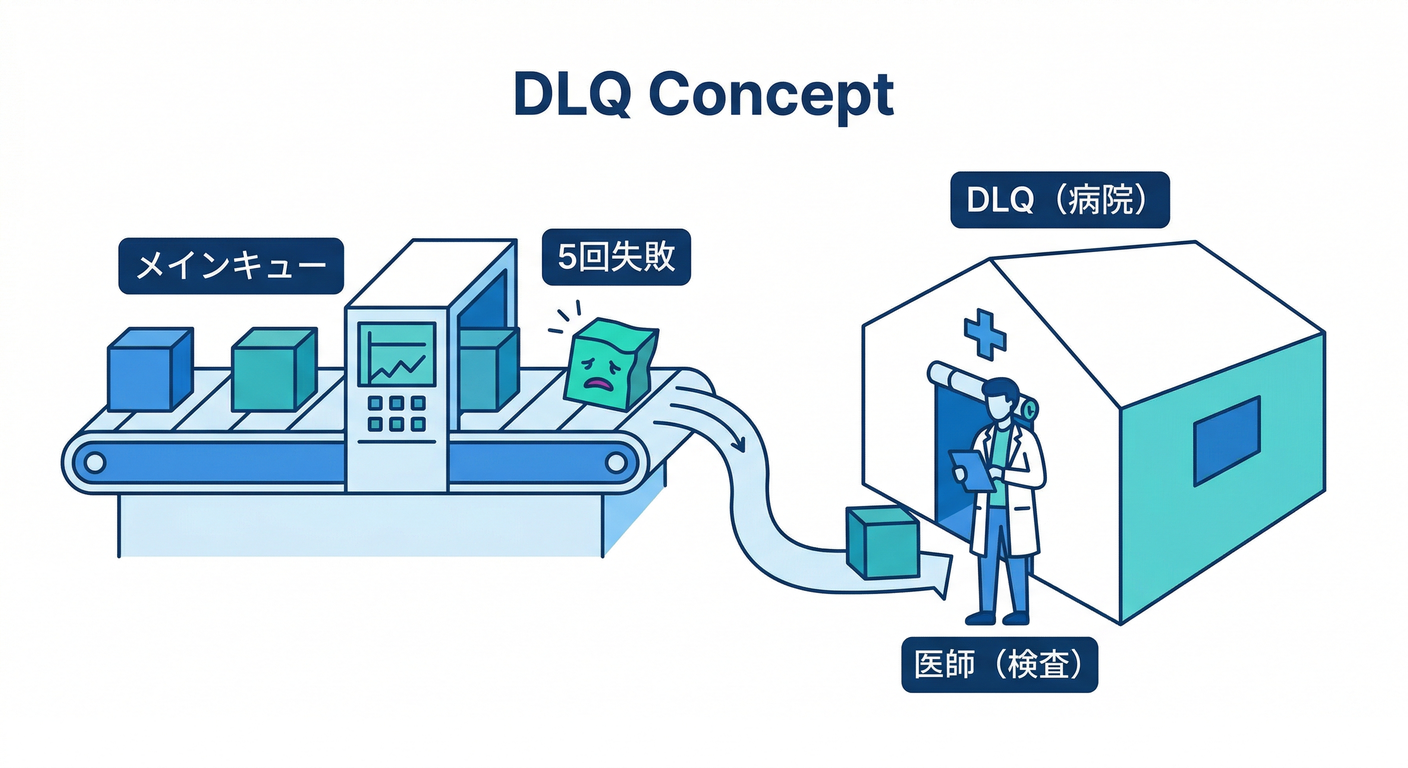
「DLQ(Dead Letter Queue)」は、ざっくり言うと **“何回やってもダメなジョブを隔離して、あとで人間が診断する場所”**です🧪🧑⚕️
BullMQには標準で「failed set」があり、attemptsを使うと最終的にFailedへ落ちます(= それ自体がDLQっぽい)という発想ができます🟥🧠 (api.docs.bullmq.io)
ただ、開発が進むとこう思い始めます👇 「Failedの中でも、“本当にヤバいやつ”だけ別に集めたい…!」😇
そこで “DLQ専用Queue” を作るのが分かりやすいです📦✨
7) DLQ専用Queueを作る(実装パターン)🧱🧪
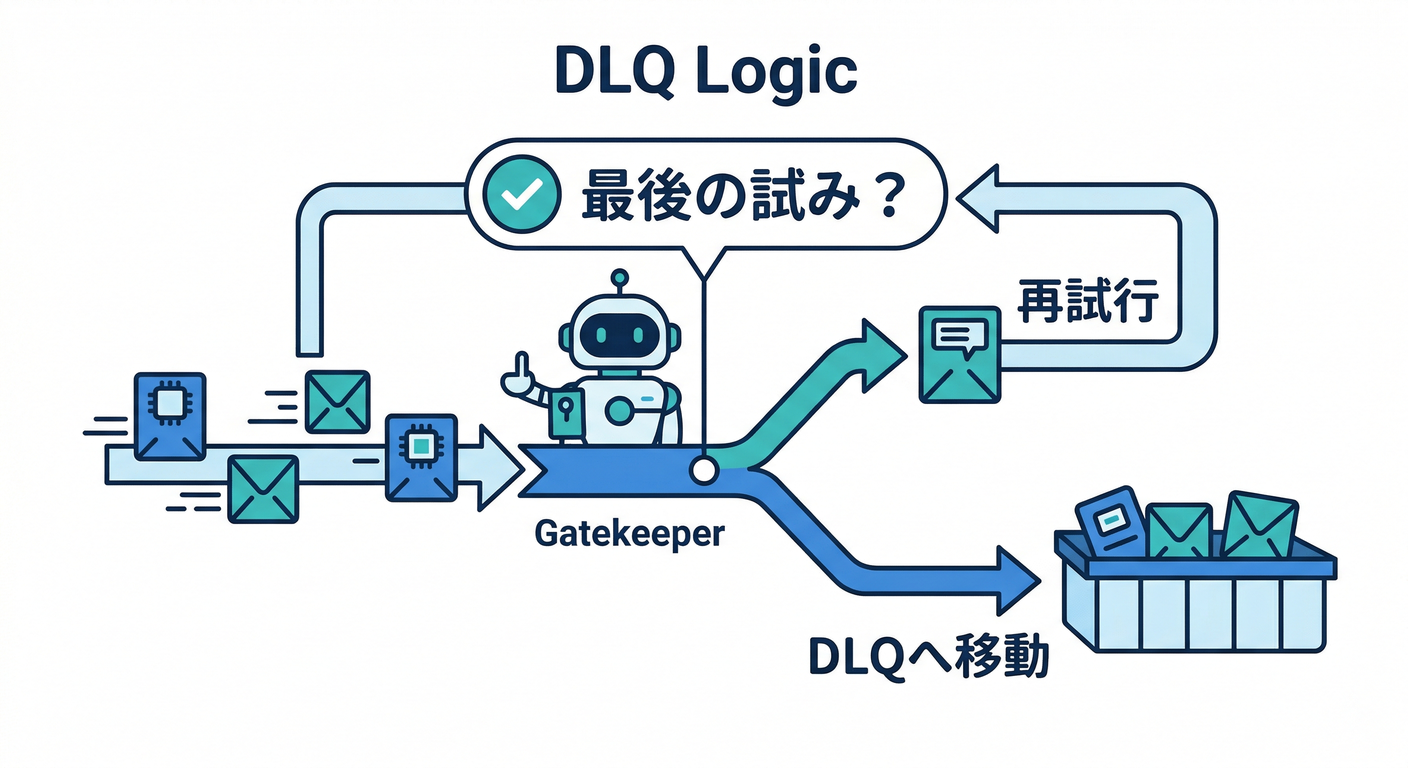
パターン:失敗が“最終確定”したらDLQへコピー📋➡️📦
ポイントはこれ👇
- 「失敗した瞬間」ではなく、**attemptsを使い切った“最後の失敗”**だけ拾う🔁🛑
- DLQに入れるデータは「再調査に必要な最小限」にする(巨大payload丸ごとは避けたい)📦⚖️
import { Queue, Worker, UnrecoverableError } from "bullmq";
import { connection } from "./redis-connection";
const mainQueueName = "email";
const dlqQueueName = "email-dlq";
const dlq = new Queue(dlqQueueName, { connection });
function isFinalFailure(job: any) {
const attempts = job?.opts?.attempts ?? 0;
const attemptsMade = job?.attemptsMade ?? 0;
// BullMQのattemptsは「最大試行回数」。使い切ったら最終失敗扱いにする
return attempts > 0 && attemptsMade >= attempts;
}
const worker = new Worker(
mainQueueName,
async (job) => {
// ここは普通に処理
// await sendEmail(job.data)
return { ok: true };
},
{ connection }
);
// 失敗イベント(試行の途中でも来る可能性があるので“最終失敗だけ”を判定する)
worker.on("failed", async (job, err) => {
if (!job) return;
// UnrecoverableError(恒久的失敗)も最終扱いにしたいことが多い
const unrecoverable = err instanceof UnrecoverableError;
if (unrecoverable || isFinalFailure(job)) {
await dlq.add("dead", {
originalQueue: mainQueueName,
originalJobId: job.id,
name: job.name,
data: job.data, // 本当に必要なら。重いなら「参照IDだけ」にするのも手👍
attemptsMade: job.attemptsMade,
failedReason: job.failedReason ?? String(err),
failedAt: Date.now(),
}, {
removeOnComplete: { count: 2000 },
removeOnFail: { count: 2000 },
});
}
});
💡補足: 中央監視っぽく「どのWorkerでも全部拾う」形にしたいなら QueueEvents が便利です。QueueEventsはRedis Streamsベースで、切断時にイベントが落ちにくい性質がある、と公式が説明しています📡🧠 (docs.bullmq.io)
8) DLQからの“再実行(リドライブ)”の考え方🔄🧑🔧
DLQに入ったジョブは、だいたいこのどれかです👇
- データが壊れてる🧾❌
- 外部APIの仕様変更などで落ちてる🌐🔧
- バグ🐛💥
だから 「とりあえず全部再実行!」は危険です⚠️😇 おすすめはこの流れ👇
- 失敗理由を見て原因を直す🔍🛠️
- 直ったものだけ再投入する🔄✅
- 再投入時は「二重実行」事故を防ぐ(次の節)🛡️✨
9) リトライするなら“冪等(idempotent)”が超重要🧠🛡️
リトライって、裏を返すと「同じ処理が複数回走る」可能性があります🔁😅 だからジョブは「複数回やっても最終結果が同じ」ように作るのが基本です(公式も“失敗前提で設計しよう”と説明)🧠✨ (docs.bullmq.io)
ありがちな事故:メール二重送信📧📧😇
対策アイデア(わかりやすい順)👇
- 送信済みフラグをDBに持つ✅
- 外部APIにidempotency keyを渡す🔑
- BullMQの jobId / dedup を使う(重複投入を防ぐ)🆔🚫 (docs.bullmq.io)
10) Compose側の「プロセスが落ちたら復帰」も入れておく🐳🛟
ここは勘違いポイントなのですが…
- BullMQのリトライ:ジョブが失敗したときの再試行🔁
- Composeのrestart:コンテナ(プロセス)が落ちたときの自動復帰🔄
両方いることが多いです😄 Dockerのrestartポリシーは公式にまとまっています📚 (Docker Documentation)
例(workerだけ復帰を強める):
services:
worker:
restart: unless-stopped
11) AI(Copilot等)に手伝わせるコツ🤖🧠✨
AIに投げるときは、**「一時的失敗/恒久的失敗の基準」**を先に書くと精度が上がります📈
たとえばこんな指示が効きます👇
BullMQで attempts=5, exponential backoff を入れたい。
さらに「400系は即UnrecoverableError」「429/timeoutはリトライ」。
最終失敗だけDLQ用Queueに送るコード例をTypeScriptで。
⚠️ただしAIは、たまに「失敗ごとにDLQへ入れる」みたいな事故設計も出します😇 **“最終失敗だけ”**のチェックは人間が必ず見てください🙏✨
12) ミニ演習(手を動かすと強い)🧪🔥
演習1:一時的失敗をわざと作る🌧️
- Worker内でランダムにエラーを投げる(例:30%失敗)
- backoffで待ちが伸びるのを logs で確認🧾👀
演習2:恒久的失敗を即終了させる🧱
- payloadに「不正メール」を混ぜる
- UnrecoverableError で即Failedになるのを確認🧨✅
演習3:DLQに入ったジョブだけ一覧表示📦🔍
- DLQ queue の件数を表示する小スクリプトを書く
- 「failedReason を見て分類」までできたら勝ち🏆✨
13) この章の“持ち帰りチェックリスト”✅🧠
- 失敗を「一時的/恒久的」に分けた
- attempts と backoff を入れた(attemptsは有限)
- 恒久的失敗は UnrecoverableError で止めた (docs.bullmq.io)
- DLQっぽい避難先を用意した(failed set or 専用Queue)
- 冪等性(同じジョブが複数回走る前提)を意識した (docs.bullmq.io)
- Composeのrestartでプロセス復旧も押さえた (Docker Documentation)
ちょい補足:今どきのNode安定運用メモ🧊🟢
本章のテーマ的に「安定版を固定する」は相性が良いです。 Nodeは本日時点で v24がActive LTS、v25がCurrent になっています(公式のリリース表)📌 (nodejs.org)
次の第20章(profiles)では、DLQの中身を“管理UIだけ必要なときに起動”みたいにして、さらに運用っぽくできます🎛️✨